The Term Tagging
The popular feature of ‚tagging‘ content is nothing new. The average
netizen should have encountered it by now. Tagging was made popular
by sites like del.icio.us and flickr, where users can attach free-form
strings, so-called ‚tags‘ to their bookmarks and images. The viewer can
then use these tags to navigate through one or more user’s contents and
locate related content.
Scientific Background
The most-cited work on tagging is this research paper from HP, which
starts categorizing tagging as ‚folksonomy‘ (folk taxonomy) in contrast
to the conventional term taxonomy. A taxonomy is usually a categorization
of content according to a hierarchical and exclusive tree of attributes,
while the folksonomy is neither. Also, usually a taxonomy is created by
an individual or a small group, whereas the folksonomy can be created
and expanded by any number of users.
Use of tagging
The most obvious use of tags attached to a set of items is to be able
to quickly search for a subset without having to care about spelling
or being limited because the items are only indexed by title. The most
common user interface for searching according to tags is the ‚tag cloud‘,
a cluster of tags sorted alphabetically. For ease of use the font size
in which each individual tag is shown corellates to the number of items
it is attached to.
It is quite convenient to search in a tag cloud with a couple of hundred
items. A drawback of the cloud, though is that one can only search for
one tag at a time. When the search hits are shown, a list of related
tags is shown that share at least one item with the chosen tag. The
user can then proceed to view the items attached to one of these tags,
but the first tag is subsequently forgotten.
To understand why tagging was invented it is neccessary to look at the
prior status quo of hierarchical ordering like it is done in directories
like dmoz.org, ISP portals or most probably in your browser’s bookmarks
feature. Items are sorted into
a kind of taxonomy. This leads to difficulties since the universe of
topics is multidimensional.
One might have a folder ‚Tutorials‘ for sites that contain tutorials,
and a folder ‚Software‘ for sites on software. Consider further, that
he might want to divide the bookmarks between ‚Windows‘ and ‚Linux‘. The
hierarchical model now makes it necessary to duplicate one set of the
tree’s nodes to attach them to both branches, i.e. you either have a
first-level dichotomy between Windows and Linux and two second level
ones between Tutorials and Software or the other way round.
Since there’s more aspects to expect, this is not a feasible solution,
not even if you flatten out the hierarchy by combining the two aspects
and create four folders.
The Alternative: Instant Hierarchy
A method that combines the flexibility of tagging with the
search-narrowing power of a deep hierarchy is to combine the tags to an
‚instant hierarchy‘: The user chooses from a pool of keywords. Like in
tag clouds, he gets to see some items then and a list of subsequient
keywords. He can then choose a second keyword and get the items that
are tagged with both chosen keywords, and so on. This instant tree is
at it’s deepest in the path of the item with the most tags.
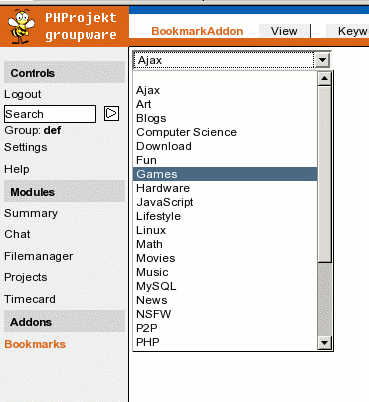



These four images show an example of navigation through the instant
hierarchy. The choice of keywords in the selectboxes narrows downn, in
each step the items that match the exact set of keywords are shown. The
best results are achieved when the items are tagged diversely and
with a diverse number of keywords, because every step then show some
information. If all items have, for instance, three keywords, the first
two steps show nothing new.
Kurze Unterbechung
Das ist dein Alltag?
Keine Sorge – Hilfe ist nah! Melde Dich unverbindlich bei uns und wir schauen uns gemeinsam an, ob und wie wir Dich unterstützen können.
