A domain-specific language (DSL) is a programming language or descriptive file format to formulate and solve specific problems in specific domains, as opposed to generic descriptive file formats (such as XML) and general-purpose programming languages (such as Java) which can be employed in any domain.
A paradigmatic use case for a domain specific programming language is domain-specific computations, e.g. physical simulations, which can be simplified and optimized by using a language containing the required and only the required mathematical and physical expressions. At a project at Mayflower, we recently encountered a use case for employing a DSL as a descriptive file format: we designed a DSL describing document models to generate database fixtures from it.
A problem and our approach to it
In more detail, we had to describe possible document structures in the database. These structures are used to (i) check whether a certain document is correct and (ii) to generate new (empty) documents of that type. Since the structures can be very complex, hard-coding these structures in SQL is cumbersome, error-prone, hard to read and hard to maintain. Moreover, differences between versions of a document type are not transparent. By using a DSL, we managed to describe these structures in the language of the domain, in a concise and natural human-readable manner.
This significantly reduced development time and bug counts. Before using a DSL, several revisions of the initial SQL code were necessary, since even a peer-review process could not eliminate all errors. Now, even an inexperienced developer can implement a document type and generate the necessary SQL within minutes. The Scrum story points assigned to generating fixtures during planning meetings and bug counts have been reduced to the minimum value of 1.
Moreover, we have achieved much higher maintainability. One reason is that it is immediately clear what the current document structure is, i.e. the code of the DSL also serves as a documentation. Here, the advantages of using a DSL can be compared to hard-coded unit tests vs. writing „specs“ in the language of the problem domain.
A simple case study
In the remainder of this article, I will describe the process by means of a simpler example. Although this use case is very simple, the beauty of using a DSL can be already appreciated by looking at the following fictive descriptive file format. In this example, a DSL (called .baskets) is used to describe shopping baskets for test cases, which should be converted to SQL for a test setup (I will later refer to the file as TestCase1.baskets):
The shopping basket for user "Alex" contains 3 items of type "chocolate" for 1.20€ each, 1 item of type "whine" for 5.00€ each, 2 items of type "orange juice" for 1.00€ each. The shopping basket for user "Veronika" contains 2 items of type "apple" for 0.50€ each.
From this, the following SQL code shall be generated automatically:
Insert into users (id, name) values (0, 'Alex'); Insert into baskets (user_id, item_name, unit_price, amount) values ((select user_id from users where name='Alex'), chocolate, 1.20, 3); Insert into baskets (user_id, item_name, unit_price, amount) values ((select user_id from users where name='Alex'), whine, 5.00, 1); Insert into baskets (user_id, item_name, unit_price, amount) values ((select user_id from users where name='Alex'), orange juice, 1.00, 2); Insert into users (id, name) values (1, 'Veronika'); Insert into baskets (user_id, item_name, unit_price, amount) values ((select user_id from users where name='Veronika'), apple, 0.50, 2);
The advantages described above should already be recognizable in the example. Writing the SQL by hand is error prone and cumbersome, whereas even a client without any programming skills could write specifications using the .baskets file format.
Now, there are many ways of implementing such a process. You could write your own parser. But it is always good to reduce work to the minimum, to focus on precisely the problem at hand, and to build up on existing, tested stable software.
