
My main motivation for writing a blog post about that topic can be summarized in a single sentence
“The developers produce software that the customer really needs!”
It sounds simple but means that developers require appropriate information in order to deliver output that corresponds exactly to the input that the customer provides, or rather to what the customer really needs. Based on many observations I think the input which is given is influenced by communication paths that vary according to the project.
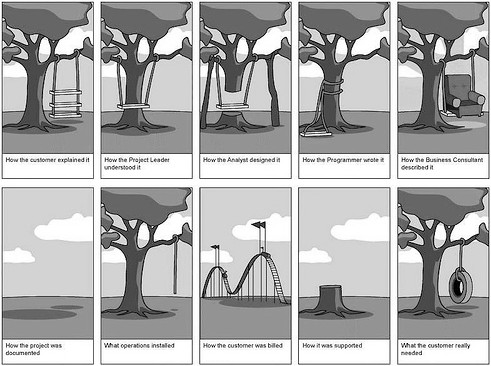
Fig. 1 What the customer really needed
Introduction:
As developers we must fight against these pitfalls and try to handle the various information flows in our daily business. Unfortunately it is quite common that inappropriate input information leads to decreased productivity and sometimes to an output which has nothing to do with what the customer originally had in mind. This blog post covers that issue and tries to give an overview based on a real project. Additionally, the underlying Scrum setup has been analyzed which includes roles and their information paths to understand the individual character.
My intention is to help you get some solutions for the future.
Before we start, let us take a look at the theoretical base.
Cover the Scrum framework:
Scrum has been very popular in the last few years and many large projects have been developed with the help of the Scrum process. Scrum consists of several roles with their related tasks. The next paragraph gives an overview about the common roles to provide some background knowledge for the following sections.
We start with the customer who provides requirements for the team. Normally he is involved in writing user stories together with the product owner. The product owner as counterpart is responsible for taking care of the business value and works closely with the customer. Additionally, there is the product owner proxy, he is not a defined role by the Scrum process itself, but in practice often helpful to support the product owner handling tasks like writing user stories and managing the backlog. The scrum master as a leader role is responsible to share the agile spirit across the team and acts as a teacher and rolemodel for all the members, encouraging them to adopt the agile principles. Last but not least our developers who implement the cool stuff for the users with their awesome technical experience.
Between these roles a lot of information exchange is happing in our daily business. Senders and receivers share details in speech and written language. Ok, now, based on a real life scenario, let us have a closer look at existing information paths and their importance.
Analyzes to find information paths:
Kurze Unterbechung
Das ist dein Alltag?
Keine Sorge – Hilfe ist nah! Melde Dich unverbindlich bei uns und wir schauen uns gemeinsam an, ob und wie wir Dich unterstützen können.
Initially we try to define an overview of roles, their tasks, information paths and their intensity. It is based on self observations and contains my first ideas to understand such a complex system. See Fig. 2 with the first initial view.
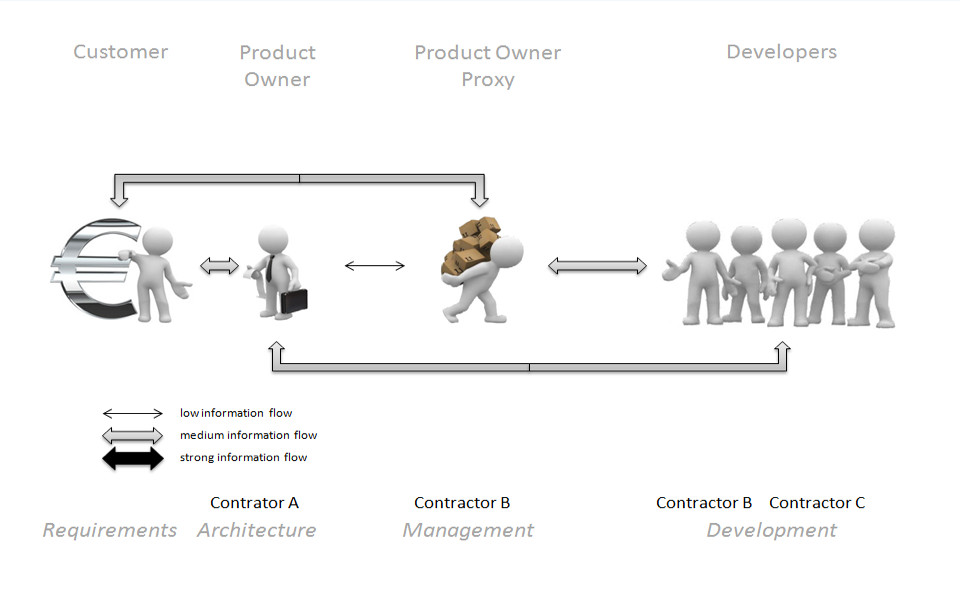
Fig. 2 Visualize the approach of roles and information paths for the project
In Fig. 2 above you can see the roles which are part of the scrum framework. In the middle you can see some human icons to show the roles and their information paths that are divided into several strength levels e.g. strong, medium and low. On the figure below, the contractors and their associated tasks are visualised.
