
In einer Ära von Webentwicklung und AI-Integration ist die effiziente und zuverlässige Verarbeitung von Daten entscheidender denn je. Besonders wenn es um unstrukturierte Daten geht – wie sie häufig auf Webseiten vorkommen – stehen Entwickler vor komplexen Herausforderungen: von der Gewährleistung der Konsistenz und der genauen Validierung bis hin zur schnellen und präzisen Verarbeitung.
Dieser Artikel führt dich durch die Nutzung von 5 leistungsstarken Tools, die dir helfen können, diese Herausforderungen zu meistern und deine Datenverarbeitung auf ein neues Level zu heben. Ich zeige dir, wie du mit modernen Werkzeugen nicht nur die Validierung deiner Daten optimierst, sondern auch eine robuste Überwachung und präzise semantische Tests einführst.

Damit du im Anschluss an den Artikel gleich selbst ein wenig mit den Beispielen herumspielen kannst, habe ich dir den Code auf GitHub hochgeladen. Viel Spaß beim Experimentieren!
#1 TypeScript
Typsicher und robust
Vielleicht fragst du dich, warum ich in meinen Beispielen TypeScript und nicht die oft bevorzugte AI-Sprache Python verwende. Dafür gibt es gute Gründe: Während Python sich in der Datenwissenschaft etabliert hat, bietet TypeScript einige entscheidende Vorteile, die besonders bei der Entwicklung professioneller und stabiler Anwendungen ins Gewicht fallen.
TypeScript kombiniert die Flexibilität von JavaScript mit einer strikten Typisierung, die frühzeitig potenzielle Fehler abfängt und somit den Entwicklungsprozess sicherer macht. Gerade in komplexen Anwendungen, bei denen AI-Modelle mit verschiedenen Datenquellen interagieren, sorgt TypeScript für mehr Robustheit und Wartbarkeit. Durch die Typsicherheit lassen sich Bugs identifizieren und beheben, bevor sie überhaupt die Laufzeit erreichen – das spart Zeit und sorgt für eine verlässlichere Codebasis.
Professionelle und skalierbare Anwendungen profitieren enorm von der Fähigkeit, strukturierte Datenmodelle klar zu definieren und damit saubere Schnittstellen zu schaffen. Aus diesem Grund ist TypeScript die perfekte Wahl für Entwickler, die nicht nur an der Funktionalität, sondern auch an der Langlebigkeit und Qualität ihrer Anwendungen interessiert sind.
#2 Zod
Datenvalidierung und Typensicherheit für moderne Webanwendungen
Zod ist eine leistungsstarke und benutzerfreundliche Bibliothek zur Datenvalidierung für JavaScript und TypeScript. Als TypeScript-first Bibliothek ermöglicht Zod Entwicklern, präzise Schemata für ihre Daten zu definieren und diese entsprechend zu validieren.
Kurze Unterbechung
Das ist dein Alltag?
Keine Sorge – Hilfe ist nah! Melde Dich unverbindlich bei uns und wir schauen uns gemeinsam an, ob und wie wir Dich unterstützen können.
Ein Schema beschreibt, wie die Daten aussehen sollten – einschließlich der erforderlichen Felder, der erwarteten Typen und der Validierungsregeln. Diese deklarative Methode stellt sicher, dass Daten den erwarteten Struktur- und Typanforderungen entsprechen, was besonders wichtig ist, wenn unstrukturierte oder externe Daten von Nutzern, APIs oder Datenbanken verarbeitet werden müssen.
Warum ist Zod gut?
- Typensicherheit: Da Zod eine TypeScript-first Bibliothek ist, profitieren TypeScript-Nutzer von vollständiger Typensicherheit. Das bedeutet, dass Fehler durch unpassende Datentypen oder fehlende Felder in der Entwicklung schon während der Kompilierung erkannt werden – bevor sie in Produktion gelangen.
- Einfache Syntax: Das API von Zod ist einfach und intuitiv zu nutzen. Es erlaubt dir, schnell und effizient Schemas zu erstellen und Daten zu validieren, ohne dass du dich durch komplexe Konfigurationen arbeiten musst.
