

Stelle dir folgendes vor: Du arbeitest an der praktischen Umsetzung von LLM-Anwendungen und suchst nach einem stabilen technischen Fundament, um den Applikationen alle wichtigen Daten zukommen zu lassen.
Ein guter Zeitpunkt, um einen Blick darauf zu werfen, wie du mit Open-Source-Tools wie LangChain, Airbyte und Dagster eine moderne, wartbare AI-Datenpipeline aufbaust – inklusive Vektorisierung und Chatbot-Anbindung. Dafür sollten wir allerdings zunächst einmal ganz am Anfang beginnen …
Die Herausforderung moderner AI Data Pipelines
Das Training von Large Language Models (LLMs) erfordert umfangreiche und relevante Kontextdaten. Diese Daten sind typischerweise über zahlreiche Quellen verstreut – darunter Bücher, Webseiten, Artikel, offene Datensätze, externe Dienste sowie diverse Datenbanken und Data Warehouses. Um die Aktualität dieser Daten zu gewährleisten, ist eine robuste Pipeline unerlässlich.
Die Herausforderung liegt nicht nur im Zugang zu diesen Daten, der oft komplex ist, sondern auch in der mühsamen Weiterverarbeitung. Hier kommen drei Schlüsseltechnologien ins Spiel:
- Airbyte fungiert als EL-Werkzeug (Extract Load), das die Extraktion von Daten aus vielfältigen Quellen und deren Transport zu Object Stores, Datenbanken und Data Lakes ermöglicht, wo sie weiterverarbeitet werden können.
- Dagster ist ein Orchestrierungswerkzeug für Datenplattformen und unterstützt die Umsetzung komplexer Workflows, indem es die einzelnen Verarbeitungsschritte koordiniert und überwacht.
- LangChain bietet als Framework für LLM-Anwendungen eine Abstraktionsschicht über verschiedene AI-Anbieter hinweg und vereinfacht so die Entwicklung intelligenter Anwendungen.
Im Jahr 2023 veröffentlichten Airbyte und Dagster gemeinsam interessante Artikel über AI Data Pipelines: LLM training pipelines with Langchain, Airbyte, and Dagster (im Dagster-Blog) und How to implement AI data pipeline?: Langchain, Dagster & Airbyte (bei Airbyte).
Diese Artikel demonstrierten, wie man diese Tools kombinieren kann, um leistungsfähige Datenpipelines für LLMs zu erstellen. Die darin vorgestellten Konzepte und Architekturen sind nach wie vor inhaltlich relevant und bieten eine solide Grundlage für das Verständnis von AI Data Pipelines.
So weit, so gut. Doch … die Technologielandschaft entwickelt sich weiter. Während die grundlegenden Konzepte noch immer Bestand haben, hat sich die technische Umsetzung seit der Veröffentlichung dieser Artikel deutlich weiterentwickelt. APIs haben sich verändert, Best Practices wurden verfeinert und neue Funktionen hinzugefügt.
In diesem Artikel gehen wir also Schritt für Schritt durch die aktualisierte Implementierung einer AI-Datenpipeline mit LangChain, Airbyte und Dagster. So richtig zum nach- und mitmachen. Und keine Sorge; es wird auf alles eingegangen!
Bevor wir durchstarten, sei an dieser Stelle noch auf eines unserer Webinare verwiesen, dass die Herausforderung aus einer anderen Flughöhe betrachtet (alternativ: direkt weiter im Text!):

AI Data Pipelines
Dein AI-Potenzial bleibt ungenutzt weil deine AI-Lösung in weniger als 90 Prozent die Antwort liefert, die in deinen Wissensquellen existiert?
Wenn deiner AI also mal wieder die richtigen Daten fehlen, haben wir hier genau das richtige Webinar für dich: AI Data Pipelines. Das erwartet dich:
- Aufbau einer vollständigen Dokumenten-Pipeline mit einer beispielhaften SharePoint-Integration
- Automatisierte Extraktion und Strukturierung von Dokumenteninhalten
- Speicherung in Vektordatenbanken für semantische Suche
- Wie auch aus Diagrammen und Bildern die richtigen und wichtigen Informationen gezogen werden
- Integration mit Large Language Models (LLMs) für intelligente Anwendungen
- u.v.m
Was hat sich seit 2023 geändert?
