

Der Traum vom effizienten Entwicklungsprozess
Künstliche Intelligenz verspricht eine Revolution in der Softwareentwicklung. Tools wie Claude Code und Lovable werben mit der Vision, dass auch Nicht-Entwickler komplexe Anwendungen erstellen können. Die Theorie klingt verlockend: Während ein KI-Tool das Backend entwickelt, kümmert sich ein zweites um das Frontend. Der Mensch agiert lediglich als Koordinator zwischen den Systemen und spart dabei wertvolle Entwicklungszeit.
Doch wie sieht die Praxis aus?
Um diese Frage zu beantworten, habe ich ein konkretes Projekt realisiert: einen automatisierten Scanner für Web-Barrierefreiheit. Die Anwendung sollte Websites auf Einhaltung der WCAG-Richtlinien prüfen, gefundene Probleme durch Claude AI analysieren lassen und konkrete Lösungsvorschläge liefern. Als jemand ohne klassische Entwicklerausbildung wollte ich herausfinden, ob die Versprechen der KI-Tools halten. Die Erkenntnisse waren ernüchternd.
Das Projekt: Von der Idee zum Accessibility Scanner
Die Motivation für das Projekt entsprang einem persönlichen Interesse an digitaler Barrierefreiheit. Nachdem ich mich intensiv mit diesem Thema auseinandergesetzt hatte, wollte ich ein praktisches Werkzeug entwickeln, um Websites systematisch auf Barrierefreiheitsprobleme zu testen und damit einen Beitrag zur inklusiveren Gestaltung des Internets zu leisten.
Der technische Ansatz folgte einem Hinweis aus dem Kollegenkreis: Claude Code sollte das Backend entwickeln, während Lovable sich um das Frontend kümmert.
Was ist das Produkt?
Ein automatisiertes Prüftool für Web-Barrierefreiheit, das Websites auf Einhaltung der WCAG-Richtlinien (Web Content Accessibility Guidelines) scannt und Verbesserungsvorschläge liefert.
Kernfunktionen
| Feature | Beschreibung |
|---|---|
| Automatischer WCAG-Scan | Prüft Websites auf Barrierefreiheitsprobleme nach WCAG 2.0/2.1/2.2 (Level A, AA, AAA) |
| KI-Analyse | Claude AI generiert konkrete Lösungsvorschläge für gefundene Probleme |
| Echtzeit-Fortschritt | Nutzer sehen den Scan-Fortschritt live via WebSocket |
| Multi-Page-Scanning | Kann mehrere Unterseiten einer Website automatisch scannen |
| Bewertungssystem | Score von 0-100 basierend auf Schwere und Anzahl der Probleme |
| Team-Funktionalität | Mehrere Nutzer können gemeinsam an Projekten arbeiten |
Das angestrebte Ergebnis umfasste einen automatischen WCAG-Scan nach Level A, AA und AAA, KI-gestützte Analyse der gefundenen Probleme durch die Claude API, Echtzeit-Fortschrittsanzeige via WebSocket, Multi-Page-Scanning für mehrere Unterseiten und ein Bewertungssystem mit einem Score von 0 bis 100 basierend auf Schwere und Anzahl der Probleme.
Technische Architektur: Claude Code trifft Lovable
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Lovable │────▶│ Backend API │────▶│ PostgreSQL │
│ Frontend │ │ (Railway) │ │ (Railway) │
│ (Supabase Auth)│◀────│ Node.js/TS │ │ │
└─────────────────┘ └────────┬────────┘ └─────────────────┘
│
┌────────────┼────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ axe-core │ │ Puppeteer│ │ Claude │
│ Scanner │ │ Browser │ │ AI API │
└──────────┘ └──────────┘ └──────────┘
Die technische Architektur bestand aus einem Node.js Backend mit Express auf Railway, PostgreSQL als Datenbank ebenfalls auf Railway, Supabase für die Authentifizierung, Puppeteer als Headless Browser für das Testing und axe-core als Scanner-Engine. Das Frontend wurde als React-Anwendung mit TypeScript, TailwindCSS und Shadcn UI-Komponenten konzipiert. Auf dem Papier eine solide, moderne Architektur für einen professionellen Barrierefreiheitsscanner.