- Fehlertoleranz: Zod bietet präzise und verständliche Fehlermeldungen. Wenn Daten nicht dem Schema entsprechen, liefert Zod klare Hinweise darauf, welche Validierungsregeln verletzt wurden, was die Fehlersuche erheblich vereinfacht.
- Flexible Validierung: Mit Zod kannst du nicht nur einfache Typen validieren, sondern auch komplexere Validierungslogiken wie benutzerdefinierte Validierungsfunktionen, optionale Felder und verschachtelte Objekte umsetzen.
- Integration mit TypeScript: Zod ist nahtlos in TypeScript integriert und bietet vollständige Unterstützung für die statische Typprüfung. Das hilft Entwicklern dabei, typensicheren Code zu schreiben. Außerdem verhindert es viele häufige Fehlerquellen, die in dynamisch typisierten Sprachen auftreten können.
Zod in der Praxis
Hier ist ein einfaches Beispiel, das zeigt, wie Zod verwendet werden kann, um ein Schema zu definieren und Daten zu validieren:
import { z } from 'zod';
// Definiere ein Schema für die Benutzerdaten
const userSchema = z.object({
username: z.string().min(1, "Username is required"),
email: z.string().email("Invalid email address"),
age: z.number().min(18, "Must be at least 18 years old"),
});
// Funktion zur Validierung von Benutzerdaten
const validateUserData = (data: unknown) => {
try {
// Validierung der Daten gegen das Schema
const validatedData = userSchema.parse(data);
console.log("Valid user data:", validatedData);
} catch (error) {
// Fehlerbehandlung bei ungültigen Daten
console.error("Validation failed:", error.errors);
}
};
// Beispiel für gültige Benutzerdaten
validateUserData({ username: "Alice", email: "alice@example.com", age: 25 });
// Beispiel für ungültige Benutzerdaten
validateUserData({ username: "", email: "invalid-email", age: 17 });
In diesem Beispiel definieren wir ein `userSchema`, das die Struktur der Benutzerdaten beschreibt, und verwenden die Funktion `validateUserData`, um zu überprüfen, ob die übergebenen Daten den Anforderungen des Schemas entsprechen. Zod wirft Fehler, wenn die Daten ungültig sind, was eine sofortige und präzise Fehlerbehebung ermöglicht.
Was zu sagen bleibt? Zod ist eine hervorragende Wahl für Entwickler, die eine zuverlässige und typensichere Methode zur Datenvalidierung benötigen. Es verbessert die Codequalität, reduziert Fehlerquellen und sorgt für eine bessere Wartbarkeit und Robustheit deiner Anwendungen.
#3 Vercel AI SDK
Parsing von HTML-Seiten mit Zod und generativen Sprachmodellen
Das Vercel AI SDK bietet ein benutzerfreundliches API, das es Entwicklern ermöglicht, fortschrittliche AI-Modelle nahtlos in ihre Anwendungen zu integrieren, ohne sich um die komplexen Details der Modellintegration kümmern zu müssen. Es optimiert die Nutzung von Sprachmodellen für Aufgaben wie Textgenerierung, Inhaltszusammenfassung und Datenextraktion und erleichtert die schnelle Implementierung von AI-gestützten Features.
Mit dem SDK kannst du die Leistung und Genauigkeit der AI-Modelle in Echtzeit optimieren und gleichzeitig sicherstellen, dass generierte oder extrahierte Daten direkt gegen vordefinierte Zod-Schemas validiert werden. Diese Integration ermöglicht eine präzise Validierung der Daten, sodass sie den erwarteten Struktur- und Typanforderungen entsprechen, und vereinfacht die Einbindung von AI-Funktionalitäten erheblich.
AI Success Story

Müller automatisiert Retail-Prozesse mit AI
Schnellerer Markteintritt, optimierte Workflows und deutlich reduzierter Personalaufwand.
Warum ist das Vercel AI SDK gut?
- Benutzerfreundliches API: Einfache und intuitive Schnittstelle für den Zugriff auf fortschrittliche AI-Modelle.
- Nahtlose Integration: Leicht in bestehende Anwendungen integrierbar, ohne komplexe Modellintegration.