One simple and elegant way of quickly implementing stable parsers for a DSL is Antlr (currently in version 4 — so it’s called Antlr4). Antlr4 allows one to describe grammars and to generate parsers on this basis which can then be brought to life using a classical programming language such as Java. Moreover, it comes with a great tool called „Antlrworks“, an extension of the NetBeans IDE with some quite comfortable features. To achieve our goals, we can install Antlr and Antlrworks, start Antlrworks, and create a new grammar file (select the type „combined grammar“):
grammar baskets_minimal;
prog: (basket)+ ;
basket: 'The shopping basket for user' STRING 'contains' item (',' item)* '.' ;
item: INT ('items'|'item') 'of type' STRING 'for' PRICE 'each' ;
STRING : '"' (~["])+ '"' ;
PRICE : INT'.'INT '€' ;
INT : [0-9]+ ;
WHITESPACE : [\t\r\n ]+ -> skip ;
Some explanation is in order: in Antlr4, you describe a grammar by specifying parser rules and lexer rules, written as „[name] : [rule] ;“, whereas the rule has a format that should be immediately readable by someone familiar with regular expressions (for example „(‚,‘ item)* matches any number of occurences (this includes 0 occurences!) of sequences of ‚,‘ followed by something that matches the parser rule item). Lexer rules start with capital letters and specify terminal symbols. The WHITESPACE rule tells the parser which whitespace characters to ignore. For a detailed description, I can only refer to the documentation here, but most of the simple example should be (almost) self-explaining. A nice feature of Antlrworks is that a state machine representation of a rule selected by the cursor in the editor is automatically displayed on the left. So you can see very quickly whether the rule you have written down is interpreted as intended.
You can then test and „run“ this grammar, i.e. run the parser Antlr4 generates from this grammar, and test whether it parses our .baskets file as expected. For this, use „Run in TestRig“ from the „Run“ menu and select the TestCase1.baskets file as the input file and the „prog“ parser rule as the starting point from the „Start Rule“ drop down menu. Here is a screen shot of the dialog:
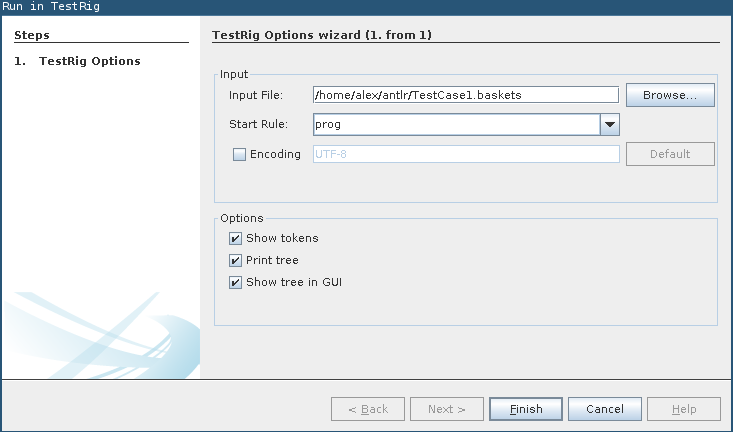
The grammar should be compiled, and Antlrworks should print a syntax diagram of the file. If not, you can enable this by selecting „Print tree“ from the „Run in TestRig“ options. The result should look somewhat like this:
Kurze Unterbechung
Das ist dein Alltag?
Keine Sorge – Hilfe ist nah! Melde Dich unverbindlich bei uns und wir schauen uns gemeinsam an, ob und wie wir Dich unterstützen können.