Die wichtigsten Änderungen im Überblick:
Airbyte
- Der offizielle Weg, Airbyte lokal zu testen, ist jetzt Kubernetes.
- Da die mit „Local“ ausgezeichneten Connectoren ein lokales Dateisystem verwenden und diese Connectoren in flüchtigen Kubernetes-Jobs laufen, empfiehlt es sich eine andere Art der Speicherung zu verwenden, z. B. eine Postgres-Datenbank.
LangChain
- LangChain Core hat einen signifikanten Versionssprung von 0.1.x auf 0.3.x vollzogen.
- Zahlreiche API-Änderungen haben dazu geführt, dass der ursprüngliche Code viele Deprecation-Warnungen erzeugt. Wir wollen unsere Datenprojekte ohne Deprecations starten.
Dagster
- Die Proof-of-Concept-Implementierung wurde aktualisiert, damit sie die Postgres-Datenbank statt das lokale Dateisystem verwendet.
Überblick
Das folgende Diagramm veranschaulicht die Architektur der verwendeten Komponenten und den Datenfluss:
+------------+ +--------------------+ +---------------------------------+ O | | | | | | /|\ | Daten- | | Lokaler Airbyte | | Localhost | / \ | Quellen | | Kubernetes Cluster | | | | | | | | | | | | +--------+ | | +------------+ | | +-------------+ +----------+ | | | | | | | | | | | | | | | | | | | Sample |<----->| Airbyte |<--------->| Dagster Dev | | Chat-Bot |<------+ | | Data | | | | | | | | ingest.py | | query.py | | | | | | | | | +------->| | | | | | +--------+ | | +------------+ | | | +-------------+ +----------+ | | | | | | | | | ^ | | | | v | | | v | | | | | +------------+ | | | +-------------+ | | | | | | | | | | | | | | | | | | Postgres |--+ | | | VectorDB |--------+ | | | | | | | | | | | | | | +------------+ | | +-------------+ | | | | | | | +------------+ +--------------------+ +---------------------------------+
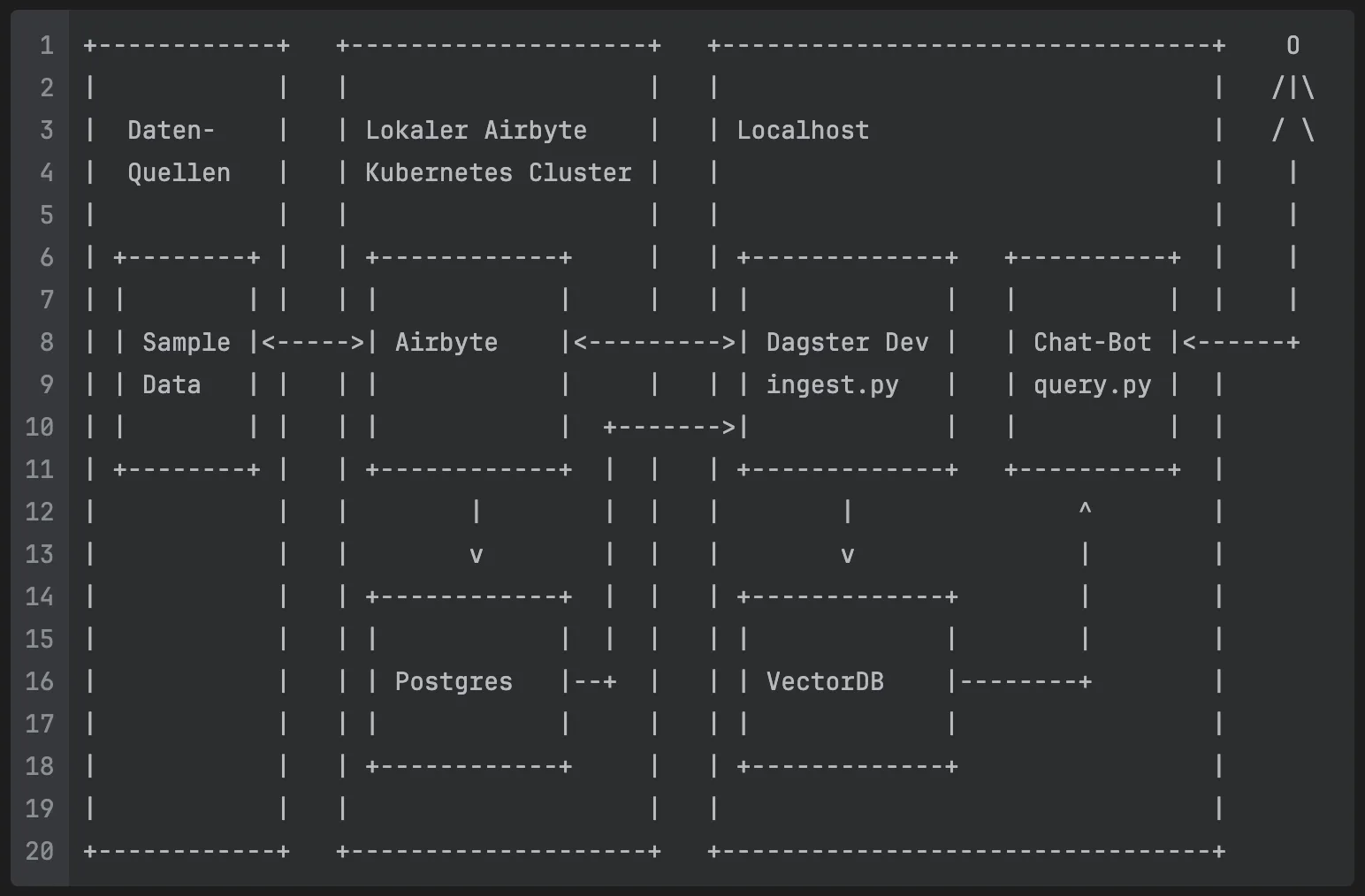
Die Architektur lässt sich in drei Hauptbereiche unterteilen:
1. Datenquellen