- Leistungsstarke Modelle: Zugriff auf generative AI-Modelle für Aufgaben wie Textgenerierung, Inhaltszusammenfassung und Datenextraktion.
- Schnelle Implementierung: Möglichkeit zur schnellen Implementierung von AI-gestützten Features ohne umfangreiche Anpassungen.
- Optimierte Leistung: Echtzeit-Optimierung der Leistung und Genauigkeit der AI-Modelle durch einfache API-Aufrufe.
- Integration mit Zod: Unterstützung für die Validierung von Daten gegen Zod-Schemas, um sicherzustellen, dass sie den erwarteten Struktur- und Typanforderungen entsprechen.
Das Vercel AI SDK in der Praxis
Hier folgt ein Beispiel, wie eine Webseite mit dem SDK in ein Zielschema geparst werden kann. Konkret handelt es sich bei der Webseite um einen Artikel der SZ: Neu in Kino & Streaming: Welche Filme sich lohnen – und welche nicht
Zuerst erstellen wir uns das Zielschema mit Zod. Wir möchten den Titel des Artikels, eine Zusammenfassung des Inhaltes in mindestens 100 Wörtern, das Erscheinungsdatum in einem bestimmten Format und den oder die Autoren als ein Array haben.
Hier passiert übrigens das “Prompting”: je besser also die Beschreibung von dem ist, was ich gerne haben möchte, desto besser können die erhaltenen Daten sein. Allerdings ist das auch der Ansatzpunkt, an dem herumgespielt werden muss, sollte das Parsen fehlschlagen. Im Notfall arbeite ich lieber mit optionalen Attributen, falls Daten nicht vorhanden sind oder nicht erkannt werden.
const schema = z.object({
title: z.string({
description: "The headline of the article must be at least 1 character long"
}),
summary: z.string({
description: "The summary of the article must be at least 100 words long and must contain all aspects of the article. Do not make any assumptions!"
}),
date: z.string({
description: "The date of the article in Iso format (DD.MM.YYYY)"
}),
authors: z.array(z.string({
description: "The name of the author of the article"
})),
});
Ein kurzer Exkurs zu Tokens und Limits in generativen Sprachmodellen
Es gibt ein Limit, wenn wir mit Sprachmodellen arbeiten, und das ist die Menge an Token, die ein Sprachmodell verarbeiten kann. Ein Token kann dabei z. B. ein Wort oder Teile eines Wortes sein – oder auch ein Satzzeichen. So hat beispielsweise gpt-4 ursprünglich ein Limit von 8.000 Tokens und gpt-4o ein Limit von 128.000 Tokens.
Zu beachten bei großen Datenmengen ist, dass sich das Limit nicht nur auf den Input bezieht, sondern eine Kombination aus Input + Output Tokens ist. Sprich: wenn du ein gpt-4 Modell mit 6800 Tokens fütterst, kann es nur noch 1200 Tokens ausgeben. Überschreitest du schon beim Input das Token-Limit, erhältst du einen Fehler.
Zusätzlich ist zu beachten, dass einige Modelle auch noch ein Limit auf die Output-Tokens haben. gpt-4 hat z. B. ein Limit von 8192 Output-Tokens. Details lassen sich in der Dokumentation des jeweiligen Modells finden und unter help.openai.com.
Der Einfachheit halber habe ich den Quellcode der Webseite in der Datei input.html gespeichert; diese lesen wir aus. Um das Problem mit dem Token-Limit (siehe Infokasten) zu umgehen, wandele ich den Inhalt der Datei in Markdown um. Das geht recht einfach mit dem Package `turndown`. Anschließend nutze ich das Vercel AI SDK, übergebe diesem mein Schema und meine Daten und erhalte davon nach einiger Zeit – Abhängig vom verwendeten Modell und der Menge an Inputdaten – eine Antwort (Listing 1. Schritt).
Wenn wir das Programm ausführen, erhalten wir einen Output ähnlich wie in Listing Output 1 gezeigt.
Ein passables Ergebnis. Aber der Artikel erschien auf Deutsch und wir möchten unsere Zusammenfassung vielleicht ebenfalls auf Deutsch haben. Also ändern wir unseren Prompt ein wenig ab (Listing 2. Schritt).