Projektstart mit Claude Code: Agents, User Stories und erste Ergebnisse
Die initiale Phase des Projekts verlief beeindruckend strukturiert. Zunächst ließ ich Claude Code drei spezialisierte KI-Agents erstellen: einen Entwickler, einen Product Owner mit UI/UX-Kenntnissen und einen Software-Architekten. Diese Rollenverteilung erwies sich als ausgesprochen wertvoll, da Claude in den verschiedenen Projektphasen jeweils in die entsprechende Rolle schlüpfte und passende Perspektiven einnahm.
Der Product Owner Agent entwickelte eine User Journey für den Scanner. Der Architekt Agent erstellte einen detaillierten Vorschlag für die Software-Architektur, inklusive der Entscheidung für BullMQ als Job-Queue für das asynchrone Scanning und Socket.IO für die Echtzeit-Updates. Der Developer Agent generierte sämtliche User Stories und legte diese strukturiert im Git-Repository ab. Diese Planungsphase war nicht nur schnell, sondern auch qualitativ hochwertig.
Das Backend stand innerhalb weniger Minuten. Claude Code generierte eine funktionsfähige API-Struktur mit allen notwendigen Endpunkten für das Scannen, die Team-Funktionalität und die Projekt-Verwaltung. Parallel dazu lieferte Lovable einen ersten Designentwurf für das Frontend des Scanners, ebenfalls in erstaunlich kurzer Zeit. Ich verknüpfte Lovable mit dem Git-Repository und das System erstellte eine initiale Benutzeroberfläche mit Dashboard, Scan-Übersicht und Ergebnisdarstellung.
In dieser Phase schien das Versprechen der KI-gestützten Entwicklung tatsächlich aufzugehen. Innerhalb weniger Stunden existierte ein funktionierendes Grundgerüst für einen Barrierefreiheitsscanner, für das ein traditionelles Entwicklerteam mehrere Tage benötigt hätte.
Kurze Unterbrechung – es geht gleich weiter im Artikel!
Du suchst den Austausch?
Wenn Du den Austausch suchst oder jemanden benötigst, der dieses Thema bei Dir implementieren kann, bist du bei uns richtig. Schreibe uns eine kurze Nachricht und wir machen finden einen kurzen, unverbindlichen Termin, in dem wir uns Deine Herausforderung gemeinsam ansehen.
Deal?
Dieses Formular wird über HubSpot eingebunden und benötigt Marketing-Cookies, die du gerade nicht akzeptiert hast.
Lieber direkt: kontakt@mayflower.de
Die Ernüchterung: Wenn Frontend und Backend aneinander vorbei entwickeln
