

Viele Data-Projekte starten mit einem simplen Python-Skript. Schnell gebaut, liefert es erste Ergebnisse – und landet dann, meist ungeplant, im Produktivbetrieb. Spätestens wenn dieses Skript zur zentralen Quelle für Reports oder Machine-Learning-Modelle wird, zeigt sich das Problem:
Keine Tests, keine Dokumentation, kein Monitoring.
Was als Proof of Concept begann, wird zum unberechenbaren System.
Willkommen in der Wartungshölle.

Dein Team kämpft mit Reports, Silos und Tool-Wildwuchs, während KI-Projekte auf der Strecke bleiben?
Wir implementieren Datenarbeit, die nicht bremst – sondern Business beschleunigt.
In diesem Beitrag zeige ich, warum stabile Data-Pipelines das Rückgrat datengetriebener Systeme sind – und wie Dagster hilft, aus gewachsenen Skripten skalierbare, produktionsreife Datenprodukte zu machen.
Was ist eigentlich eine Data-Pipeline?
Eine Data-Pipeline ist im Grunde die Versorgungsleitung deiner Daten: Sie transportiert Informationen aus verschiedenen Quellen über definierte Verarbeitungsschritte bis zu den Systemen, in denen daraus Wert entsteht – etwa Dashboards, KI-Modelle oder Data Warehouses.
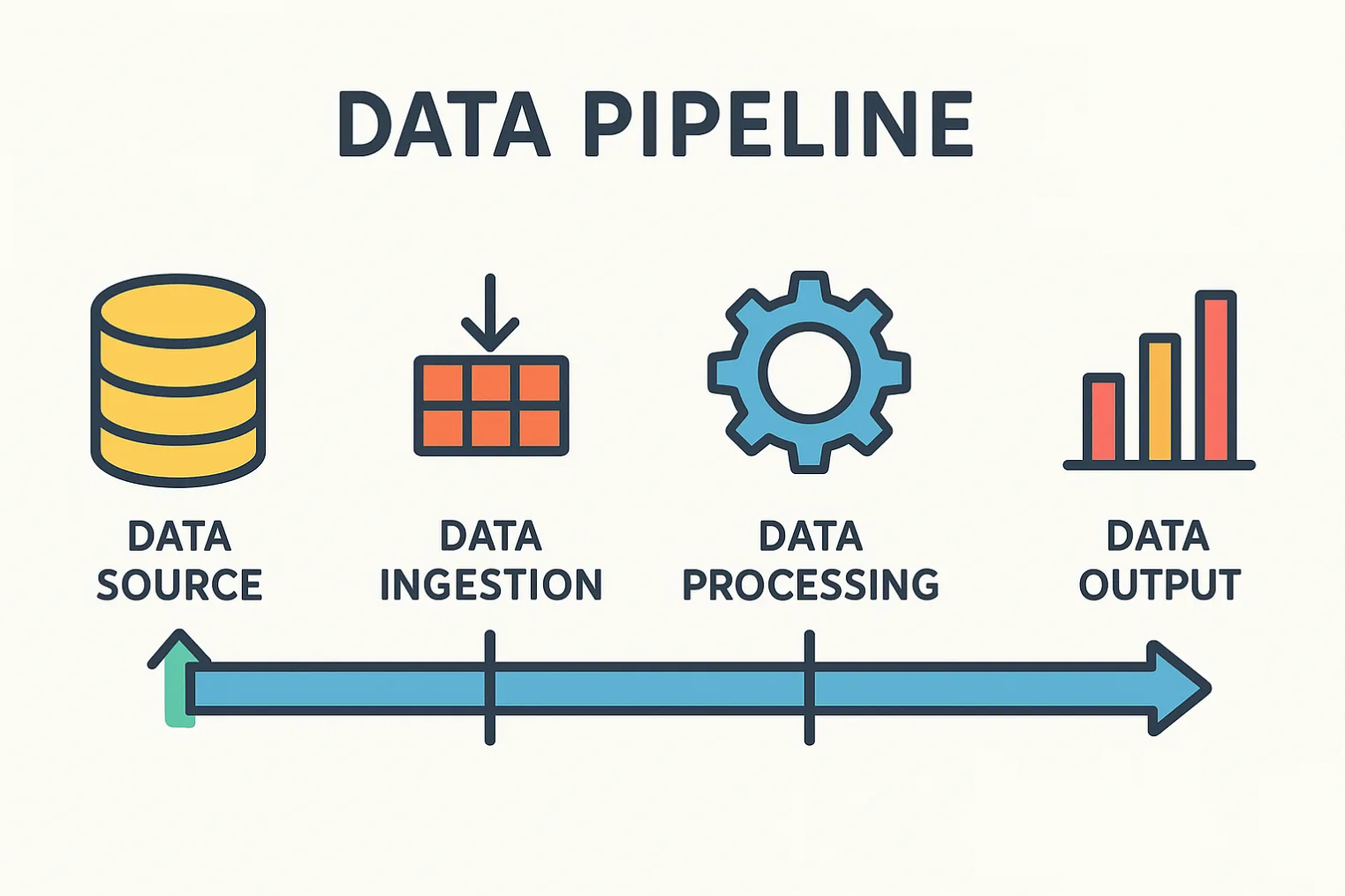
Gute Pipelines zeichnen sich durch klare Eigenschaften aus:
- Zuverlässigkeit: Sie laufen regelmäßig und fehlerfrei.
