

In diesem Artikel beschäftigen wir uns mit der Entstehung der verschiedenen Datenarchitekturen; dem Fundament digitaler Unternehmen.
Daten sind zum wertvollsten Gut vieler Unternehmen avanciert. Sie werden heute als der entscheidende Wirtschaftsfaktor des 21. Jahrhunderts betrachtet – insbesondere durch ihren direkten Einfluss auf die Entwicklung und Leistungsfähigkeit künstlicher Intelligenz, die zum Innovationstreiber der Gegenwart geworden ist. Deshalb gewinnt die systematische Organisation dieser Ressource zunehmend an Bedeutung.
Datenarchitektur bezeichnet den strukturierten Rahmen, der definiert, wie Daten gesammelt, gespeichert, transformiert, verteilt und genutzt werden. Sie umfasst die Modelle, Richtlinien, Regeln und Standards, die bestimmen, welche Daten erfasst werden und wie sie im gesamten Datenlebenszyklus eines Unternehmens gespeichert, integriert und verwendet werden.
Anders als bei Softwarearchitekturen, die sich primär mit der Strukturierung von Anwendungskomponenten befassen, konzentriert sich die Datenarchitektur auf die Daten selbst – ihre Struktur, ihre Beziehungen untereinander und die Infrastrukturen zu ihrer Verwaltung. Eine durchdachte Datenarchitektur bildet das Fundament für sämtliche datengetriebenen Geschäftsprozesse und Entscheidungen.
Kurze Unterbrechung – Datenarbeit, die dein Business beschleunigt
Skalierbare Datenarchitekturen
Wir verbinden Daten, Tools und Menschen in robusten Pipelines und modernen Architekturen, damit deine Daten schnell nutzbar, zuverlässig und zukunftsfähig sind. Durch klare Data-Ownership, automatisierte Qualitätssicherung und produktorientierte Datenprodukte eliminieren wir Bottlenecks und schaffen so die Grundlage für datengetriebene Entscheidungen und KI-Projekte mit echtem Impact.
Die Relevanz von Datenarchitekturen in Unternehmen
Die strategische Bedeutung einer durchdachten Datenarchitektur für Unternehmen könnte kaum wichtiger sein. Sie erfüllt mehrere kritische Funktionen:
Erstens ermöglicht sie eine konsistente und zuverlässige Datenbasis für Geschäftsentscheidungen. Unternehmen, die auf einer soliden Datenarchitektur aufbauen, können präzisere Analysen durchführen und fundierte Entscheidungen treffen. In der AI-getriebenen Wirtschaft bestimmt die Qualität und Verfügbarkeit der Daten direkt, inwieweit Unternehmen von transformativen AI-Anwendungen wie automatisierten Prognosen, intelligenter Prozessoptimierung oder neuen generativen Systemen profitieren können.
Zweitens fördert eine gute Datenarchitektur die Agilität und Anpassungsfähigkeit. In einer Zeit, in der sich Märkte und Technologien rasant wandeln, können Unternehmen mit flexiblen Datenarchitekturen neue Anforderungen schneller integrieren und auf veränderte Bedingungen reagieren.
Drittens bildet sie die Grundlage für Compliance und Datensicherheit. Mit der zunehmenden Regulierung des Datenumgangs, etwa durch die DSGVO in Europa, wird eine durchdachte Datenarchitektur zum entscheidenden Faktor für die rechtskonforme Verarbeitung sensibler Informationen.
Viertens definiert die Datenarchitektur maßgeblich den Erfolg von AI-Projekten. Studien zeigen, dass bis zu 80 % der Projektzeit in AI-Initiativen für die Datenaufbereitung aufgewendet werden. Eine durchdachte Datenarchitektur, die für Datenkonsistenz, -qualität und leichte Zugänglichkeit sorgt, bildet die unverzichtbare Grundlage für trainierbare AI-Modelle und reduziert gleichzeitig die häufigste Ursache für das Scheitern von AI-Projekten: mangelhafte oder unzureichend strukturierte Daten.

AI Data Pipelines
Dein AI-Potenzial bleibt ungenutzt weil deine AI-Lösung in weniger als 90 Prozent die Antwort liefert, die in deinen Wissensquellen existiert?
Wenn deiner AI also mal wieder die richtigen Daten fehlen, haben wir hier genau das richtige Webinar für dich: AI Data Pipelines. Das erwartet dich:
- Aufbau einer vollständigen Dokumenten-Pipeline mit einer beispielhaften SharePoint-Integration
- Automatisierte Extraktion und Strukturierung von Dokumenteninhalten
- Speicherung in Vektordatenbanken für semantische Suche
- Wie auch aus Diagrammen und Bildern die richtigen und wichtigen Informationen gezogen werden
- Integration mit Large Language Models (LLMs) für intelligente Anwendungen
- u.v.m
Die Evolution der Datenarchitekturen spiegelt die Entwicklung der Unternehmens-IT wider: von den frühesten hierarchischen Datenbanken über relationale Systeme bis hin zu modernen Cloud-basierten und verteilten Architekturen für Big Data. Jede neue Entwicklung brachte ihre eigenen Herausforderungen und Möglichkeiten mit sich. Die explosionsartige Entwicklung im Bereich der künstlichen Intelligenz hat die Anforderungen an Datenarchitekturen fundamental verändert – von der Notwendigkeit massiv paralleler Verarbeitung für AI-Training bis hin zu Echtzeit-Datenflüssen für adaptive Intelligenz in Geschäftsprozessen.
Big Data und die 6 V’s
Zwischen 2010 und 2020 ist die weltweit generierte Datenmenge um das 50-fache gewachsen, und dieser Trend beschleunigt sich weiter. Um dieses komplexe Phänomen besser zu verstehen, hat sich das Konzept der „6 V’s“ etabliert – sechs charakteristische Dimensionen, die Big Data von herkömmlichen Datensammlungen unterscheiden und seine besonderen Herausforderungen und Chancen definieren. Die 6 V’s von Big Data bilden ein konzeptionelles Framework, um die fundamentalen Herausforderungen und Chancen zu verstehen, die mit der digitalen Datenexplosion einhergehen. Sie verdeutlichen, warum traditionelle Datenverarbeitungsansätze nicht ausreichen und warum neue Technologien, Methoden und Denkweisen erforderlich sind.