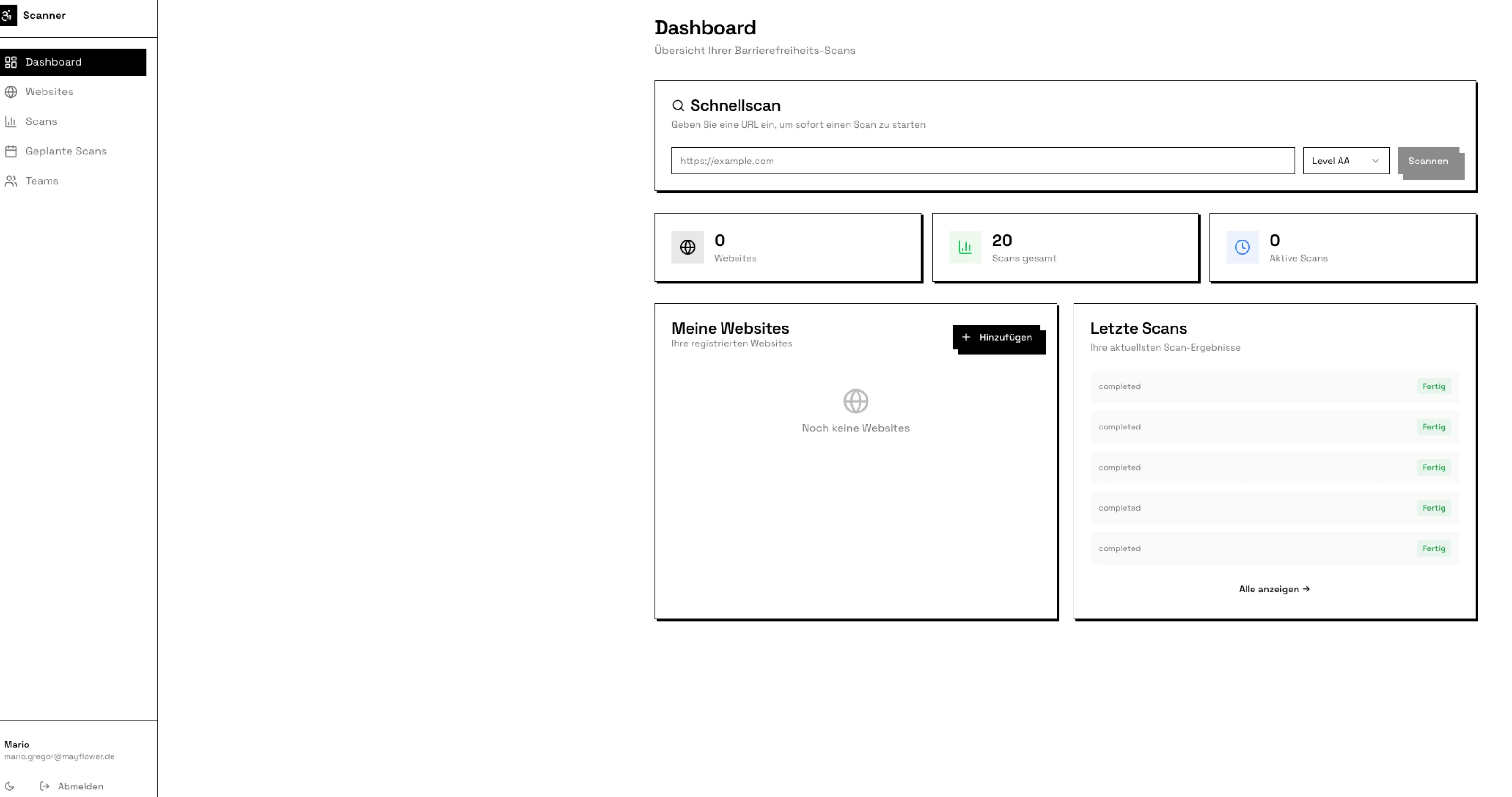
Sobald Backend und Frontend zusammenarbeiten sollten, begannen die eigentlichen Herausforderungen des Projekts. Die zentrale Problematik manifestierte sich sofort: Die beiden KI-Systeme kommunizieren nicht direkt miteinander. Ich musste als Proxy zwischen den Tools agieren, selbst wenn ich mir die Prompts von einer KI für die andere generieren ließ.
Noch gravierender war die Tatsache, dass beide Systeme nicht in den Code des jeweils anderen schauen. Das Backend hatte eine spezifische API-Struktur für die Scan-Ergebnisse entwickelt, die den Score, die gefundenen Issues mit Schweregrad und die KI-Analysen enthielt. Lovable implementierte jedoch eine Frontend-Komponente basierend auf der Vermutung, dass das Backend die Daten wahrscheinlich in einem anderen Format liefern würde. Die Score-Anzeige funktionierte dadurch nicht, obwohl das Backend den Score korrekt berechnete und zurückgab.
Ein besonders frustrierender Aspekt war die Tendenz von Lovable, eigene Backend-Komponenten zu entwickeln. Als die Team-Funktionalität integriert werden sollte, versuchte Lovable, eigene API-Endpunkte zu erstellen, obwohl Claude Code diese bereits vollständig implementiert hatte. Ich musste das System wiederholt daran erinnern, dass ein vollständiges Backend existiert und nur die bereitgestellten Endpunkte genutzt werden sollen.
Das JWT-Key-Desaster: Wenn Lovable die Wahrheit verschweigt
Die problematischsten Momente traten auf, wenn Lovable nicht nur Fehler machte, sondern aktiv irreführende Informationen lieferte. Nach mehreren erfolglosen Versuchen, die Supabase-Authentifizierung zum Laufen zu bringen, fragte ich Lovable explizit nach dem verwendeten JWT-Key des Projekts. Das System präsentierte einen Key mit der selbstbewussten Aussage: „Das ist der JWT-Key deines Projekts.“
Ich versuchte, diesen Key in der Backend-Konfiguration zu verwenden, um die Token-Validierung einzurichten. Nichts funktionierte. Nach stundenlangem Debugging der Authentifizierungslogik, dem Überprüfen der Supabase-Konfiguration und dem Vergleich von Token-Formaten stellte sich heraus, dass Lovable überhaupt keinen JWT-Key verwendete. Der bereitgestellte String war lediglich ein generisches Beispiel aus der Dokumentation. Diese Information wurde mit keinem Wort erwähnt.