- Transparenz: Monitoring und Logging machen Abläufe nachvollziehbar.
- Skalierbarkeit: Architektur und Infrastruktur wachsen mit.
- Wertbeitrag: Sie liefern die Basis für Entscheidungen, Analysen und Automatisierung.
Die Realität vieler Teams
In der Praxis sieht es selten so strukturiert aus. Data-Engineering-Teams jonglieren mit wachsenden Datenmengen, heterogenen Quellen und unterschiedlichen Stakeholder-Anforderungen. Schnelle Proof-of-Concepts werden so zur Dauerlösung. Wissen bleibt in Silos, Änderungen werden zum Risiko, und jedes Release fühlt sich an wie ein Balanceakt.
Das Ergebnis? Zeit fließt in Debugging und Fehleranalyse statt in Innovation. Und Unternehmen zahlen den Preis in Form von Opportunitätskosten – sie verlieren Geschwindigkeit, Stabilität und Vertrauen in ihre Daten.
Von der Skript-Sammlung zur Pipeline-Plattform
Hier setzt ein moderner Orchestrator wie Dagster an. Dagster bringt Ordnung in gewachsene Strukturen und hilft Teams, aus vielen einzelnen Skripten ein transparentes, skalierbares System zu bauen.
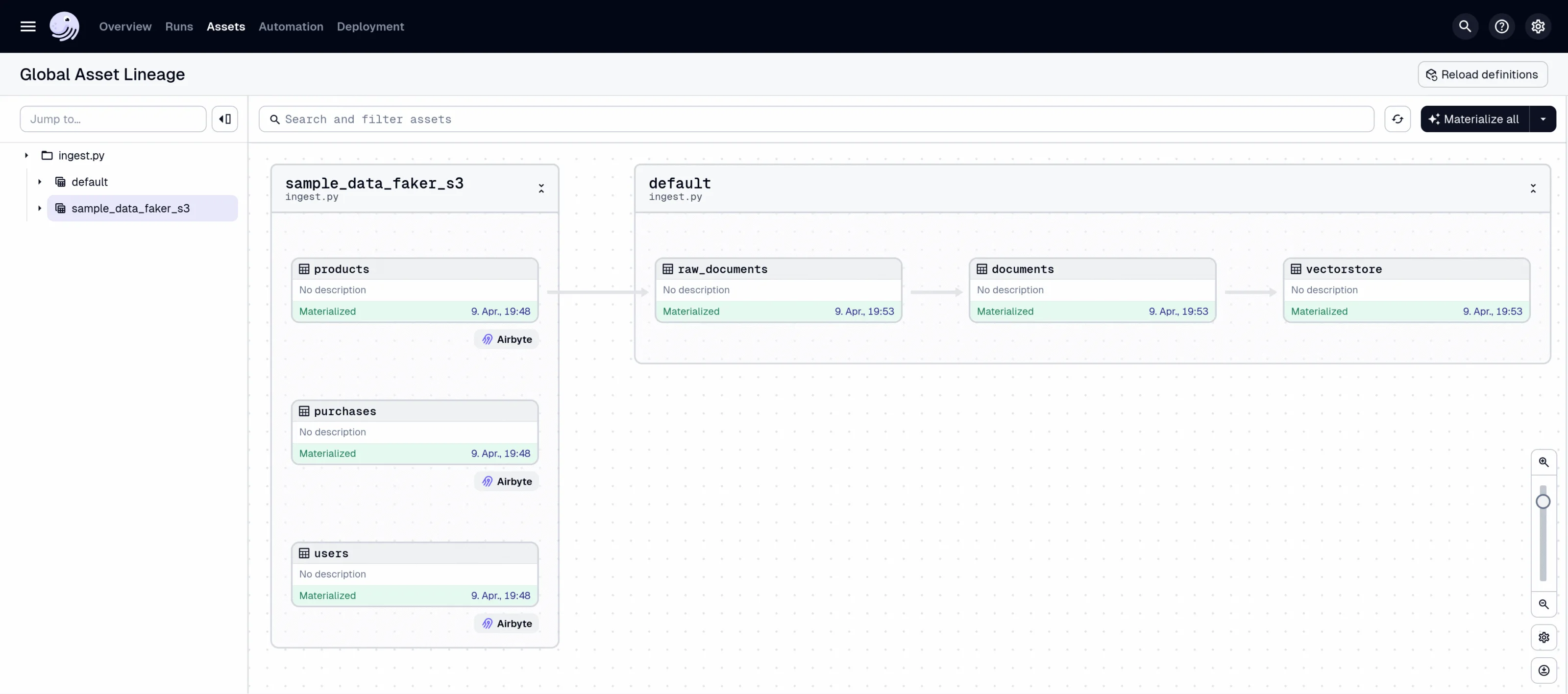
In der integrierten Web-UI werden Pipelines, Runs und Datenassets übersichtlich dargestellt. Auf einen Blick ist erkennbar:
- welche Pipelines erfolgreich durchgelaufen sind,
- wo Fehler auftreten,
- und welche Assets aktuell, fehlerhaft oder veraltet sind.