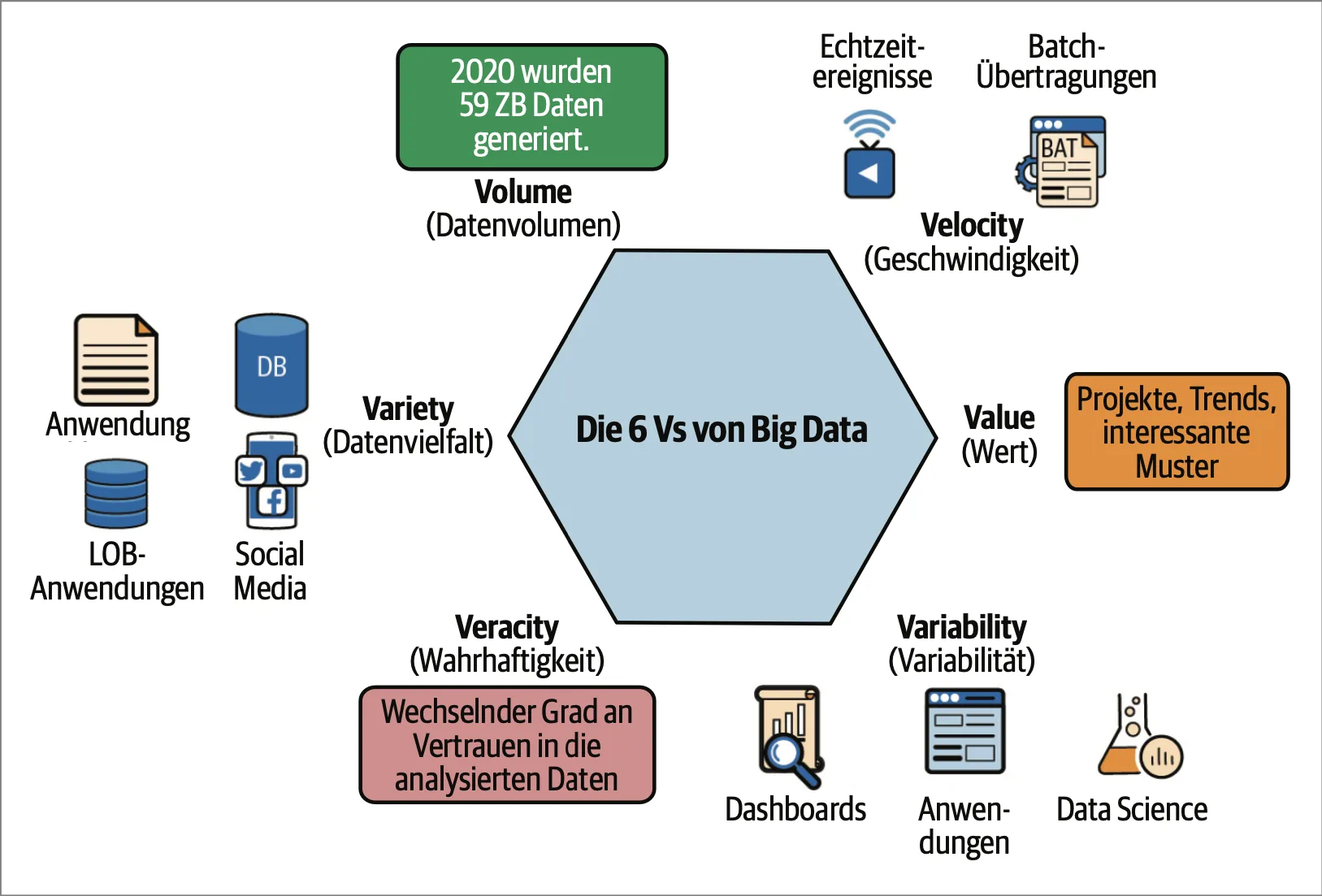
Volume: Die Explosion der Datenmengen
In der Big-Data-Ära explodieren die Datenmengen förmlich. Was früher als große Datenbank galt, erscheint heute geradezu winzig:
- Jede Minute werden weltweit etwa 500 Stunden Videomaterial auf YouTube hochgeladen
- Facebook verarbeitet täglich über 500 Terabyte an Daten
- Moderne Wetterdienste generieren durch ihre Satelliten und Sensornetzwerke mehrere Terabyte pro Tag
- Ein einzelnes autonomes Fahrzeug erzeugt bis zu 4 Terabyte Daten pro Tag
Diese schiere Masse an Daten überfordert klassische Datenbanken und Analysesysteme. Die technologische Antwort sind verteilte Speicher- und Verarbeitungssysteme, die auf Tausenden von Rechnern parallel arbeiten können. Paradigmen wie MapReduce ermöglichen es, Berechnungen dorthin zu bringen, wo die Daten liegen, statt umgekehrt.
Die Herausforderung des Volumes liegt nicht nur in der Speicherung, sondern vor allem in der effizienten Organisation, dem schnellen Zugriff und der wirtschaftlichen Verwaltung dieser enormen Datenmengen. Cloud-Technologien haben hier einen entscheidenden Beitrag geleistet, indem sie elastische Speicherlösungen bieten, die mit den Anforderungen mitwachsen können.
Velocity: Wenn jede Millisekunde zählt
Big Data strömt mit atemberaubender Geschwindigkeit in unsere Systeme:
- Die New Yorker Börse generiert etwa 1 Terabyte an Handelsdaten pro Tag
- Twitter verarbeitet über 500 Millionen Tweets täglich, etwa 6.000 pro Sekunde
- Moderne Telekommunikationsnetze müssen Millionen von Verbindungen in Echtzeit überwachen
- IoT-Sensornetzwerke senden kontinuierlich Daten an zentrale Systeme
Diese Geschwindigkeit erfordert neue Verarbeitungsparadigmen jenseits des klassischen Batch-Processings. Stream-Processing-Technologien wie Apache Kafka, Spark Streaming oder Apache Flink ermöglichen die kontinuierliche Verarbeitung von Datenströmen in nahezu Echtzeit.
Die Herausforderung besteht darin, die richtige Balance zwischen sofortiger Reaktionsfähigkeit und tiefgehender Analyse zu finden. Während manche Entscheidungen innerhalb von Millisekunden getroffen werden müssen (etwa bei der Betrugserkennung im Zahlungsverkehr), erfordern andere Anwendungen eine umfassendere, aber zeitlich weniger kritische Verarbeitung.
Variety: Die Vielfalt der Datenformate
Die Homogenität strukturierter Datenbanken gehört der Vergangenheit an. Big Data umfasst ein breites Spektrum an Datentypen:
- Strukturierte Daten in traditionellen Datenbanktabellen (nur etwa 20 % aller Daten)
- Semi-strukturierte Daten wie XML, JSON oder Log-Dateien
- Unstrukturierte Texte aus E-Mails, Dokumenten, Social-Media-Beiträgen
- Multimediale Inhalte wie Bilder, Audio- und Videoaufnahmen
- Grafendaten, die komplexe Netzwerke und Beziehungen abbilden
Diese Vielfalt erfordert flexible Datenmodelle und polyglotte Persistenz – die Fähigkeit, mit verschiedenen Speichertechnologien für unterschiedliche Datentypen zu arbeiten. Die Entwicklung von NoSQL-Datenbanken wie MongoDB (dokumentenorientiert), Neo4j (graphenorientiert) oder HBase (spaltenorientiert) ist eine direkte Antwort auf diese Herausforderung.