Database-wise, this approach is a lot more complicated than the
single-tag navigation of del.icio.us or technorati. Depending on the
database available, n-fold joining or subquerying can be used. In both
cases we start with a set of three tables, ‚bookmarks‘, ‚keywords‘ and
‚relations‘ since we want to map an n:m relationship:
+--------------+ +--------------+ +--------------+ | bookmarks | | keywords | | relations | +--------------+ +--------------+ +--------------+ | ID | | ID | | ID | | url | | keyword | | bookmark | | title | +--------------+ | keyword | +--------------+ +--------------+
The ID columns are the primary keys (although the relations table might
not need an extra key), the keywords should be unique anyway as long as
no ownership is implemented.
N-fold Joins
The query to retrieve the first set of keywords is obvious:
SELECT DISTINCT k.id,k.keyword
FROM relations as r, bookmarks as b, keywords as k
WHERE r.keyword=k.id
AND r.bookmark=b.id
That might look complicated, but it easily sorts out the keywords that have nothing attached, and it fits in with the recursion that follows
The second step looks like this:
SELECT DISTINCT k.id,k.keyword
FROM relations as r, bookmarks as b, keywords as k, relations as r0
WHERE r.keyword=k.id
AND r.bookmark=b.id
AND r0.keyword=5
since the id of keyword „Programming“ is 5 (you can do this with another join of course, but the information has to retrieved to get the bookmarks beforehand)
The third step is where it gets complicated – we need to make sure the database looks for both keywords and does not return either
SELECT DISTINCT k.id,k.keyword
FROM relations as r, bookmarks as b, keywords as k, relations as r0, relations as r1
WHERE r.keyword=k.id
AND r.bookmark=b.id
AND r0.bookmark=r.bookmark
AND r.keyword!=5
AND r0.keyword=5
AND r1.bookmark=r.bookmark
AND r.keyword!=7
AND r1.keyword=7
From there, it’s simply recursion.
The queries for the list of bookmarks are similar, but a bit simpler. The fourth list of bookmarks is retrieved with this query:
SELECT DISTINCT b.ID,b.url,b.title
FROM bookmarks as b, relations as rc, relations as r1, relations as r2, relations as r3
WHERE rc.bookmark=b.id
AND r1.keyword=’5′
AND r1.bookmark=b.id
AND r2.keyword=’7′
AND r2.bookmark=b.id
AND r3.keyword=’12‘
AND r3.bookmark=b.id
GROUP BY b.id
Subqueries
Newer MySQL versions offer the use of subqueries to replace some joins. A query to get a list of keywords with a prior choice looks like this:
SELECT DISTINCT k.id,k.keyword,
(SELECT count(r0.keyword)
FROM relations r0
WHERE r0.bookmark=b.id
AND r0.keyword IN (5,7,12)) x
FROM bookmarks b,
relations r,
keywords k
WHERE k.id=r.keyword
AND b.id=r.bookmark
AND k.id not in (5,7,12)
HAVING x=3
ORDER BY k.id
We retrieve all keywords that have x other keywords attached, where the other keywords are chosen from our list.
In the same way we can subselect and count the attached keywords to retrieve an appropriate list of bookmarks here.
Implementation
I assembled a small Addon for our OpenSource software PHProjekt and
plan to release it on PHProjekt.com as soon as it’s presentable
(it’s a hobby project so it proceeds a little slower than I would wish
it to). If you are interested in a snapshot, drop me a mail (brotzeller at mayflower dot de).
Currently it lets the user add and delete keywords and bookmarks
and assign keywords to the bookmarks. The above screenshots show the
navigation, which can also return xml and can therefore be used as sidebar
in gecko browser. I also added a feature to get RSS feeds for keyword
choices, so firefox users can add dynamic bookmarks. Since it’s about
bookmarks, usage is observed via redirection, so the RSS feeds can also
show new or most used or last used bookmark lists.

Schreibe einen Kommentar