Links im Diagramm befinden sich die Datenquellen, aus denen wir Informationen extrahieren. In unserem Beispiel verwenden wir „Sample Data“ aus dem Faker-Connector von Airbyte, der synthetische Testdaten generiert. In einer Produktivumgebung könnten hier verschiedene reale Datenquellen angebunden werden, wie APIs, Datenbanken oder Object-Stores.
2. Airbyte Kubernetes Cluster
Im mittleren Bereich befindet sich der lokale Airbyte Kubernetes Cluster, der mit abctl installiert wird. Folgenden zwei Komponenten sind für uns relevant:
- Airbyte: Verantwortlich für die Extraktion und das Laden der Daten (EL). Airbyte verbindet sich mit den Datenquellen, extrahiert die Daten und speichert sie in strukturierter Form.
- Postgres: In diese Datenbank werden die Daten aus der Quelle gespeichert. Sie dient auch als Quelle für Dagster, um die Daten aus den Airbyte-Streams zu laden.
3. Localhost
Auf der rechten Seite befindet sich die Localhost-Umgebung, in der die Datenverarbeitung und -nutzung stattfindet:
- Dagster Dev
ingest.py: Orchestriert den gesamten Datenverarbeitungsprozess. Dagster ruft Daten aus Airbyte ab, transformiert sie und speichert sie in der Vektordatenbank. Dieingest.pyenthält die Asset-Definitionen und Transformationslogik. - VectorDB: Eine spezialisierte Datenbank für die Speicherung von Vektorrepräsentationen der verarbeiteten Daten. Sie ermöglicht semantische Suchen und Ähnlichkeitsabfragen, die für LLM-Anwendungen essentiell sind.
- Chat-Bot
query.py: Die Benutzerschnittstelle, über die Endnutzer mit den verarbeiteten Daten interagieren können. Der Chat-Bot nutzt die Vektordatenbank, um relevante Kontextinformationen zu finden, und kombiniert diese mit den Fähigkeiten des LLM, um präzise Antworten zu generieren.
Mittels Port-Forwarding (Port 5432) wird die Datenbank-Verbindung am Host verfügbar gemacht.