Wir verlangen also gleich hier, in welcher Sprache das Attribut befüllt werden soll. Das Ergebnis könnte dem aus dem Listing Ergebnis ähneln.
// HTML Datei einlesen
const input = fs.readFileSync('./src/input.html', 'utf8');
// HTML in Markdown umwandeln - spart Tokens und Zeit
const markdown = (new TurndownService()).turndown(input);
// Markdown und Schema an Sprachmodell übergeben, um ein Ergebnisobjekt zu erhalten
const {object} = await generateObject({
model: openai('gpt-4-turbo'),
schema: schema,
messages: [{
role: 'system',
content: 'You are a professional newspaper reader who is tasked with summarizing an article. Do not make any assumptions!'
}, {
role: 'user',
content: markdown
}],
seed: 1234,
temperature: 0
})
console.log(object)
{
title: 'Neu in Kino & Streaming',
summary: 'The article titled "Neu in Kino & Streaming" provides a comprehensive overview of various films and theatrical productions, highlighting their themes, narratives, and critical receptions. It covers a range of genres and styles, from heartfelt dramas to intense thrillers, and includes detailed descriptions of the plots and performances. Key films discussed include "Die Ironie des Lebens," a poignant story about dealing with terminal illness and personal transformation, and "Ellbogen," a gritty portrayal of societal issues in Germany. The article also touches on the challenges and experiences of women in the theater industry, emphasizing the lack of opportunities and representation for older actresses. Additionally, it reviews a documentary that explores the harsh realities faced by actresses and directors in a male-dominated theater environment. Each film or production is analyzed not just for its entertainment value but also for its deeper social and cultural implications, offering a thoughtful critique on the subjects it tackles.',
date: '04.09.2024',
authors: [
'Fritz Göttler',
'Kathleen Hildebrand',
'Doris Kuhn',
'Florian Kaindl',
'Martina Knoben',
'Philipp Bovermann',
'Josef Grübl'
]
}
const schema = z.object({
title: z.string({
description: "The headline of the article must be at least 1 character long"
}),
summary: z.string({
description: "The summary of the article must be at least 100 words long and must contain all aspects of the article. Do not make any assumptions! I want the summary in german language."
}),
date: z.string({
description: "The date of the article in Iso format (DD.MM.YYYY)"
}),
authors: z.array(z.string({
description: "The name of the author of the article"
})),
});
{
title: 'Neu in Kino & Streaming',
summary: 'Der Artikel „Neu in Kino & Streaming“ präsentiert eine Vielzahl von Filmen, die kürzlich in den Kinos und auf Streaming-Plattformen gestartet sind. Jeder Film wird von verschiedenen Autoren besprochen, die ihre Eindrücke und Kritiken teilen. \n' +
'\n' +
'Fritz Göttler beschreibt den Film „Bleib am Ball – egal was kommt!“, der die Geschichte von Dylan erzählt, einem jungen Mann, der nach einem Unfall im Rollstuhl sitzt und dessen Traum von einer Fußballkarriere zerstört wurde. Der Film wird als emotional und tiefgründig beschrieben, der die Schwierigkeiten im Umgang mit persönlichen Träumen und Realitäten thematisiert. \n' +
'\n' +
'Kathleen Hildebrand rezensiert „Die Ironie des Lebens“, einen Film, der die Geschichte von Edgar, einem alternden Komiker, erzählt, der sich mit seiner Sterblichkeit auseinandersetzt, nachdem er erfährt, dass seine Ex-Frau bald sterben wird. Der Film wird als emotional kraftvoll und visuell beeindruckend beschrieben. \n' +