In our project the customer (sender) delivers information (requirements) to the product owner (receiver) so that he can interpret these information and develop his own ideas. In the next step the product owner acts as a sender and passes his interpreted information to the product owner proxy, so that he in return is able to create a proper user story which will be the base on which the developers will implement the code.
That should give a first impression of our basic information flow. Please handle this information as a simple abstract of the whole information process. At this point these details should suffice to explain the next steps.
While I was preparing that figure, I thought about a pattern which gave me the possibility to combine details and produce a single idea. My intention was to find things that are identical and how I can determine key points of the process.
Here is my observation result.
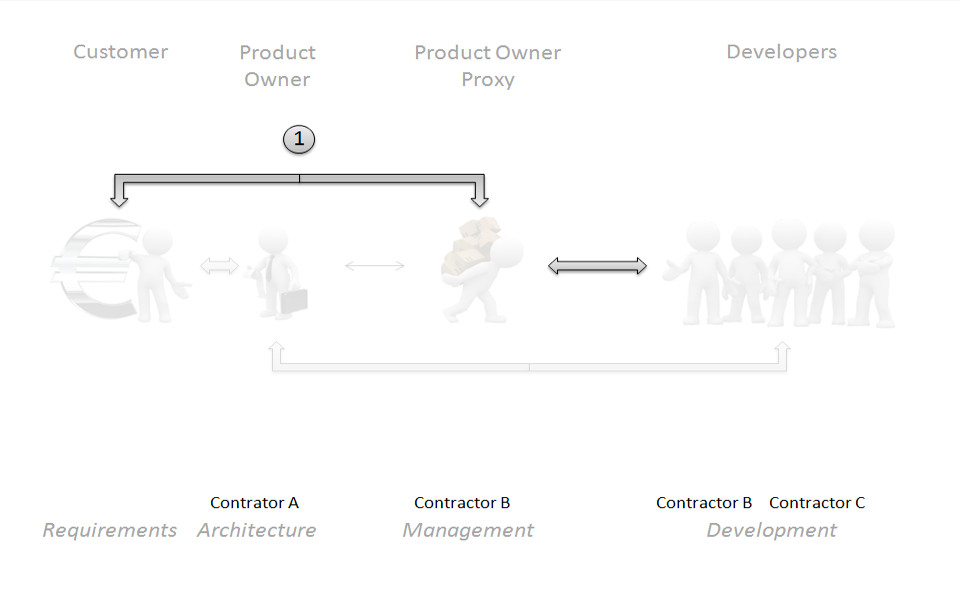
Fig. 3 The customer – product owner proxy – developer path
My first result see Fig. 3 shows the first of two main information paths that define the main information flow in our project which is called the customer – product owner proxy – developer path. In this path there are three roles involved, the customer, product owner proxy and our developers. The customer (sender) delivers requirements while the product owner proxy (receiver) creates the user story based on this input and the developers (receiver) produce their own set of ideas to implement code.
Ok let us have a look at the second main information flow in our project.
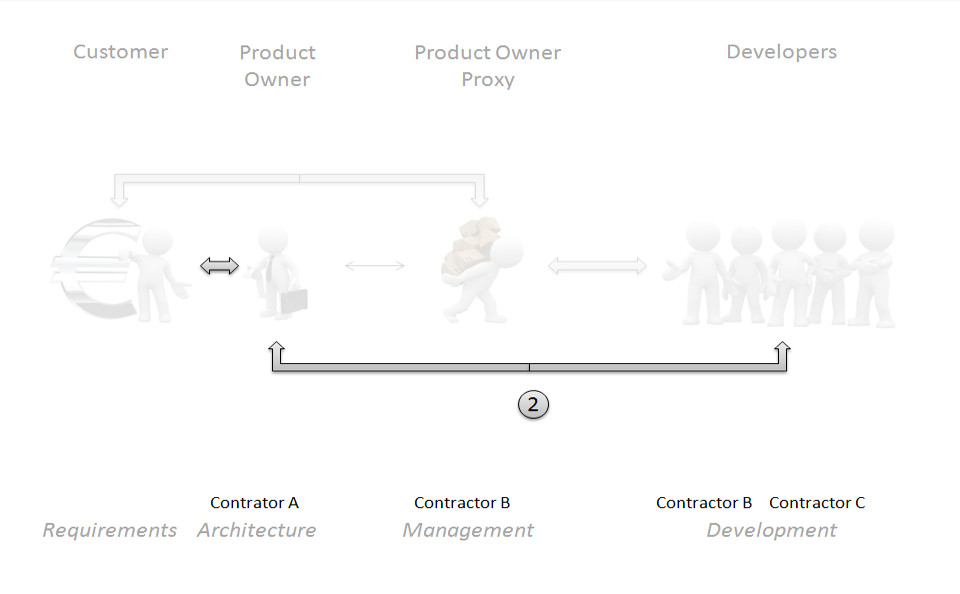
Fig. 4 The customer – product owner – developer path
Fig. 4 visualizes the second main information path. Here you can see the customer – product owner – developer information path. Similar to the first path our customer (sender) is responsible for requirements and work packages. He delivers information to the product owner (receiver) who accepts these information and creates his own ideas for that feature. At the last position of that chain our developers implement features and discuss requirements with the product owner. He acts as a key knowledge holder with deep information details in every area of our software product. It is very important for us to get customer and technical requirements from a single information source.