Besonders wichtig ist die Fähigkeit, strukturierte und unstrukturierte Daten zu integrieren, um ein ganzheitliches Bild zu erhalten. Moderne Data Lakes bieten hierfür einen flexiblen Ansatz, indem sie Rohdaten in ihrem Originalformat speichern und erst bei Bedarf transformieren.
Veracity: Der Kampf um Datenqualität
Mit wachsendem Volumen und zunehmender Vielfalt steigt die Herausforderung, die Qualität und Vertrauenswürdigkeit der Daten sicherzustellen:
- Unternehmensdaten enthalten durchschnittlich 15-25 % Fehler oder Inkonsistenzen
- Sensordaten können durch Umgebungseinflüsse oder Gerätedefekte verfälscht sein
- User-generierte Inhalte enthalten subjektive Verzerrungen oder Falschinformationen
- Automatisch erfasste Daten leiden unter systematischen Fehlern durch ihre Erfassungsmethoden
Die Sicherstellung der Datenqualität erfordert mehrschichtige Ansätze:
- Preventive Maßnahmen: Validierungsregeln und Datengovernance bei der Erfassung
- Detective Maßnahmen: Automatische Anomalieerkennung und Konsistenzprüfungen
- Corrective Maßnahmen: Datenbereinigung, Imputation fehlender Werte, Deduplizierung
Besonders wichtig ist die Metadatenverwaltung, die Herkunft, Bedeutung und Qualitätsmerkmale der Daten transparent macht und so die Grundlage für fundierte Entscheidungen schafft.
Value: Der eigentliche Zweck von Big Data
Alle technischen Herausforderungen von Big Data rechtfertigen sich nur durch den Wert, den die Daten generieren können:
- Detaillierte Kundenanalysen ermöglichen personalisierte Angebote, die die Conversion-Rate um 5-8 % steigern können
- Predictive Maintenance reduziert Ausfallzeiten in der Fertigung um bis zu 50 %
- Intelligente Verkehrssteuerungssysteme können Staus um bis zu 25 % reduzieren
- Präzisionsmedizin auf Basis genetischer und klinischer Daten kann Behandlungserfolge dramatisch verbessern
Der Weg von Rohdaten zum Wert ist jedoch komplex und erfordert eine Kombination aus technischem Know-how, Domänenwissen und analytischer Kreativität. Data Scientists spielen hier eine Schlüsselrolle, indem sie fortschrittliche Analysemethoden wie Maschinelles Lernen und Künstliche Intelligenz einsetzen, um aus den Daten actionable insights zu generieren.
Entscheidend ist dabei das Verständnis, dass der Wert nicht in den Daten selbst liegt, sondern in den Entscheidungen und Handlungen, die sie ermöglichen. Big Data ist kein Selbstzweck, sondern ein Mittel zur Transformation von Unternehmen und Gesellschaft.
Variability: Die dynamische Natur von Big Data
Das sechste V – Variability – beschreibt die Veränderlichkeit und Unbeständigkeit von Big Data:
- Datenströme unterliegen starken saisonalen und situationsbedingten Schwankungen
- Die Bedeutung und Interpretation von Daten kann sich mit dem Kontext ändern
- Nutzerverhalten und damit verbundene Datenmuster entwickeln sich dynamisch
- Unvorhergesehene Ereignisse können zu plötzlichen Datenspitzen oder -veränderungen führen
Diese Variabilität erfordert adaptive Systeme, die sich dynamisch an verändernde Bedingungen anpassen können:
- Elastische Cloud-Infrastrukturen, die bei Bedarfsspitzen automatisch skalieren
- Adaptive Analysemodelle, die kontinuierlich neu trainiert werden
- Anomalieerkennungssysteme, die ungewöhnliche Veränderungen identifizieren
- Robust gestaltete Datenarchitekturen, die unerwartete Datenformen verarbeiten können
Ein besonderer Aspekt der Variabilität ist die semantische Ambiguität in natürlichsprachlichen Daten. Natural Language Processing (NLP) muss mit mehrdeutigen Begriffen und kontextabhängigen Bedeutungen umgehen können, um wertvolle Erkenntnisse aus Texten zu extrahieren.
Die vorgestellten Datenarchitekturen repräsentieren den aktuellen Stand der Technik und bieten vielfältige Möglichkeiten zur Organisation und Nutzung von Unternehmensdaten. Doch zwischen der theoretischen Betrachtung dieser Architekturen und ihrer erfolgreichen Implementierung in der Unternehmenspraxis liegt ein komplexer Entscheidungs- und Anpassungsprozess.
Kurzer Exkurs
ACID-Transaktionen
| Eigenschaft | Erläuterung |
|---|---|
| Atomizität (engl. Atomicity) | Die in einer Transaktion zusammengefassten Einzelanweisungen werden als unteilbare (atomare) Einheit behandelt, d. h. vollständig oder gar nicht ausgeführt. Tritt während der Ausführung ein Fehler auf, müssen die bereits bearbeiteten Teile der Transaktion rückabgewickelt werden. |
| Konsistenz (engl. Consitency) | Ergebnis einer Transaktion ist immer ein konsistenter Datenbestand. Für den Fehlerfall während der Transaktionsausführung bedeutet dies, dass auch die Rückabwicklung wieder in einen konsistenten Datenzustand mündet. |
| Isolation (engl. Isolation) | Die Ausführung einer Transaktion soll unbeeinflusst von der Ausführung anderer Transaktionen stattfinden. D. h., die von einer Transaktion bearbeiteten Datenelemente dürfen während der Transaktionsausführung von keiner anderen Transaktion bearbeitet werden. |
| Dauerhaftigkeit (engl. Durability) | Die bei erfolgreicher Abwicklung vorgenommenen Änderungen am Datenstand sind dauerhaft (persistent), d. h. sie gehen z. B. auch bei einem Systemausfall nicht wieder verloren. |
Datenarchitekturen im Überblick
Schauen wir uns nun einmal die verschiedenen Datenarchitekturen etwas genauer an und werfen dabei einen Blick auf deren Vor- und Nachteile.
Relationales Data Warehouse (RDW)
Ein relationales Data Warehouse ist eine strukturierte Datenbankarchitektur, die insbesondere für die Analyse und Berichterstattung von Unternehmensdaten entwickelt wurde. In den 1980er Jahren wurde das Konzept maßgeblich von Bill Inmon, auch bekannt als der „Vater des Data Warehouse“, geprägt.