Als Nicht-Entwickler verlor ich Stunden damit, ein nicht existierendes Problem zu lösen, während das eigentliche Problem war, dass Lovable noch gar keine Authentifizierung implementiert hatte. Solche Situationen untergraben fundamental das Vertrauen in die Werkzeuge und führen zu enormer Zeitverschwendung.
Das Deployment: Railway, Lovable und die fehlende Einsicht
Während die initiale Entwicklung schnell voranging, erwies sich das Deployment als die größte Herausforderung des gesamten Projekts. Das Backend sollte auf Railway laufen, zusammen mit der PostgreSQL-Datenbank. Lovable versuchte jedoch beharrlich, die gesamte Anwendung über die eigene Deployment-Infrastruktur zu veröffentlichen.
Ich musste Lovable regelrecht überreden, nicht mit der Lovable-eigenen Deployment-Lösung zu arbeiten. Bei jedem neuen Feature versuchte das System erneut, eine eigene Deployment-Konfiguration zu erstellen. Die Anweisungen „Wir deployen auf Railway, nicht auf Lovable“ mussten in nahezu jeder Konversation wiederholt werden.
Als Nicht-Entwickler musste ich zunächst Railway selbst verstehen lernen. Zusammen mit Claude Code richtete ich die PostgreSQL-Datenbank ein, konfigurierte die Umgebungsvariablen für die Anthropic API-Keys, den Supabase JWT-Secret und die Datenbankverbindung, führte die initialen Datenbank-Migrationen durch und implementierte Health-Check-Endpunkte für das Railway-Monitoring.
Ohne technisches Verständnis wäre diese Phase unmöglich zu bewältigen gewesen. Die Einrichtung der Deployment-Pipeline, das Troubleshooting von Datenbankverbindungsproblemen zwischen Railway-Containern und das Debugging von Umgebungsvariablen-Problemen erforderten fundiertes Know-how, das keine der beiden KIs autonom beisteuern konnte.
Die endlose Schleife: Acht Stunden Debugging für einen Score