At this point we have two main information paths in our project that need to be handled. I have asked myself what are the most important impacts that result from this constellation. What are the pitfalls, how can we handle these things and what happens when information is delivered through different paths. Let me try to explain my ideas and findings.
Send the same information through different paths at the same time:
Let us remember our two paths. We can see that the customer is the initial source for requirements but he has two receivers. Firstly, the product owner and secondly the product owner proxy. We can assume that he sends a single information at the same time and the product owner and product owner proxy receive that information to handle it in their own way. Normally, different persons need different time for interpreting information, depending on their workload during the daily business, their previous experiences or other individual properties.
However, it is only the first part because our information needs to be sent also to the developers. Let us assume that the product owner and product owner proxy send their information exactly at the same time, so that the developers get the information twice. Perhaps, it will confuse the developers but they will probably ignore one of them in order to carry on with their daily business.
Ok that was the simple case. Let us see what will happen when we change the transmission time.
Send the same information through different paths at different times:
Remember our customer who sends information to the product owner and product owner proxy. Both develop their own ideas and forward those to the developers. We can assume that between our sender transmission time is a greater time difference then in the case before. Let us try to explain what will happen.
The first information from our product owner has been received by our developers and they start to interpret what was probably meant. After a short time based on that ideas they start to work. A few minutes later the second different information from the product owner proxy arrives – what will happen now?
Probably the developers react confused and they try to compare both information. I could imagine that they start to discuss the later one and then decide according to the earlier one what are the differences. Maybe the result depends on the information complexity or how much of the implementation was already completed. Nevertheless, they must reorder their mindset and integrate the new information or simply discard it. Perhaps, when the essence of both information is exactly the same I could imagine that the later information is simply moved to the trash.
We looked at two cases that were based on identical information and only varied in their sending time.
Now, let us see what happens if information are linked together. Which means that we need information for another user story that is influenced by our current user story.
Send interdependent information through different paths at the same time:
Now, we increase the complexity level and share interdependent information we can not process individualy. With respect to the previous cases we can not resolve such pitfalls when we simply discard additional information because we must always integrate that new information. The later we receive this depend information the more difficult it will be.
We know three different types of interdependence. The simplest form is containment which means a hierarchical structure of dependencies. Task, sub-task and sub-sub-task are typical items. The next level is order interdependence which means that one task depends on another task. In most cases a task must be completed before another task can be started. Finally, the hardest interdependence refers to overlap tasks. Overlapping stories are very complex for us because we tend to confuse our mind when things are covered more than once. When we know containment, order or overlap interdependent information we can pay attention to it and react as best we can. The best solution to fix such interdependence is to write user stories that do not depend on other stories.
Send interdependent information through different paths at different times:
The hardest things to handle are information flows based on this kind of complexity. Please imagine a scenario in which our developer receives an information that depends on another information and he does not know everything about it. He interprets that information and starts to work. After a short time when he is almost done he receives the second information that is related on the earlier one, and changes the first information. The developer must refactor his current code and integrate the second part. How many time this will cost depends on the amount of tasks that have been already completed, the type of tasks and the level of interdependence. We hope that every information is already present to complete the task if it is not he must stop working at the current task, sta
This blog post tries to give an overview of information paths in IT-projects and their possible complexity. Based on a real use case information paths were analyzed. Scrum with roles and tasks build the underlaying framework. The major goal was to find the main paths on which information is exchanged and to detect the possible pitfalls. Different scenarios were discussed to get a deeper insight. The next step is to implement solutions for all these pitfalls in order to make the daily business during our project a little less painful.
References
Fig.1: http://lh4.ggpht.com/_X3UnUrT0AtM/SWd8vQwbhwI/AAAAAAAAGeo/TGaUEpjwagU/Picture%205.png
Fig.2, Fig.3, Fig.4: Customer: http://www.schul-webportal.de/attachment/0/200×200-max-SmartKomm-Maennchen-Euro.jpg
ProductOwner: http://www.superinvest.de/grafiken/maennchen5.jpg
ProductOwnerProxy: http://sphotos-a.xx.fbcdn.net/hphotos-ash4/c0.0.403.403/p403x403/304610_491409524204714_1442779379_n.jpg
Developer: http://www.dison.be/data/images/commissions/image_preview

Schreibe einen Kommentar