Diese Architektur ermöglicht die Integration von Daten aus verschiedenen operativen Systemen und organisiert sie in einem klar strukturierten Format, meist in Form von Tabellen, die durch Beziehungen miteinander verknüpft sind (Primär- und Fremdschlüssel). Ein relationales Data Warehouse ist bekannt für seine hohe Datenintegrität und Konsistenz, die durch umfassende ETL-Prozesse (Extract, Transform, Load) sichergestellt werden. Die Verwendung von SQL als Abfragesprache macht es zu einem bewährten Werkzeug für Unternehmen, die komplexe Datenanalysen durchführen möchten.
Dennoch gibt es Herausforderungen im Umgang mit unstrukturierten Daten, was diese Architektur in einer modernen, dynamischen Datenlandschaft an ihre Grenzen bringt.
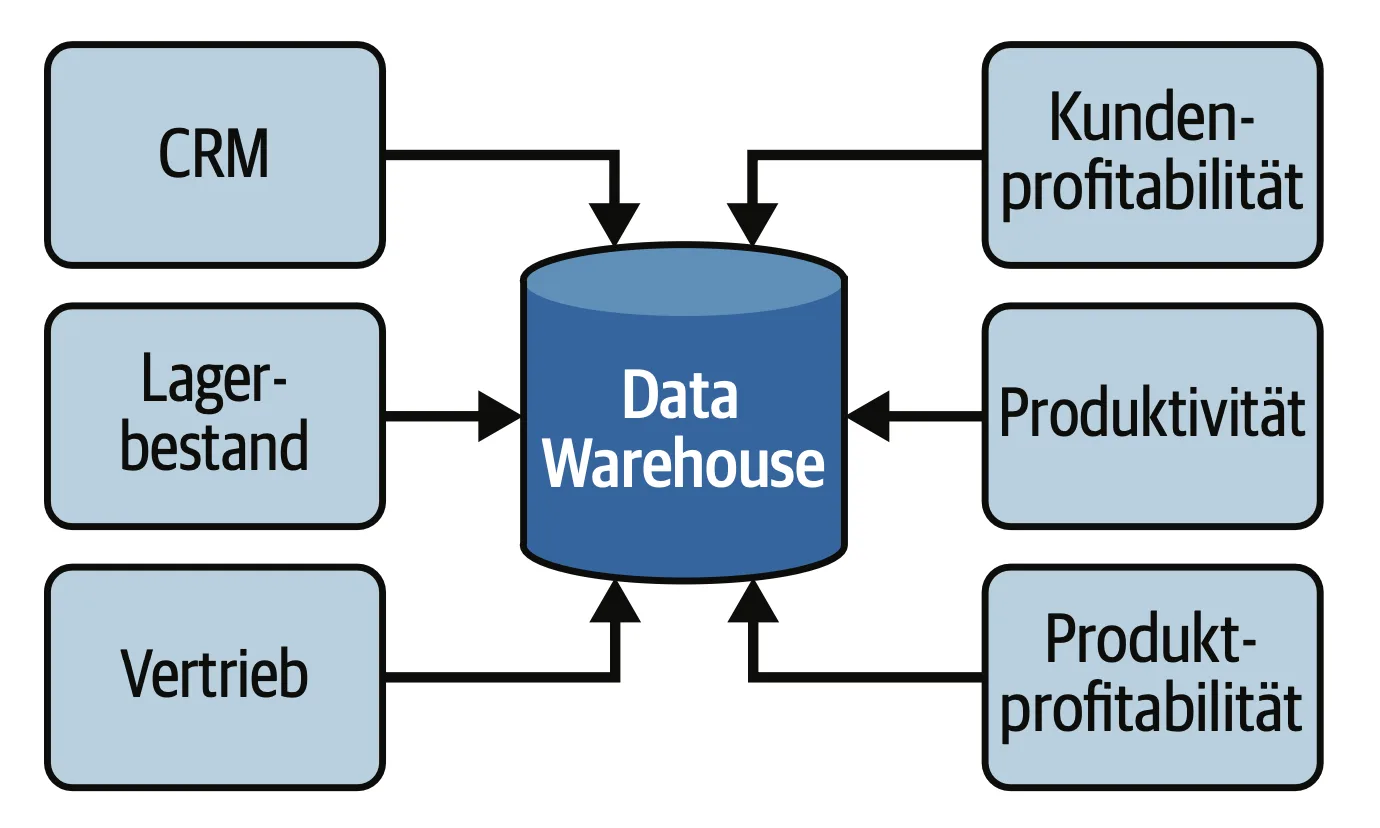
Vorteile
- Hohe Datenintegrität: Durch definierte Schemata und Beziehungen zwischen Tabellen wird die Konsistenz der Daten garantiert.
- Bewährte Technologie: Relationale Datenbanken sind weit verbreitet, gut dokumentiert und bieten umfangreiche SQL-Abfragemöglichkeiten.
- Effiziente Abfragen: Optimiert für strukturierte Datenanalysen, ermöglicht es schnelle und präzise Abfragen, die für Business Intelligence erforderlich sind.
Nachteile
Data Lake
Der Data Lake hat sich als eine revolutionäre Antwort auf die gestiegenen Anforderungen der Big-Data-Welt etabliert. Im Gegensatz zu einem relationalen Data Warehouse speichert ein Data Lake Daten in ihrem Rohformat, unabhängig von Struktur oder Schema.Diese Flexibilität ermöglicht es Unternehmen, große Mengen an strukturierten, halb-strukturierten und unstrukturierten Daten zu speichern. Das Konzept wurde um 2010 von James Dixon ins Leben gerufen und erlangte schnell an Popularität.
Data Lakes sind ideal für Datenexperimente und explorative Analysen, da sie Daten schnell und kostengünstig speichern. Technologien wie Apache Hadoop und Spark unterstützen die Verarbeitung und Analyse großer Datenmengen. Jedoch bringt der offene Zugang auch Herausforderungen in Bezug auf Datenqualität und Governance mit sich; deshalb sind geeignete Managementpraktiken notwendig, um sicherzustellen, dass die Daten für Data Scientists und Analysten nützlich und zuverlässig sind.