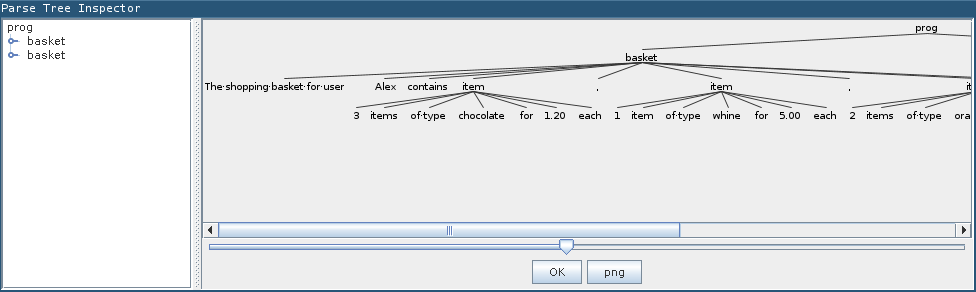
So far so good. However, although our .baskets file is now correctly parsed, no output is generated. Now, one simple way of generating output is to use Java code snippets. Java code snippets are little pieces of Java code inside the grammar file that can access the current state of the parser and lexer (note that although Java is the default language for Antlr4, it also works with other languages such as Python). Code snippets can be injected by enclosing Java code in curly brackets „{ … }“. Moreover, there are certain keywords that can be used for special purposes, such as „@members { … }“ to declare global variables. Here is an example to see this in action. If the following is run in Antlr4’s test rig, the desired output is generated:
grammar baskets;
@members {
int userCount = 0;
String currentName = "";
}
prog: (basket)+ ;
basket:
'The shopping basket for user' STRING
{
currentName = $STRING.text;
System.out.println(
"Insert into users (id, name) values (" + Integer.toString(userCount) +
", '" + currentName + "');"
);
this.userCount++;
}
'contains' item (',' item)* '.' ;
item:
INT { int count = $INT.int; }
('items'|'item') 'of type' STRING { String type = $STRING.text; } 'for' PRICE 'each'
{
System.out.println(
"Insert into baskets (user_id, item_name, unit_price, amount) " +
"values ((select user_id from users where name='" + currentName + "'), " +
type + ", " + $PRICE.text + ", " + Integer.toString(count) + ");"
);
} ;
STRING : '"' (~["])+ '"'
{
setText(org.antlr.v4.misc.CharSupport.getStringFromGrammarStringLiteral(getText()));
} ;
PRICE : INT'.'INT'€' {setText(getText().substring(0, getText().length()-1));} ;
INT : [0-9]+ ;
WHITESPACE : [\t\r\n ]+ -> skip ;
Let’s go through this piece of combined Antlr/Java code. First, the Antlr code together with the snippets defines a Java class that is generated by Antlr. If you run your Antlr4 code in a test rig, the classes will be generated and compiled in the background, and then executed as a Java program. By choosing „Run/Generate Recognizer“ you can generate the code manually, to inspect it or to use it in Java projects. I recommend having a look at the generated code, because it sheds light on how Antlr4 works internally and helps with debugging.
Now, in „@members { … }“ we define two global variables. We need to store the user count in order to insert the right IDs in the generated SQL. Moreover, we store the current user name to have it available at other places than directly after the parser reads the user name. Note that although this might not be the most elegant way, it works well for simple cases like ours. Note that we store the user name in the global variable after we read the user name string in line 10, and access it again via this variable in line 26, where the original user name string context is not available anymore.
In line 12, you can see how the current state of the parser is accessed. The content of the parsed STRING rule can be accessed via $STRING.text. The read string can then be used for creating the output. The output is generated by using the Java standard way — System.out.println and the like.
Sometimes, the strings read by the parser need to be manipulated, because ANTLR only returns the whole string matched by a rule. In the case of STRING or PRICE, you can see this happen. We do not want to store the string with double quotes, and we do not want to store the €-sign. So in lines 32 to 34, we remove the €-sign and double quotes by using a three-step pattern: (i) we use gettext to get the content matched by the current rule (ii) we manipulate the content (iii) we call settext to ensure that the manipulated content is returned by the parser. In our snippets we can then use $RULE.text without having to do further manipulations (see e.g. lines 12 and 27). Note that the double quotes case is so common that Antlr provides a built-in function for that: org.antlr.v4.misc.CharSupport.getStringFromGrammarStringLiteral.
Summing up
All in all, we get a nice fixture generator with a domain-specific language — with all the advantages described in the introduction — in just 36 lines of code. This case was very simple, but the possibilities are endless. Examples are plenty, and Antlr is well-documented. http://www.antlr.org is a good place to start. As a final note, it makes sense to use Antlrworks for fiddling around and then to use a build system in your Java project to generate Java code from Antlr source code automatically before the compilation step. Moreover, it make sense to separate Java code and Antlr code. All this is not difficult. However, it has to be left for another article.

Schreibe einen Kommentar