'\n' +
'Martina Knoben kritisiert „Die Schule der Frauen“, die sie als eine Dokumentation über die Ungleichheiten im Theaterbetrieb darstellt, insbesondere in Bezug auf Geschlechterungleichheit und die Unterrepräsentation älterer Frauen. \n' +
'\n' +
'Philipp Bovermann bietet eine Analyse des Films „Ellbogen“, der sich mit Themen von Rassismus und sozialer Ausgrenzung in Deutschland auseinandersetzt. Der Film basiert auf dem gleichnamigen Roman von Fatma Aydemir. \n' +
'\n' +
'Doris Kuhn bespricht „Something in the Water“, einen Film über fünf Frauen, die auf einer Insel gestrandet sind und ums Überleben kämpfen, während sie gleichzeitig ihre vergangenen Konflikte aufarbeiten. \n' +
'\n' +
'Weitere Filme, die besprochen werden, sind „New Life“, „Rock ’n’ Roll Ringo“ und „Üben üben üben“, die jeweils unterschiedliche Genres und Themen abdecken, von tiefgründigen Dramen bis hin zu actionreichen Thrillern. \n' +
'\n' +
'Jeder Beitrag bietet einen tiefen Einblick in die Handlung, Charakterentwicklung und thematische Tiefe der Filme, ergänzt durch persönliche Bewertungen der Autoren, die sowohl positive Aspekte als auch Kritikpunkte hervorheben.',
date: '04.09.2024',
authors: [
'Fritz Göttler',
'Kathleen Hildebrand',
'Doris Kuhn',
'Florian Kaindl',
'Martina Knoben',
'Philipp Bovermann',
'Josef Grübl'
]
}
Fuzzy Parsing at its best!
#4 Langfuse
Observability für AI-Anwendungen
Langfuse ist eine Open-Source-Plattform, die darauf abzielt, Observability für Anwendungen bereitzustellen, die auf Large Language Models (LLMs) und anderen AI-Modellen basieren. Es bietet Entwicklern die Möglichkeit, ihre AI-Modelle effizient zu überwachen, zu analysieren und zu optimieren. Das Open-Source-Modell von Langfuse erlaubt es, den Quellcode anzupassen und spezifische Bedürfnisse deiner Anwendung zu erfüllen, während gleichzeitig von einer wachsenden Entwickler-Community profitiert wird.
Warum ist Langfuse gut?
- Leistungsüberwachung: Verfolge die Performance deines AI-Modells in Echtzeit, inklusive Metriken wie Antwortzeiten und Erfolgsraten.
- Prompt-Tracking: Überwache die Reaktionen des Modells auf verschiedene Eingaben und identifiziere unerwartetes Verhalten.
- Fehlerdiagnose: Identifiziere und analysiere Probleme und Anomalien in Modellantworten mit detaillierten Logs.
- A/B-Tests und Modellvergleiche: Vergleiche verschiedene Modellversionen, um die beste Performance zu ermitteln.
- Audit-Trail und Compliance: Verwalte einen vollständigen Audit-Trail aller Interaktionen, um Vorschriften einzuhalten.
- Open Source: Flexibel, anpassbar und selbst hostbar, unterstützt durch eine aktive Entwickler-Community.
- Kostenkontrolle: Langfuse bietet Einblicke in die Nutzung deiner AI-Modelle und ermöglicht es dir, die Kosten im Auge zu behalten.
Mit Langfuse als Open-Source-Tool hast du die volle Kontrolle über die Überwachung und Optimierung deiner KI-Modelle, unterstützt durch eine aktive Community und anpassbare Funktionalitäten.
Langfuse in der Praxis
Um Langfuse in unser vorheriges Beispiel zu integrieren ist nicht viel nötig. Vorher müssen wir uns allerdings entscheiden, ob wir Langfuse selbst hosten wollen oder ob wir den Service nutzen wollen. Zur Vereinfachung nutze ich hier den Service unter cloud.langfuse.com.
Dort legen wir ein neues Projekt an und erhalten im Gegenzug einen Secret Key, einen Public Key und die Server-URL. Damit können wir mit dem API von Langfuse kommunizieren.