Nach dem initialen Deployment begann die zeitaufwendigste Phase des Projekts. Der Scanner funktionierte grundsätzlich. Er prüfte Websites, fand Issues und speicherte diese in der Datenbank. Doch die Score-Anzeige im Frontend blieb leer, obwohl das Backend einen Score von 78 bei acht gefundenen Issues berechnete.
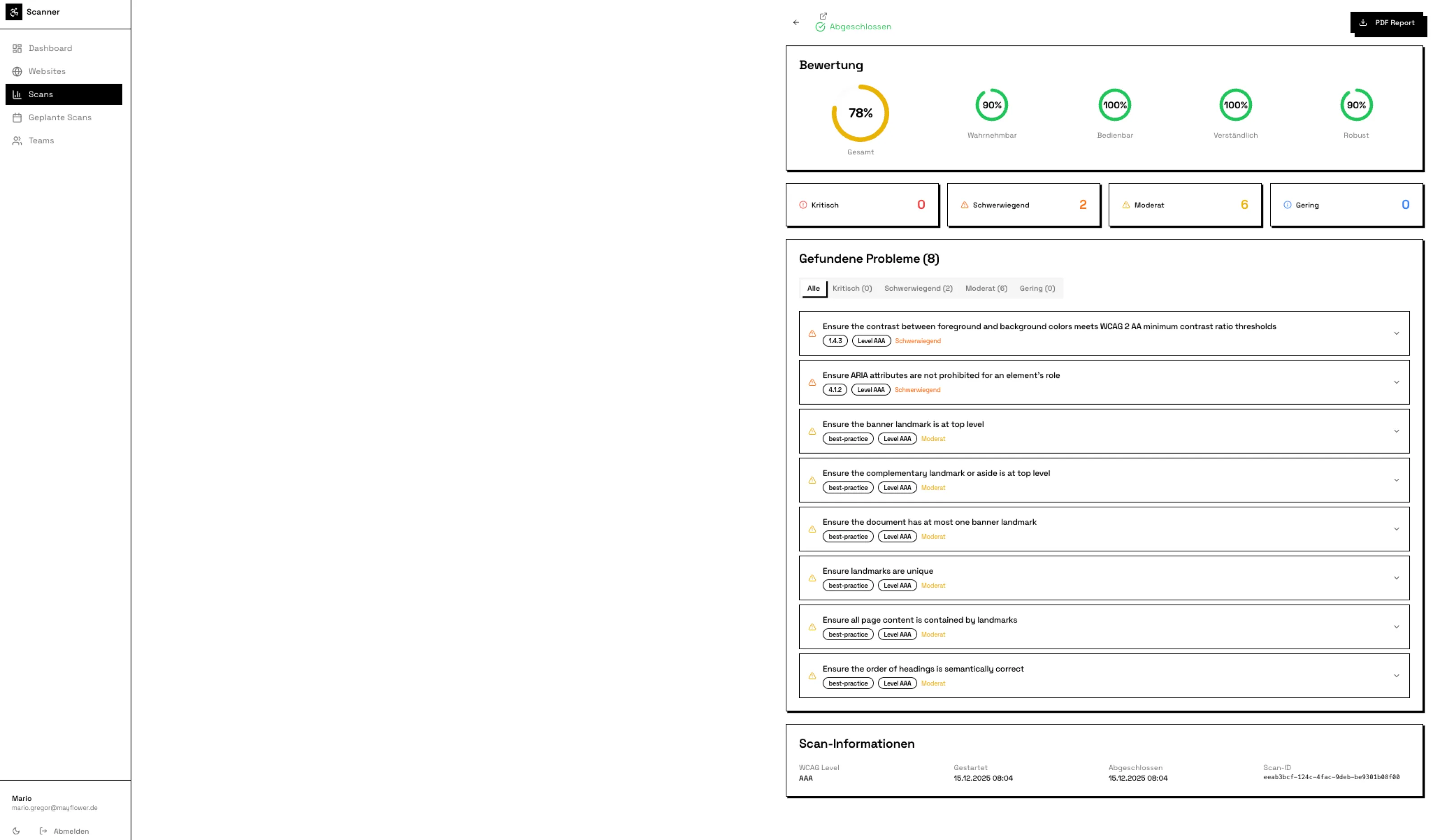
Lovable behauptete, das Backend würde keine Score-Daten liefern. Claude Code versicherte, die API funktioniere einwandfrei und gab ein Beispiel-Response-JSON mit korrektem Score zurück. Ich verbrachte Stunden damit, beide Systeme mit Informationen zu füttern. Lovable erhielt die exakte API-Response-Struktur vom Backend. Claude Code erhielt Screenshots der leeren Score-Anzeige im Frontend.
Keine der beiden KIs konnte das Problem identifizieren. Lovable implementierte verschiedene Varianten der Score-Darstellung, alle ohne Erfolg. Claude Code modifizierte die API-Response-Struktur mehrfach, ohne dass sich am Frontend etwas änderte. Nach acht Stunden frustrierenden Debuggings traf ich die Entscheidung, das Frontend komplett neu aufzusetzen.
Der Neustart löste das Problem tatsächlich. Die Score-Anzeige funktionierte plötzlich. Das ursprüngliche Problem lag in einer Inkonsistenz zwischen der React-State-Verwaltung im Frontend und der API-Response-Struktur, die keine der beiden KIs erkennen konnte, weil keine den vollständigen Kontext beider Codebasen hatte.
Aktueller Status
| Komponente | Status |
|---|---|
| Backend API | ✅ Läuft auf Railway |
| Datenbank | ✅ PostgreSQL auf Railway |
| Authentifizierung | ✅ Supabase JWT |
| Scanning | ✅ Funktioniert (8 Issues gefunden) |
| Score-Berechnung | ✅ Funktioniert (Score: 78) |
| KI-Analyse | ⚠️ Anthropic Credits erschöpft |
| Frontend-Anzeige | ⚠️ Score wird nicht angezeigt (Frontend-Issue) |
Die harte Wahrheit: Ohne technisches Verständnis geht es nicht
Eine zentrale Erkenntnis aus dem Barrierefreiheitsscanner-Projekt ist, dass trotz hochentwickelter KI-Tools ein fundiertes technisches Verständnis absolut notwendig bleibt. Dies zeigte sich in mehreren kritischen Situationen.