Datenfluss
- Daten werden von den Quellen durch Airbyte extrahiert und in der Datenbank gespeichert
- Dagster orchestriert den Prozess und löst Airbyte-Synchronisierungen aus
- Die extrahierten Daten werden von Dagster geladen und transformiert
- Transformierte Daten werden vektorisiert und in der VectorDB gespeichert
- Der Chat-Bot greift auf die VectorDB zu, um kontextbezogene Antworten zu generieren
Schritt-für-Schritt-Anleitung zur Einrichtung
Nach der Sicherstellung aller Voraussetzungen können wir nun mit der eigentlichen Einrichtung der Pipeline beginnen. Folge einfach dieser Anleitung, um alle Komponenten korrekt zu konfigurieren und miteinander zu verbinden.
Projekt klonen
Zunächst musst du das Repository klonen und in das Verzeichnis wechseln:
git clone https://github.com/mayflower/airbyte-dagster-langchain-poc cd airbyte-dagster-langchain-poc
Im Repo findest du übrigens auch die Voraussetzungen, die auf deinem Rechner erfüllt sein sollten, um dieses Projekt zum Laufen zu bekommen.
Airbyte-Installation
Zunächst installieren wir Airbyte und deaktivieren die Login-Seite für eine einfachere Entwicklung. Weitere Details findest du in der Airbyte-Dokumentation .
abctl local install --values ./airbyte-values.yaml
Dieser Schritt kann einige Minuten dauern. Wenn die Installation erfolgt ist, sollte sich der Browser öffnen und eine Verbindung zur Airbyte Web-UI erscheinen. Es werden die Daten abgefragt, um dem Airbyte-Workspace einzurichten.
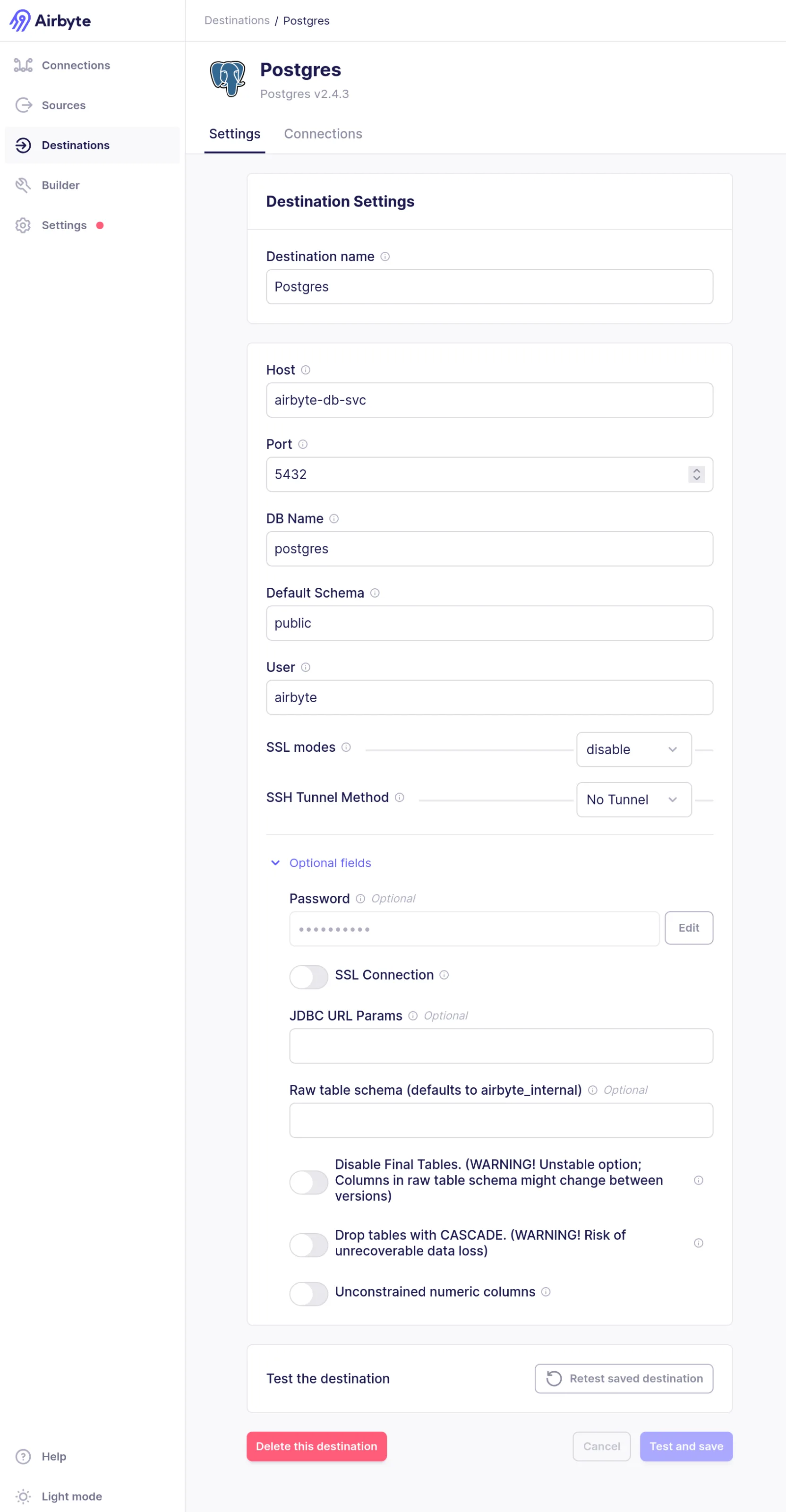
Konfiguration der Airbyte-Verbindung
Nun öffnen wir die Airbyte Web-UI unter http://localhost:8000 und erstellen eine neue Connection.
- Wähle als Quelle „Sample Data (Faker)“ aus