In unserem Code nutzen wir das Node SDK von OpenTelemetry, richten es ein und starten es. In unserem `generateObject`-Aufruf des Vercel AI SDKs nutzen wir die zum Zeitpunkt der Erstellung dieses Blogposts noch experimentellen Features von OpenTelemetry. Was dann noch bleibt, ist die `shutdown()`-Funktion des Node SDKs aufzurufen, um die gesammelten Daten an Langfuse zu übermitteln.
const sdk = new NodeSDK({
traceExporter: new LangfuseExporter(),
instrumentations: [getNodeAutoInstrumentations()],
})
sdk.start();
async function main() {
try {
// HTML Datei einlesen
const input = fs.readFileSync('./src/input.html', 'utf8');
// HTML in Markdown umwandeln - spart Tokens und Zeit
const markdown = (new TurndownService()).turndown(input);
// Markdown und Schema an Sprachmodell übergeben, um ein Ergebnisobjekt zu erhalten
const {object} = await generateObject({
// model: openai('gpt-4-turbo'),
model: openai('gpt-4o'),
schema: schema,
messages: [{
role: 'system',
content: 'You are a professional newspaper reader who is tasked with summarizing an article. Do not make any assumptions!'
}, {
role: 'user',
content: markdown
}],
seed: 1234,
temperature: 0.1,
experimental_telemetry: {
isEnabled: true,
functionId: "generateObject"
}
});
console.log(object)
await sdk.shutdown();
} catch(error) {
console.log(error)
}
}
main();
Das ist bereits alles. Und nachdem wir unsere App ausgeführt haben, können wir im Dashboard unseres Projektes auf der Langfuse-Seite bereits unsere Metriken einsehen.
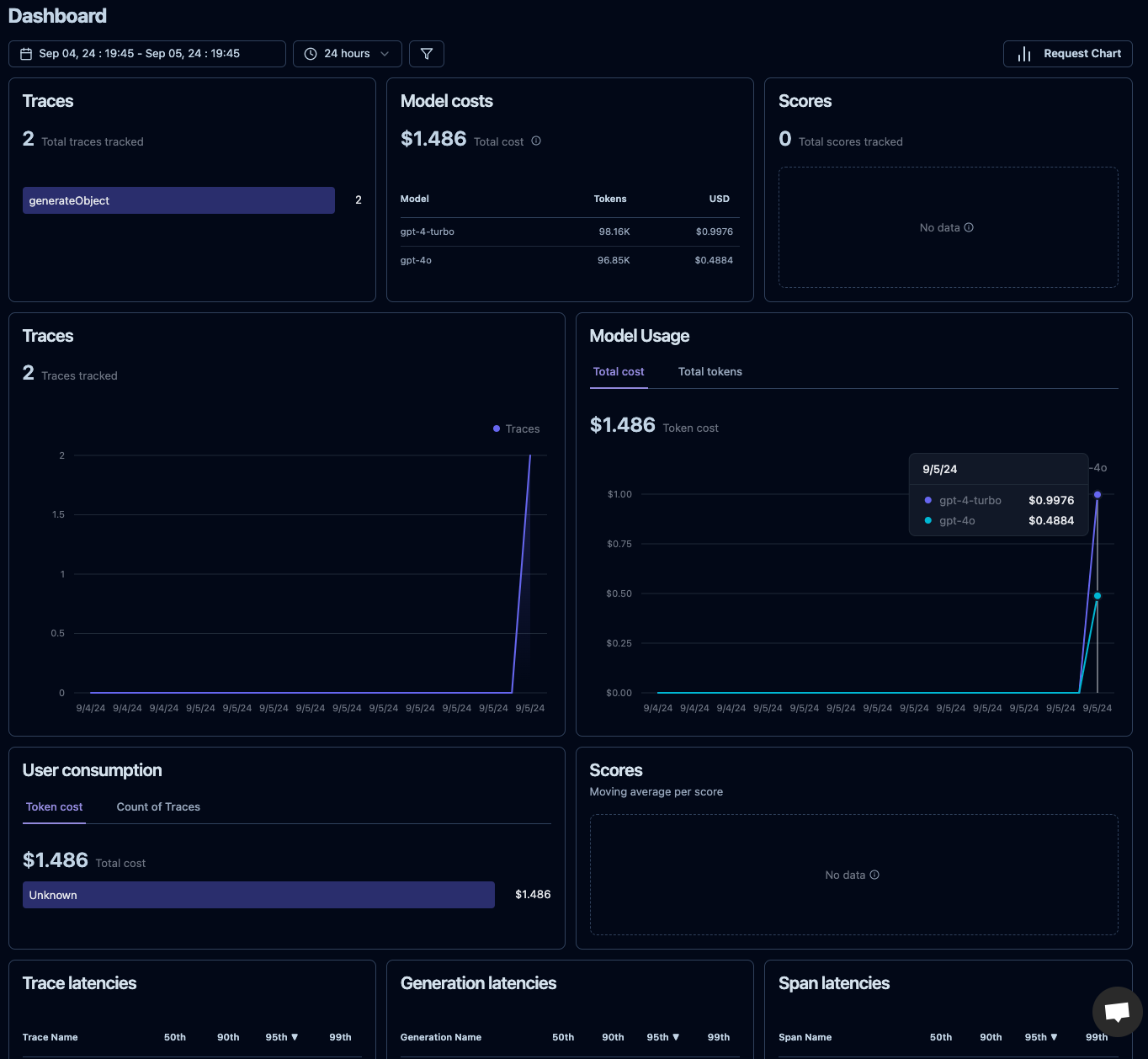
Ich habe hier unsere App zwei Mal gestartet, einmal mit dem Modell gpt-4-turbo und einmal mit dem Modell gpt-4o. Es lässt sich jetzt bereits ein gewaltiger Unterschied im Preis feststellen, bei gar nicht mal so unterschiedlichen Token. Ideal also, um die Kosten für eure AI-Nutzung im Blick zu behalten.