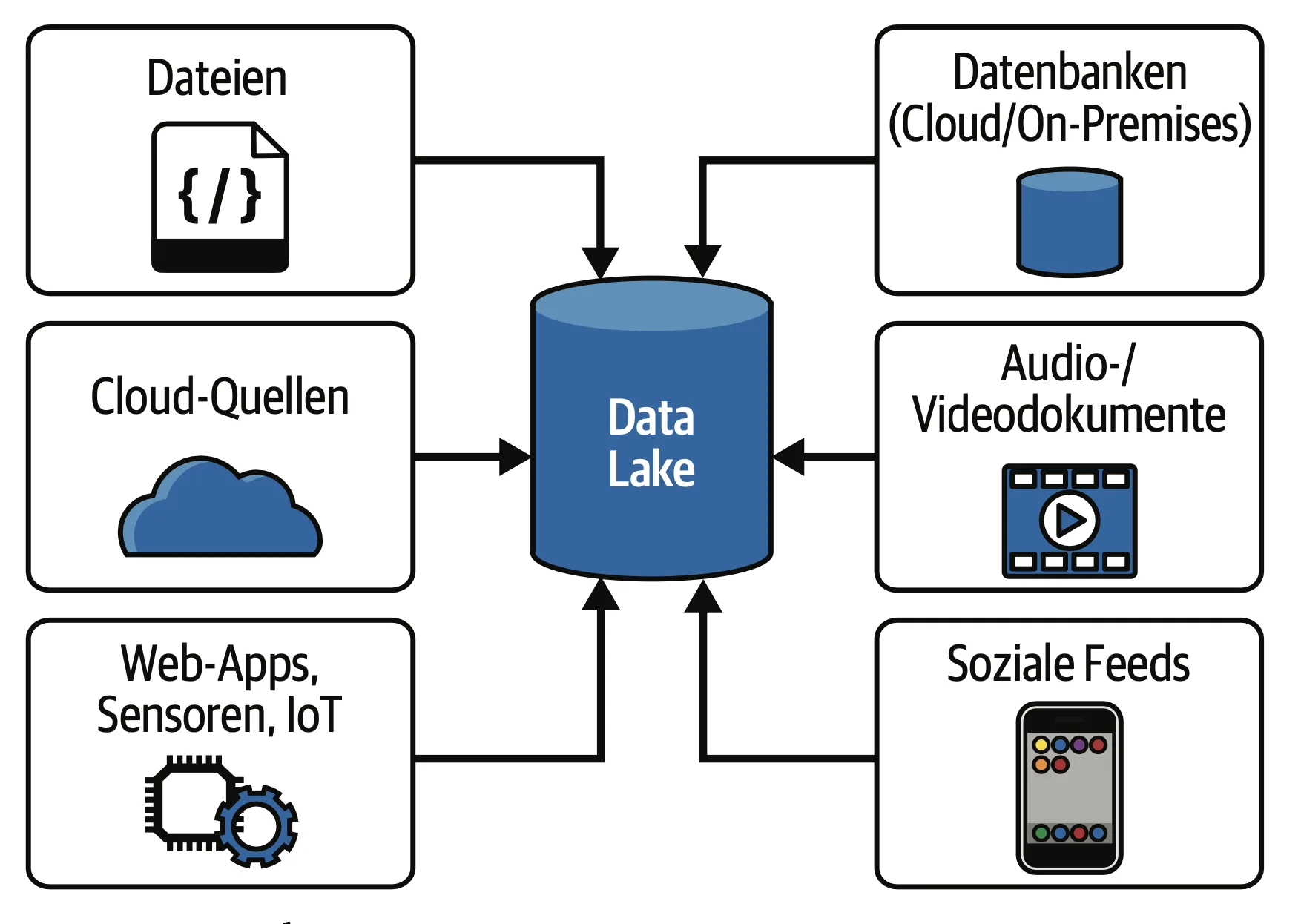
Vorteile
- Hohe Flexibilität: Data Lakes ermöglichen die Speicherung von Daten in ihrer Rohform, was die Integration vielfältiger Datenquellen begünstigt.
- Kosteneffizienz: Die Speicherung großer Datenmengen in einer Data Lake-Umgebung, insbesondere in der Cloud, ist oft kostengünstiger.
- Schnelle Datenerfassung: Rohdaten können ohne vorherige Strukturierung gespeichert werden, was eine schnellere Analyse ermöglicht.
Nachteile
Modern Data Warehouse(MDW)
Das Modern Data Warehouse ist eine Evolution der traditionellen Data-Warehouse-Architektur, die sich in den 2010er Jahren entwickelte. Diese Systeme kombinieren die strukturierten Daten-Erweiterungs-Anforderungen eines klassischen Data Warehouses mit den Skalierbarkeits- und Flexibilitätsanforderungen von Cloud-Computing. Es ermöglicht die Integration von Echtzeitdaten, IoT-Daten und verschiedenen Datenquellen. Diese Architektur unterstützt sowohl strukturierte als auch unstrukturierte Daten und bietet erweiterte Funktionen für maschinelles Lernen und Analyse.
Ein entscheidendes Merkmal ist die Nutzung der „Schema-on-read“-Strategie, die es Benutzern ermöglicht, Daten je nach Bedarf zu analysieren, anstatt sie zuerst zu strukturieren. Modern Data Warehouses berücksichtigen auch die Notwendigkeit eines sofortigen Zugriffs auf Daten, was sie zu einem wertvollen Investment für Unternehmen macht, die schnell auf sich ändernde Marktbedingungen reagieren müssen.
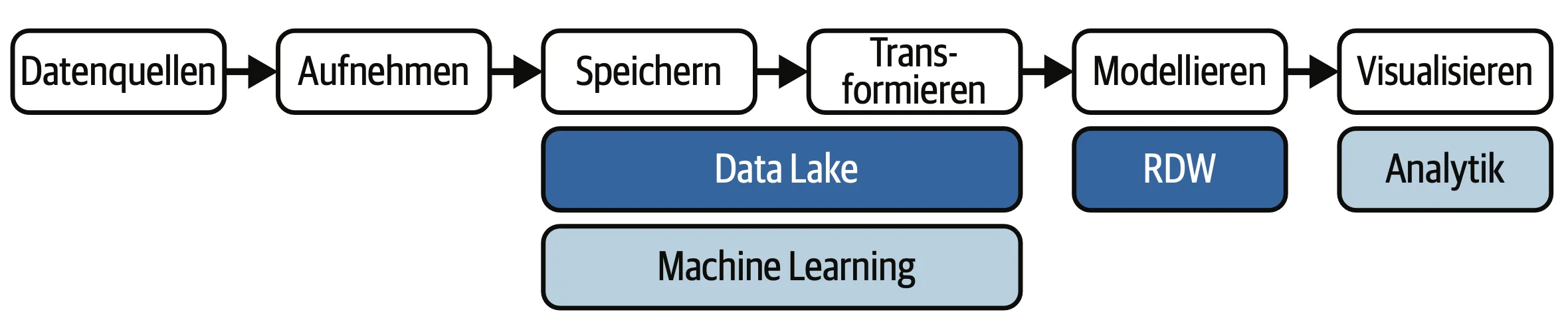
Vorteile
- Echtzeitdatenverarbeitung: Modern Data Warehouses ermöglichen die Integration und Verarbeitung von Echtzeitdaten, was zu schnelleren Entscheidungen führt.