Bei der Integration von axe-core in das Puppeteer-Scanning musste ich verstehen, wie Browser-Automation funktioniert und wie die Ergebnisse korrekt extrahiert werden. Claude Code generierte zwar den grundlegenden Code, aber die Fehlerbehandlung für Timeout-Situationen und die korrekte Serialisierung der axe-Ergebnisse erforderte manuelles Eingreifen.
Die Implementierung der WebSocket-Verbindung für die Echtzeit-Fortschrittsanzeige funktionierte initial nicht zwischen Railway-Backend und Lovable-Frontend. Ich musste die CORS-Konfiguration verstehen, die WebSocket-Upgrade-Header analysieren und schließlich manuell die Socket.io-Client-Konfiguration im Frontend anpassen.
Die Anthropic API-Integration für die KI-Analyse der gefundenen Issues verbrauchte unerwartet schnell die verfügbaren Credits. Ich musste ein Rate-Limiting implementieren und die Prompt-Struktur optimieren, um die Kosten zu kontrollieren. Keine der beiden KIs hatte dies proaktiv berücksichtigt oder vorgeschlagen.
Die Kostenfrage: Schneller Start, langsames Finish
Die Zeitbilanz des Barrierefreiheitsscanner-Projekts ist deutlich negativ ausgefallen. Die ersten sichtbaren Ergebnisse entstanden tatsächlich innerhalb weniger Stunden. Backend mit API-Endpunkten, Datenbank-Schema und Scanner-Integration stand nach zwei Stunden. Frontend mit grundlegendem Design, Routing und Komponentenstruktur war nach weiteren zwei Stunden verfügbar.
Die folgenden drei Wochen bestanden jedoch aus ständigen Iterationen zwischen den beiden KI-Systemen. Das Debuggen der Score-Anzeige kostete acht Stunden. Die Authentifizierungs-Integration aufgrund des JWT-Key-Debakels benötigte sechs Stunden. Das Deployment-Setup mit Railway und die damit verbundenen Überzeugungsversuche gegenüber Lovable verschlangen weitere zehn Stunden. Die WebSocket-Integration für Echtzeit-Updates erforderte fünf Stunden Troubleshooting.
Ein erfahrenes Entwicklerteam hätte den gleichen Barrierefreiheitsscanner vermutlich in einer Woche entwickelt und deployed. Die ständigen Koordinationsschleifen, das manuelle Überprüfen von Annahmen beider Systeme und das Debuggen von Integrationsproblemen machten den vermeintlichen Zeitvorteil der KI-Tools zunichte.
Lessons Learned: Die Grenzen des Zwei-KI-Ansatzes
Aus dem Barrierefreiheitsscanner-Projekt lässt sich eine klare Empfehlung ableiten: Der Ansatz, Backend und Frontend von zwei verschiedenen KI-Systemen entwickeln zu lassen, ist in der aktuellen Form nicht praxistauglich für ernsthafte Projekte.
Für zukünftige Projekte würde ich ausschließlich mit einer einzigen KI arbeiten, die sowohl Backend als auch Frontend entwickelt. Dies würde die Koordinationsprobleme eliminieren, da das System einen vollständigen Überblick über beide Codebasen hätte. Die Inkonsistenzen zwischen API-Struktur und Frontend-Erwartungen, die im Scanner-Projekt so viel Zeit kosteten, würden nicht entstehen.
Für schnelles Prototyping kann der Zwei-KI-Ansatz funktionieren, solange man akzeptiert, dass das Ergebnis ein Wegwerf-Prototyp ist. Der initiale Scanner nach vier Stunden war beeindruckend und hätte ausgereicht, um die Machbarkeit zu demonstrieren. Sobald jedoch ein produktionsreifes System das Ziel ist, überwiegen die Nachteile deutlich.
Bei ernsthafter Produktentwicklung sollten erfahrene Entwickler und Software-Architekten von Anfang an involviert sein. Im Scanner-Projekt hätten diese beispielsweise die fehlende Rate-Limiting-Strategie für die Anthropic API frühzeitig identifiziert, die inkonsistente State-Verwaltung zwischen Frontend und Backend verhindert und eine robuste Fehlerbehandlung für das Puppeteer-Scanning implementiert.