Auf den Detailseiten gibt es natürlich noch mehr zu sehen. Interessant sind z. B. auch Trace Details, die Aufschluss darüber geben, was im Detail bei dem Request passiert ist und auch, wie lange er dauerte (hier 39.95 Sekunden).
#5 Promptfoo
Semantische Tests für deine AI-Prompts
Promptfoo ist ein Tool, das speziell entwickelt wurde, um die Semantik von AI-Prompts zu testen. Außerdem stellt es sicher, dass ein generatives Sprachmodell konsistent und erwartungsgemäß auf verschiedene Eingaben reagiert. Es ermöglicht Entwicklern, automatisierte Tests für ihre AI-Prompts zu schreiben – ähnlich wie Unit-Tests im herkömmlichen Softwareentwicklungs-Prozess. Promptfoo hilft dabei, Regressionen zu vermeiden und die Qualität und Stabilität von Antworten zu überprüfen, indem es vergleicht, ob das Modell die semantisch korrekten Ergebnisse liefert.
Durch die Integration von Promptfoo können Entwickler sicherstellen, dass sich ihre AI-Modelle erwartungsgemäß verhalten und bei Änderungen in den Prompts oder Modellen keine unerwarteten Fehler auftreten.
Warum ist Promptfoo gut?
- Semantische Konsistenz: Es prüft, ob das Sprachmodell auf ähnliche Eingaben ähnliche und korrekte Antworten liefert.
- Automatisierte Tests: Ähnlich wie Unit-Tests ermöglicht Promptfoo automatisierte Tests für Prompts.
- Regressionserkennung: Bei Änderungen im Prompt oder Modell stellt Promptfoo sicher, dass keine unerwarteten Verschlechterungen auftreten.
- Anpassbare Metriken: Es unterstützt die Konfiguration verschiedener Metriken zur Bewertung der Modellantworten.
- Einfache Integration: Promptfoo lässt sich problemlos in bestehende Testumgebungen integrieren, wie z.B. Vitest, um die Testergebnisse automatisiert zu validieren.
- LLM Red Teaming: Verwende Promptfoo für Red Teaming von Large Language Models (LLMs), um Schwächen, unerwünschtes Verhalten oder Sicherheitslücken in deinen Modellen proaktiv zu identifizieren und anzugehen.