- Cloud-Skalierbarkeit: Viele moderne Lösungen bieten hohe Skalierbarkeit und Flexibilität bei den Betriebskosten.
- Vielseitige Datenverarbeitung: Unterstützung sowohl für strukturierte als auch unstrukturierte Datenanalysen.
Nachteile
Data Fabric
Data Fabric ist eine moderne Architektur, die die Integration und das Management von Daten über verschiedene Plattformen und Datenquellen hinweg vereinfacht. Sie nutzt fortschrittliche Technologien wie AI und maschinelles Lernen, um automatisierte Prozesse zur Verwaltung und Anreicherung von Daten bereitzustellen. Diese Architektur reagiert auf die zunehmende Komplexität heterogener Datenlandschaften und ermöglicht es Unternehmen, einen konsistenten Zugriff auf Daten herzustellen, unabhängig davon, wo sie gespeichert sind.
Data Fabric fördert eine end-to-end Datenintegration, die sowohl Batch- als auch Echtzeitdaten umfasst, und bietet umfassende Governance- und Sicherheitslösungen. Der modulare Ansatz ermöglicht eine flexible Anpassung und Integration neuer Technologien, was Unternehmen die Möglichkeit gibt, ihre bestehende Infrastruktur zu nutzen.
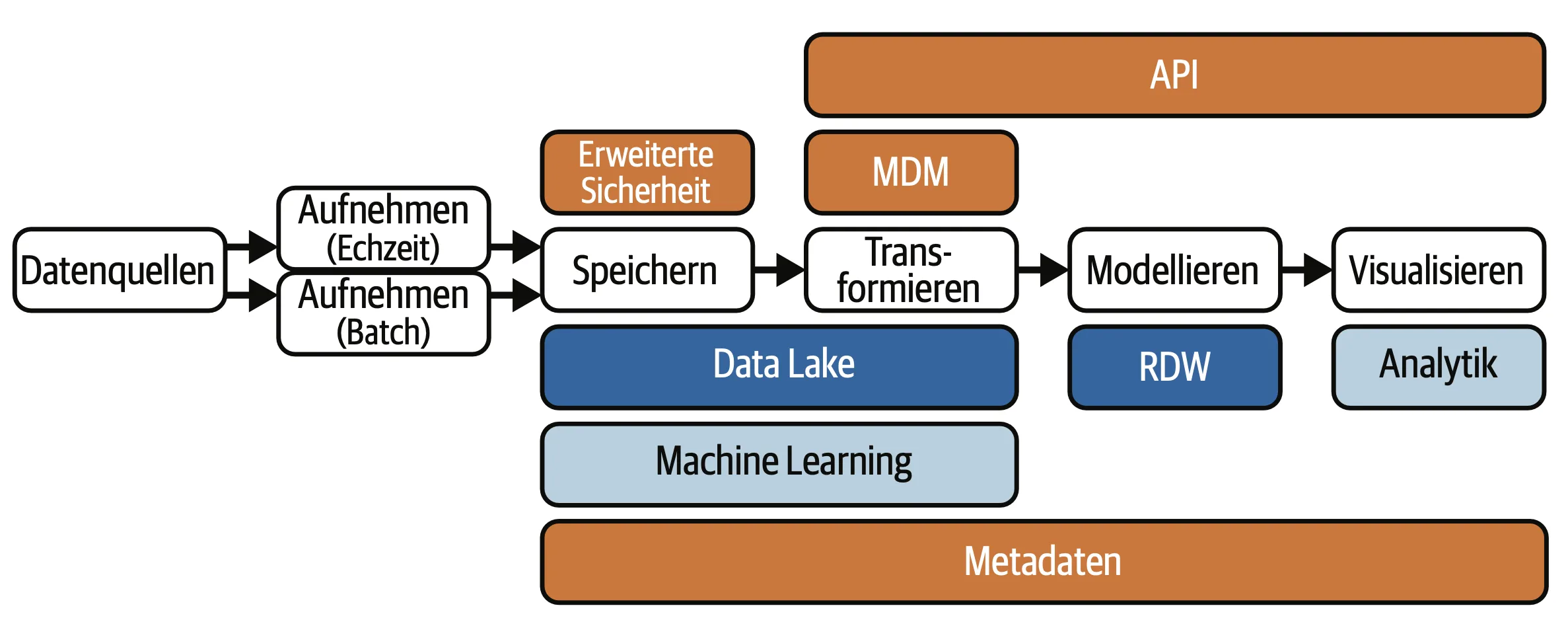
Vorteile
- Integrierter Datenzugriff: Bietet eine einheitliche Ansicht auf Daten, unabhängig von Ursprung und Speicherort, durch Nutzung von AI für die Datenintegration.
- Effiziente Datennutzung: Ermöglicht eine verbesserte Datennutzung und reduziert Datensilos innerhalb der Organisation.
- Automatisierung: AI-gestützte Prozesse zur Datenverwaltung und -anreicherung machen Datenkonvertierung und Verwaltung effizienter.
Nachteile
Data Lakehouse
Das Data Lakehouse ist ein relativ neues Konzept und bietet eine integrierte Plattform, die die Vorteile von Data Lakes und Data Warehouses vereint. Diese Architektur, die um 2019 durch Unternehmen wie Databricks populär wurde, erlaubt es, sowohl strukturierte als auch unstrukturierte Daten effizient zu speichern und zu verarbeiten.
Das Lakehouse kombiniert die Kosteneffizienz und Flexibilität eines Data Lakes mit der Datenverwaltung und den Governance-Funktionen eines Data Warehouses, indem es ACID-Transaktionen und Schema-Durchsetzung ermöglicht. Dies macht es ideal für Unternehmen, die eine umfassende Analyse von Daten benötigen, ohne die Daten zwischen unterschiedlichen Systemen hin und her zu verschieben. Durch die Verknüpfung von Big Data-Analysen mit traditioneller Datenverarbeitung ermöglicht das Lakehouse einen nahtlosen Übergang zwischen verschiedenen Analyse-Workflows.