Die Perspektive für Management und Entscheidungsträger
Das Barrierefreiheitsscanner-Projekt liefert wichtige Erkenntnisse für Führungskräfte und Projektverantwortliche. Die initiale Demonstration nach wenigen Stunden war beeindruckend und könnte leicht zu falschen Schlussfolgerungen führen. Ein funktionierendes Frontend mit API-Anbindung erweckt den Eindruck, dass das Projekt fast abgeschlossen ist.
Die Realität sah anders aus. Nur etwa zwanzig Prozent der Gesamtentwicklungszeit entfielen auf die initiale Implementierung. Die restlichen achtzig Prozent wurden für Integration, Debugging, Deployment und Qualitätssicherung benötigt. Diese Verteilung ist deutlich ungünstiger als bei traditioneller Entwicklung, wo die Implementierung typischerweise einen größeren Anteil der Gesamtzeit ausmacht.
Die Investition in KI-Tools sollte nicht als Ersatz für Entwicklungskapazität betrachtet werden. Im Scanner-Projekt hätten zwei erfahrene Full-Stack-Entwickler das gleiche Ergebnis in deutlich kürzerer Zeit und mit höherer Qualität geliefert. Die KI-Tools hätten diese Entwickler unterstützen können, aber nicht ersetzen.
Die verborgenen Kosten des Projekts waren erheblich. Die Anthropic API-Credits für die KI-Analyse waren schneller erschöpft als geplant. Das Railway-Deployment verursachte laufende Kosten, die bei der initialen Planung nicht berücksichtigt wurden. Die Zeit für das Selbststudium von Railway, Socket.IO und anderen Technologien muss ebenfalls in die Kostenkalkulation einfließen.
Fazit: Der Abbruch als klare Entscheidung
Das Barrierefreiheitsscanner-Projekt hat demonstriert, wo die aktuellen Grenzen KI-gestützter Entwicklung mit mehreren Tools liegen. Die Vision eines effizienten Workflows, bei dem Claude Code das Backend und Lovable das Frontend entwickelt, während der Mensch nur koordiniert, erwies sich als unrealistisch.
Nach Wochen frustrierender Debugging-Schleifen, irreführender Informationen und ständiger Koordination zwischen zwei KI-Systemen, die nicht miteinander kommunizieren, habe ich das Projekt letztendlich abgebrochen. Der Scanner erreichte zwar einen Zustand, in dem grundlegende Funktionen arbeiteten, war jedoch weit von einem produktionsreifen System entfernt. Die Score-Anzeige funktionierte sporadisch, die WebSocket-Verbindung brach unter Last zusammen, und die Authentifizierung war aufgrund der Lovable-Problematik nie vollständig stabil implementiert.
Die Entscheidung zum Projektabbruch fiel, als mir klar wurde, dass der Aufwand für die Fertigstellung den Nutzen deutlich übersteigen würde. Jedes gelöste Problem enthüllte weitere Integrationsschwierigkeiten. Die Anthropic API-Credits waren erschöpft, ohne dass die KI-Analyse je zufriedenstellend funktioniert hätte. Das Multi-Page-Scanning verursachte Memory-Leaks im Puppeteer-Browser, die weder Claude Code noch Lovable identifizieren konnten. Die Liste der offenen Issues wuchs schneller als die der behobenen Probleme.
Die wichtigste Erkenntnis aus diesem gescheiterten Versuch lautet: Der Zwei-KI-Ansatz ist in der aktuellen Form nicht tragfähig für ernsthafte Produktentwicklung. Die fehlende Kommunikation zwischen den Systemen, die widersprüchlichen Annahmen über Schnittstellen und die Tendenz beider Tools, den Code des jeweils anderen nicht zu berücksichtigen, führen zwangsläufig zu unlösbaren Integrationsproblemen, sobald das Projekt eine gewisse Komplexität überschreitet.
Für die Zukunft plane ich einen neuen Ansatz für den Barrierefreiheitsscanner. Statt mit zwei verschiedenen KI-Tools zu arbeiten, werde ich das gesamte Projekt mit einer einzigen KI entwickeln lassen. Dies sollte die Koordinationsprobleme eliminieren und ein konsistentes Verständnis der Gesamtarchitektur ermöglichen. Zusätzlich werde ich von Anfang an erfahrene Entwickler einbeziehen, die den KI-generierten Code kritisch überprüfen und insbesondere die Architekturentscheidungen validieren.
Schreibe einen Kommentar