Promptfoo in der Praxis
Hier sind zwei einfache Beispiele, wie du Promptfoo verwenden kannst, um einen semantischen Unit-Test zu schreiben:
import {describe, it, expect, beforeAll} from 'vitest';
import * as promptfoo from 'promptfoo';
import dotenv from 'dotenv'
beforeAll(() => {
dotenv.config() // hier laden wir den API Key
})
describe('Promptfoo Test Suite', () => {
it('should pass when strings are semantically similar', async () => {
const expected = 'The quick brown fox';
const output = 'A fast brown fox';
const threshold = 0.8;
const response = await promptfoo.assertions.matchesSimilarity(expected, output, threshold);
expect(response.pass).toBeTruthy();
});
it('should fail when strings are not semantically similar', async () => {
const expected = 'The quick brown fox';
const output = 'The weather is nice today';
const threshold = 0.8;
const response = await promptfoo.assertions.matchesSimilarity(expected, output, threshold);
expect(response.pass).toBeFalsy();
});
});
Der Threshold gibt an, wie ähnlich sich zwei Texte sein müssen, um als „ähnlich“ zu gelten. Der Wert reicht typischerweise von 0 bis 1, wobei 1 für eine perfekte Übereinstimmung steht. Ein Threshold von 0.8, wie im Beispiel, bedeutet, dass die Texte zu mindestens 80 Prozent ähnlich sein müssen, um den Test zu bestehen.
Was können wir mit dem Threshold machen?
Wir können den Threshold so einstellen, dass er den Grad der Toleranz in unserem Tests widerspiegelt. Bei einem niedrigeren Threshold werden auch Texte als ähnlich erkannt, die weniger Gemeinsamkeiten aufweisen, während ein höherer Threshold nur fast identische Texte als ähnlich anerkennt.
Je nach Anwendung können wir so definieren, wie strikt die semantische Übereinstimmung sein soll. Das ist besonders nützlich, wenn die Antworten variabel, aber dennoch inhaltlich korrekt sein müssen.
Ein negativer Threshold könnte verwendet werden, um den Test zu bestehen, wenn die Texte nicht ähnlich sind. Das wäre nützlich, wenn wir sicherstellen wollen, dass sich zwei Ausgaben voneinander unterscheiden sollen.
Die Ausführung der Tests erzeugt dann z. B. folgende Ausgabe:
✓ src/example.test.ts (3) 2394ms
✓ Promptfoo Test Suite (3) 2393ms
✓ should pass when strings are semantically similar 1383ms
✓ should fail when strings are not semantically similar 1007ms
✓ should fail when strings are not semantically similar with negative threshold
Test Files 1 passed (1)
Tests 3 passed (3)
Start at 11:16:18
Duration 3.45s (transform 41ms, setup 0ms, collect 579ms, tests 2.39s, environment 0ms, prepare 136ms)
Fazit
Unstrukturierte Daten gewinnen immer mehr an Bedeutung; effiziente und zuverlässige Tools zur Verarbeitung und Validierung sind also unerlässlich. Durch die Kombination von Technologien wie TypeScript, Zod, dem Vercel AI SDK, Langfuse und Promptfoo kannst du nicht nur die Datenvalidierung und -verarbeitung auf ein neues Niveau heben, sondern auch die Qualität und Konsistenz deiner AI-Prompts sicherstellen.
TypeScript bietet die Typensicherheit und Stabilität, die du für professionelle Anwendungen benötigst, während Zod dir ermöglicht, deine Datenstrukturen präzise zu validieren. Das Vercel AI SDK erleichtert die Integration generativer Sprachmodelle in deine Anwendungen, und mit Langfuse kannst du deren Performance überwachen und analysieren. Schließlich sorgt Promptfoo dafür, dass deine AI-Prompts zuverlässig bleiben, indem es semantische Tests für AI-Modelle ermöglicht.
Mit diesen Tools kannst du deine Webentwicklung und AI-Projekte robust, wartbar und skalierbar gestalten, während du gleichzeitig sicherstellst, dass deine Anwendungen zuverlässig und effizient arbeiten.
Puh, das war jetzt eine Menge … Aber wie sieht es bei dir aus? Hast du bereits einige dieser Tools ausprobiert? Welches davon gefällt dir am Besten? Hast du ganz andere Empfehlungen? Schreib mir das doch in die Kommentare.
Das ist dein Alltag?
Keine Sorge – Hilfe ist nah! Melde Dich unverbindlich bei uns und wir schauen uns gemeinsam an, ob und wie wir Dich unterstützen können.
Schreibe einen Kommentar