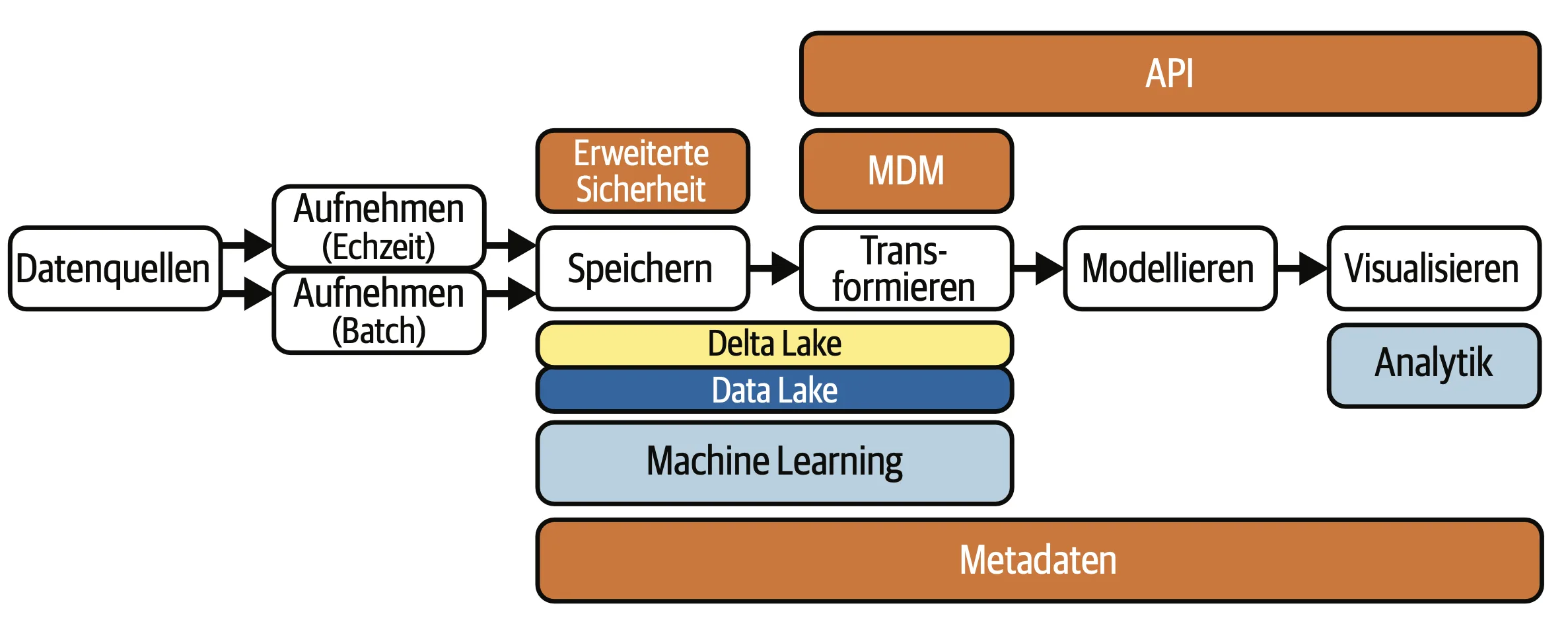
Vorteile
- Integration der Vorteile: Vereint die Flexibilität eines Data Lakes mit der Governance eines traditionellen Data Warehouses.
- Optimierte Analytik: Unterstützt ACID-Transaktionen und ermöglicht die Arbeit mit strukturierten und unstrukturierten Daten in einer einheitlichen Plattform.
- Kostenersparnis: Reduziert die Gesamtkosten durch die Konsolidierung mehrerer Datenlösungen.
Nachteile
DELTA
LAKE
Was ist eigentlich ein Delta Lake?
Ein Delta Lake ist ein Open-Source-Speicher-Layer, der auf bestehenden Data Lakes aufgebaut wird, um deren Zuverlässigkeit, Performance und Datenqualität zu verbessern. Dabei erweitert Delta Lake die herkömmlichen, oft rohen Data Lakes um folgende Kernfunktionen:
- ACID-Transaktionen: Sichern die Datenintegrität, indem sie gewährleisten, dass Schreibvorgänge entweder vollständig abgeschlossen oder vollständig rückgängig gemacht werden.
- Schema Enforcement und Evolution: Erzwingt, dass alle Daten dem definierten Schema entsprechen, erlaubt aber auch die Weiterentwicklung des Schemas ohne Unterbrechung bestehender Prozesse.
- Time Travel: Ermöglicht den Zugriff auf frühere Versionen von Daten, was Audit, Rollback und historische Analysen unterstützt.
- Vereinheitlichte Verarbeitung: Unterstützt sowohl Batch- als auch Streaming-Daten, sodass dieselben Datenquellen in Echtzeit und für historische Analysen genutzt werden können.
- Skalierbare Metadatenverwaltung: Optimiert Abfragen und sorgt dafür, dass auch bei sehr großen Datenmengen die Performance erhalten bleibt.
Delta Lake wird häufig in Verbindung mit Apache Spark und Plattformen wie Databricks verwendet, um einen sogenannten „Lakehouse“-Ansatz zu realisieren – eine hybride Lösung, die die Flexibilität eines Data Lakes mit der Zuverlässigkeit und den Funktionalitäten eines Data Warehouses kombiniert.
Diese Technologien bieten Unternehmen die Möglichkeit, riesige Datenmengen kostengünstig und flexibel zu speichern, während sie gleichzeitig die für Analysen und Machine Learning notwendige Datenqualität und Konsistenz gewährleisten.
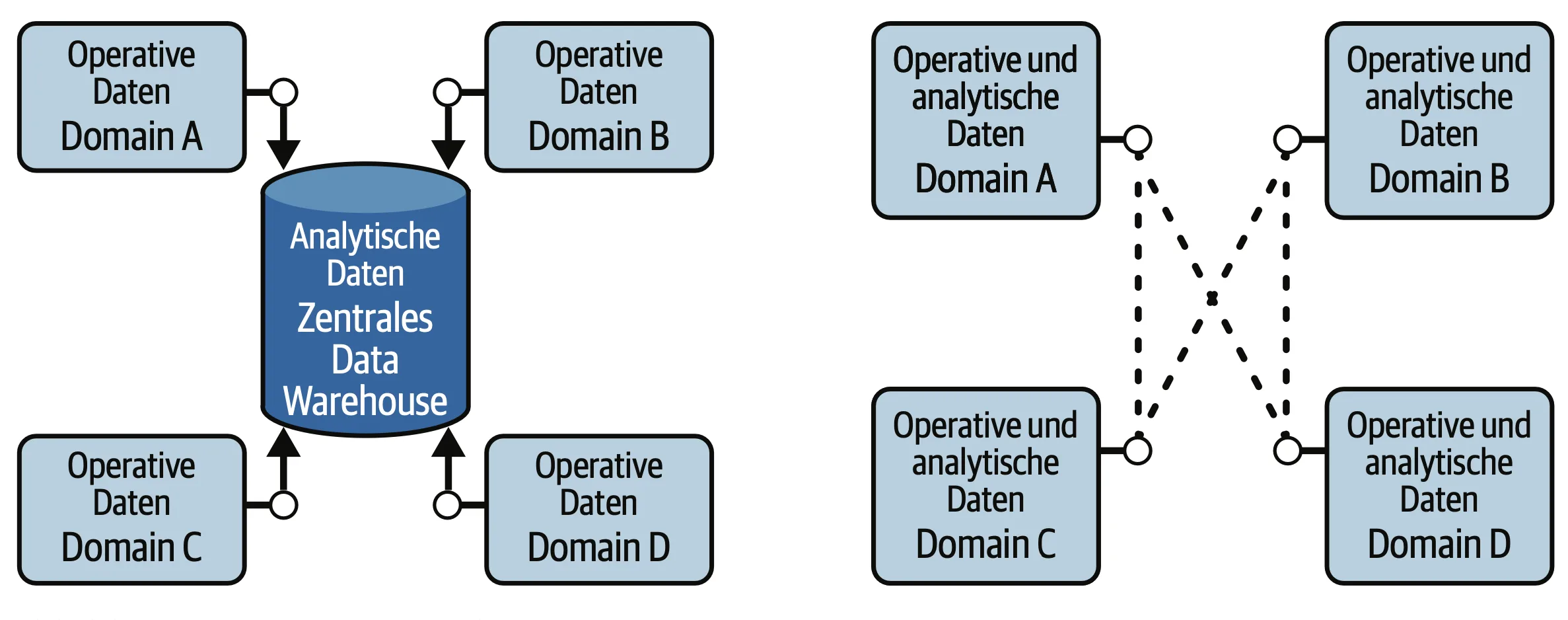
Data Mesh
Data Mesh ist ein moderner, dezentraler Ansatz zur Datenarchitektur, der 2019 von Zhamak Dehghani eingeführt wurde. Dieser Paradigmenwechsel behandelt Daten als Produkt und verteilt die Verantwortung für deren Pflege und Bereitstellung auf verschiedene Domänenteams innerhalb einer Organisation. Anstatt eine zentrale Datenplattform zu verwenden, ermutigt Data Mesh Teams, ihre Datenprodukte unabhängig zu entwickeln und zu verwalten. Diese Struktur fördert die Autonomie und Flexibilität innerhalb der Organisation und ermöglicht eine schnellere Anpassung und Innovation in dynamischen Geschäftsumgebungen.