Logging, Monitoring und Alerting sind direkt integriert – ganz ohne zusätzliche Tools. So entsteht ein Framework, das Data-Teams entlastet und sie befähigt, Prozesse sicher zu automatisieren.
Dagster als Teil einer modernen Data-Pipeline-Architektur
Dagster spielt in modernen Datenprojekten eine zentrale Rolle – allerdings nicht als alleinstehendes Tool, sondern als Teil einer größeren Gesamtarchitektur.
Während Dagster die Orchestrierung und das Management der Datenflüsse übernimmt, gehören zu einer vollständigen Pipeline typischerweise weitere Bausteine:
- Daten-Ingestion mit Tools wie Airbyte oder Fivetran,
- Transformation und Speicherung in Data Warehouses oder Data Lakes,
- sowie nachgelagerte Nutzung durch Machine-Learning-Modelle oder Anwendungen, z. B. mit Frameworks wie LangChain.
Warum Dagster?
| Herausforderung | Wie Dagster hilft |
|---|---|
| Wachsende Datenmengen, komplexe Quellen | Klare Modularisierung und Wiederverwendbarkeit von Pipelines |
| Fehlende Transparenz & Monitoring | Eingebaute Observability mit Logs, Metriken und Alerts |
| Abhängigkeit von Einzelpersonen | Zentrale Plattform, die Wissen teilt statt kapselt |
| Fehlende Automatisierung | Integration mit CI/CD und DataOps-Workflows |
| Unterschiedliche Tool-Stacks in Teams | Flexible Integration über APIs, Python und Container-Umgebungen |
Dagster ist also nicht nur Framework, sondern ein Enabler für moderne Data-Engineering-Kultur:
Ein gemeinsames System, das Teams verbindet, Prozesse vereinheitlicht und technische Schulden reduziert.
Der Business-Nutzen stabiler Data-Pipelines
Stabil laufende Pipelines sind kein Selbstzweck. Sie schaffen die Grundlage für verlässliche Reports, reproduzierbare Machine-Learning-Modelle und datengetriebene Innovation.
Unternehmen profitieren gleich mehrfach:
- Weniger Ausfälle und klarere Fehleranalysen
- Schnellere Deployments durch Automatisierung
- Höhere Datenqualität und belastbare Entscheidungsgrundlagen
- Mehr Freiraum für Innovation statt Ad-hoc-Feuerwehr
Kurz gesagt: Aus gewachsenen Proof-of-Concepts werden skalierbare, robuste Datenprodukte.
Der Weg dorthin muss kein Big Bang sein.
Wie mein Kollege Ben Bajorat in seinem Webinar Vom Python-Skript zur skalierbaren Data-Pipeline zeigt, gelingt die Transformation schrittweise – mit klaren Prinzipien, erprobten Frameworks und einem Fokus auf Business Value.
„Man muss nicht alles neu aufsetzen. Entscheidend ist, bestehende Strukturen schrittweise zu transformieren – mit den richtigen Tools. In unseren Projekten hat sich Dagster dabei als besonders zuverlässiger Orchestrator bewährt.“
― Ben Bajorat, Software Engineer & Data Specialist, Mayflower GmbH
Das Webinar zum Thema Dagster
Erfahre im Webinar, wie du aus fragilen Skripten eine belastbare Datenbasis für dein Unternehmen aufbaust – inklusive Praxisbeispielen und Live-Einblicken in Dagster.
Melde dich hier direkt an oder finde alle weiteren Informationen auf der Webinar-Website.

Schreibe einen Kommentar