- Wähle als Ziel „Postgres“ aus und konfiguriere die Datenbank-Verbindung mit den folgenden Parametern:
- Host:
airbyte-db-svc - Port:
5432 - DB Name:
postgres - Default Schema:
public - User:
airbyte - SSL modes:
disable - SSH Tunnel Method:
No Tunnel - Password:
airbyte
- Host:
- Bei der Stream-Konfiguration wählst du alle Stream aus
- Zuletzt bei Configure Connection den Schedule type auf
Manualsetzen. Die Änderung ist Optional, hilft aber später bei der Veranschaulichung was passiert
Einrichtung der Dagster-Pipeline
Nun erstellen wir eine virtuelle Umgebung und installieren die Abhängigkeiten:
python -m venv .venv source .venv/bin/activate pip install -r requirements.txt
Als nächstes setzen wir die Umgebungsvariable OPENAI_API_KEY:
export OPENAI_API_KEY=YOUR_OPENAI_API_KEY
Dann starten wir den Port-Forward zur Datenbank:
kubectl --kubeconfig $HOME/.airbyte/abctl/abctl.kubeconfig port-forward \ --namespace airbyte-abctl airbyte-db-0 5432:5432
… um dann zuguterletzt mit dagster dev -f ingest.py Dagster zu starten.
Damit haben wir erfolgreich alle Komponenten der Pipeline eingerichtet und können nun mit der Verarbeitung von Daten beginnen.
15 Minuten knallharter Fokus!

In je 15 Minuten alles, was Du wissen musst!
Im KI-Umfeld muss es schnell gehen. Deswegen bieten wir euch auch einen schnellen Einstieg in die wichtigsten Data-KI-Themen. 15 Minuten Fokus, immer mit wertvollen Einblicken und Erkenntnissen aus der Praxis.
Einfach kostenlos anmelden und sofort loslegen.
Nutzung der Pipeline
Nachdem alle Komponenten erfolgreich eingerichtet wurden, können wir nun die Pipeline in Aktion setzen und die verarbeiteten Daten nutzen.