Der Ansatz ist besonders für große Unternehmen mit komplexen Datenlandschaften von Vorteil, da er Engpässe eliminiert, die durch zentralisierte Datenarchitekturen entstehen können. Data Mesh beinhaltet auch föderierte Governance, die sicherstellt, dass die Datenqualität und Sicherheit über die verschiedenen Domänen hinweg gewahrt bleibt.
Vorteile
- Dezentrale Verantwortung: Daten werden als Produkte betrachtet, und verschiedene Teams übernehmen Verantwortung, was die Agilität stärkt.
- Förderung von Innovation: Teams können autonom arbeiten, was Anpassungen und Innovationen beschleunigt.
- Skalierbare Struktur: Erlaubt eine Anpassung an wachsende Unternehmen und komplexe Datenlandschaften.
Nachteile
Data Governance – Die Evolution parallel zu Datenarchitekturen
Die Evolution der Data Governance spiegelt die im Artikel dargestellte Entwicklung der Datenarchitekturen wider – von strikt hierarchischen Strukturen zu flexiblen, verteilten Systemen.
Während frühe Governance-Modelle zentralisiert und kontrollzentriert waren, haben sich parallel zu modernen Architekturen wie Data Lakes und Data Mesh auch adaptive, föderierte Governance-Ansätze entwickelt. Diese Parallelentwicklung ist kein Zufall: Jede Datenarchitektur bringt eigene Governance-Herausforderungen mit sich, von der Datenqualitätssicherung in traditionellen Warehouses bis zur Verwaltung dezentraler Datenprodukte im Data Mesh.
Wie ich die „Agilität und Anpassungsfähigkeit“ moderner Datenarchitekturen betont habe, verlangt auch moderne Governance Flexibilität bei gleichzeitiger Wahrung übergreifender Standards. Sie wird zum kritischen Erfolgsfaktor in einer Zeit, in der sich „Märkte und Technologien rasant wandeln“ und stellt sicher, dass Unternehmen unabhängig von ihrer gewählten Datenarchitektur den vollen Wert ihrer Daten-Ressourcen ausschöpfen können.
Unabhängig von der spezifischen Architektur erfordert moderne Data Governance technologische Unterstützung durch spezielle Tools: Data-Catalog-Lösungen für Metadatenverwaltung, Data-Quality-Management-Tools, Master-Data-Management-Systeme und zunehmend AI-gestützte Governance-Automatisierung. Die erfolgreiche Implementierung beruht jedoch nicht allein auf Technologie, sondern auf dem richtigen Gleichgewicht zwischen Menschen, Prozessen und Tools – ein Gleichgewicht, das sich parallel zu den technischen Architekturen kontinuierlich weiterentwickelt und anpasst.
Moderne Datenarchitekturen im Vergleich
Während wir uns in diesem Artikel mit der Entstehung der verschiedenen Datenarchitekturen beschäftigen, geht unser Michele noch einen Schritt weiter. Sein Artikel enthüllt, wie du von Bronze- bis Gold-Datenqualität navigierst und welche Architektur – vom klassischen Data Warehouse bis zum revolutionären Data Mesh – perfekt zu deinen spezifischen Anforderungen passt. Erfahre, warum führende Unternehmen zunehmend auf hybride Ansätze setzen und wie du mit der optimalen Datenarchitektur-Strategie einen echten Wettbewerbsvorteil erlangst.

Fazit: Die Wahl der richtigen Datenarchitektur als strategische Entscheidung
Die Reise durch die Welt der Datenarchitekturen zeigt deutlich: Es gibt keine universelle Lösung, die allen Unternehmensanforderungen gerecht wird. Vielmehr haben wir gesehen, wie sich Datenarchitekturen als Antwort auf die sich wandelnden Herausforderungen der digitalen Transformation entwickelt haben – vom strukturierten relationalen Data Warehouse über flexible Data Lakes bis hin zu hybriden Ansätzen wie dem Data Lakehouse und dezentralen Konzepten wie dem Data Mesh.
Die 6 V’s von Big Data – Volume, Velocity, Variety, Veracity, Value und Variability – verdeutlichen die fundamentalen Herausforderungen, denen sich Unternehmen heute stellen müssen. Jede der vorgestellten Architekturen adressiert diese Herausforderungen auf unterschiedliche Weise, mit spezifischen Stärken und Schwächen.
Entscheidend für den Erfolg ist nicht nur die technologische Umsetzung, sondern auch die enge Verzahnung mit einer passenden Data-Governance-Strategie. In einer Zeit, in der Daten zum wertvollsten Unternehmenskapital avancieren und die Grundlage für AI-getriebene Innovationen bilden, wird die Wahl der richtigen Datenarchitektur zur strategischen Entscheidung mit weitreichenden Konsequenzen für die Wettbewerbsfähigkeit.

Schreibe einen Kommentar