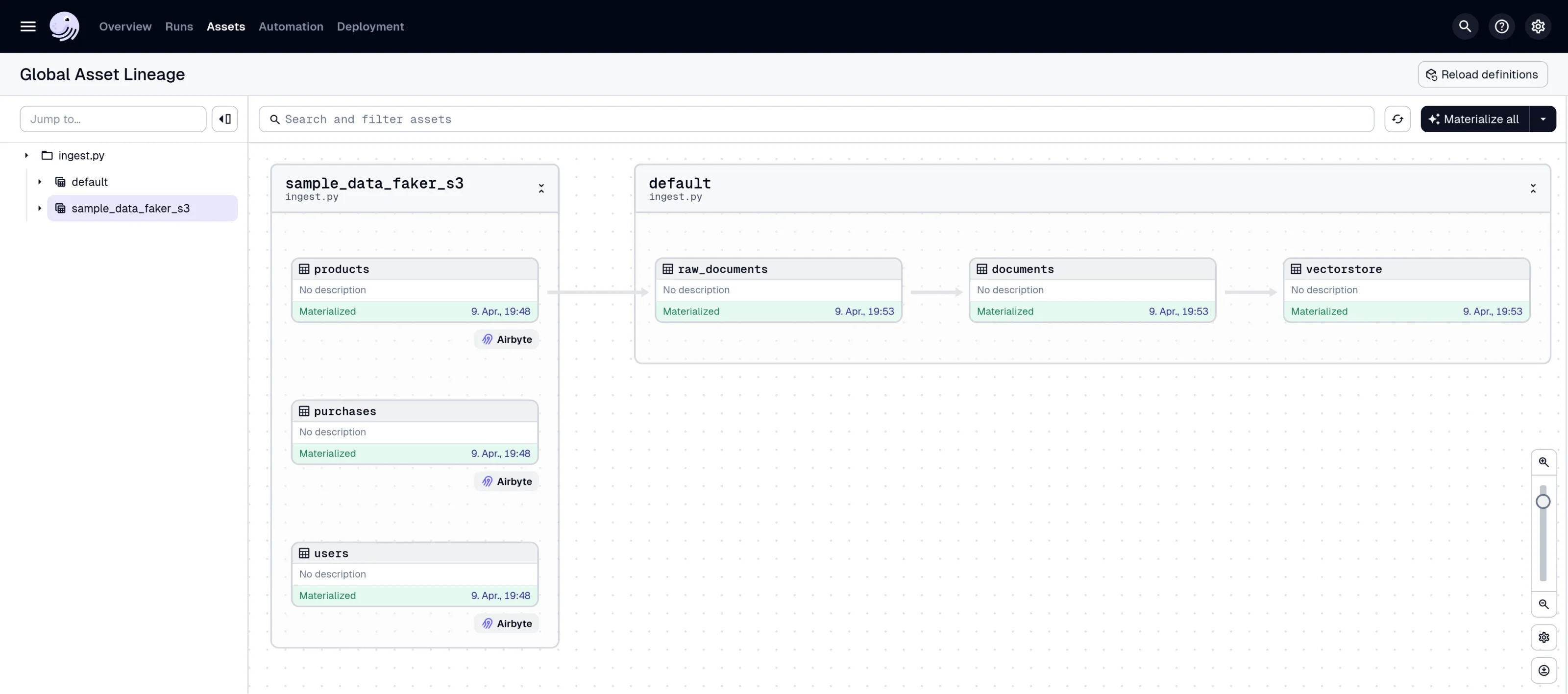
1. Materialisierung der Assets in Dagster
Nachdem wir die Dagster Web-UI unter http://127.0.0.1:3000 geöffnet haben, navigieren wir zu den „Asset Groups“. Hier sehen wir die definierten Assets Ihrer Pipeline. Nun klicken wir auf „Materialize all“, um, na ja, alle Assets zu materialisieren.
Dieser Vorgang umfasst mehrere Schritte:
- Auslösen eines Airbyte-Syncs für die konfigurierte Connection. Die Daten werden vom Fake-Shop in die Datenbank transportiert (
sample_data_faker)
Wenn man nebenbei das Airbyte-Fenster offen hat, kann man sehen wie die Connection synchronisiert, während dieser Schritt ausgeführt wird. - Laden des Airbyte-Streams aus der Datenbank zu Dagster (
raw_documents) - Vorbereitung der Daten zur Vektorisierung (
documents) - Vektorisierung und Speicherung in der Vektordatenbank (
vectorstore).
Dieser Schritt erstellt eine Vektordatenbank im Unterverzeichnisvectorstore.
Verfolgen wir nun also den Fortschritt in der Dagster-UI. Nach erfolgreicher Materialisierung werden alle Assets grün markiert:
Ein paar technische Hintergründe …
Der Airbyte-Sync: Hier wird die Verbindung zu Airbyte hergestellt und alle bekannten Airbyte-Streams als Assets mit Präfix airbyte_asset angelegt.
airbyte_instance = AirbyteResource(
host="localhost",
port="8000",now)
airbyte_assets = load_assets_from_airbyte_instance(
airbyte_instance,
key_prefix="airbyte_asset",
)
Das Asset raw_documents: Wenn dieses Asset materialisiert wird, wird eine Datenbank-Verbindung erstellt und die Tabelle products ausgelesen. Diese Daten werden für die weitere Verarbeitung zurückgegeben. Die Annotation @asset besagt, dass raw_documents abhängig von airbyte_asset/products ist.
stream_name = "products"
asset_name = "products"
database_url = "postgresql+psycopg://airbyte:airbyte@localhost:5432/postgres"
airbyte_loader = SQLDatabaseLoader(
db=SQLDatabase.from_uri(database_url),
query=f"SELECT * FROM {stream_name}",
)
@asset(
non_argument_deps={AssetKey(["airbyte_asset", asset_name])},
)
def raw_documents(context):
docs = airbyte_loader.load()
context.log.debug(f"Loaded {len(docs)} documents from Airbyte source.")
return docs
Als nächstet gibt es das Asset documents: Die Daten werden in für die Vektorisierung geeignete Chunks zerteilt. Das Asset documents hängt von raw_documents ab.
@asset
def documents(context, raw_documents):
docs = RecursiveCharacterTextSplitter(chunk_size=1000).split_documents(
raw_documents
)
context.log.debug(f"Created {len(docs)} documents.")
return docs
Bleibt noch das Asset vectorstore: Dieser Schritt erstellt eine Vektordatenbank im Unterverzeichnis vectorstore. Das Asset vectorstore hängt von documents ab.
@asset
def vectorstore(documents):
vectorstore_contents = FAISS.from_documents(documents, OpenAIEmbeddings())
vectorstore_contents.save_local("vectorstore")
Durch folgenden Definition werden übrigens die Assets in Dagster bekannt gemacht:
defs = Definitions(assets=[airbyte_assets, raw_documents, documents, vectorstore])
2. Abfrage der Daten mit dem Query-Tool
Nachdem die Daten verarbeitet und in der Vektordatenbank gespeichert wurden, können wir sie mit unserem Query-Tool python query.py abfragen:
Das Tool startet eine interaktive Konsole, in der wir Fragen zu den verarbeiteten Daten stellen können. Beispielsweise:
- „Was verkaufen wir in unserem Shop?“
- „Gibt es Artikel im Preisbereich von 50-100 Euro?“
Das LLM nutzt dabei die Vektordatenbank, um kontextbezogene und präzise Antworten zu generieren.
AI Data Pipelines 2025
Wir haben nun einen funktionierenden Ausgangspunkt für die Weiterentwicklung in verschiedenen Richtungen. So könnten wir zum Beispiel Datenquellen erweitern, und beispielsweise weitere Datenquellen aus dem Airbyte Connector Catalog einbinden oder eigene APIs oder Fake-APIs wie Fake Store API und DummyJSON anbinden, z. B. mit Hilfe von Airbytes Connector Builder.
Außerdem können wir die AI nutzen. So könnten wir im Workflow LLMs zur Datenbereinigung oder -anreicherung einsetzen oder eine Chat-History für komplexere Konversationen implementieren. Außerdem könnten wir Agenten entwickeln, die selbstständig mit den Daten arbeiten.
Zu guter Letzt bleibt uns natürlich noch, die Produktionsreife zu erreichen. Dazu gehört unter anderem, Dagster in Kubernetes zu betreiben oder alternative Vector Stores wie PgVector oder Pinecone zu verwenden. Und, um die Sache allgemein zugänglicher zu gestalten, sollten wir Open WebUI als webbasierten Ersatz für query.py verwenden.
Schreibe einen Kommentar