
Im letzten Post haben wir schon einmal ein bisschen losgelegt, unser GraphQL-Schema mit Smart Tags anzupassen. Einfach nur ein paar Features ein- und auszuschalten oder Spalten zu entfernen reicht natürlich nicht … Wir wollen ja in der echten Welt um einiges komplexere, vielleicht auch dynamische Werte in unserem API abbilden. Ohne also noch weiter auf den Busch zu klopfen schlage ich vor, wir schauen uns einfach direkt an, wie wir mit Computed Columns arbeiten können.
Wie auch schon im letzten Post gibt es allen Code in unserem Beispielprojekt auf GitHub zum Ausprobieren und Mitverfolgen.
Veraltete Software ist oft Nährboden für eine Schatten-IT, die Zeit, Qualität und Innovationen kostet.
- Beschleunigung der Prozesse – damit werden Preis- und Sortimentsanpassungen in wenigen Minuten anstelle von 30 – 50 Minuten pro Updatelauf durchgeführt.
- Höhere Datenqualität & bessere Governance durch integrierte Validierungsregeln und Plausibilitätsprüfungen.
- Entlastung und bessere Usability für Fachabteilungen – ein wichtiger Schritt gegen Schatten-IT, da fachliche Zusammenhänge sichtbar werden und aufwändige Excel-Analysen entfallen.
Individualsoftware für digitale Herausforderungen
PostGraphile-Schema erweitern & verfeinern



Computed Columns
Was ist, wenn wir nicht nur Informationen von unserer Datenbank aus unserem GraphQL-Schema halten, sondern auch hinzufügen wollen?
PostGraphile gibt uns bereits die Möglichkeit, die Relation zwischen Writer und Blogpost aus unserem Beispiel abzufragen. Jedoch wollen wir bei einer Abfrage eines „Writer“ direkt sehen, wie viele Blogposts dieser Autor bereits verfasst hat; idealerweise ohne dazu extra Queries ausführen zu müssen und auf der Seite des API-Consumers mühselig zusammen zu zählen.
{
writerById(id: $id) {
id
lastname
name
nickname
nodeId
numberOfAuthoredPosts -- Als Computed Column anlegen.
}
}
Wir wünschen uns also ein Feld `numberOfAuthoredPosts`, welches uns die Anzahl der Blogposts gibt, die dieser Writer verfasst hat.
Um noch ein weiteres Beispiel abzudecken, wollen wir auch, dass bei Blogposts der Namen des Autors als `$Vorname $(Spitzname) $Nachname` verfügbar wird. Wobei der Spitzname nur hinzugefügt wird, sofern der betroffene Autor einen hinterlegt hat.
{
blogpostById(id: $id) {
content
id
nodeId
blogpostType
title
writerDisplayName -- Als Compued Column anlegen.
}
}
Zusätzliche Felder an Entitäten
Computed Columns erlauben uns, zusätzliche Felder an Entitäten in unserem GraphQL-Schema zu definieren. Die Werte für das zusätzliche Feld werden von PostGraphile mit Hilfe von SQL-Funktionen befüllt. Wir können also in unserer schema.sql einfach Funktionen deklarieren und PostGraphile kann automatisch erkennen, dass es sich um eine Computed Column handelt, wenn wir ein paar einfache Konventionen einhalten:
Kurze Unterbechung
Das ist dein Alltag?
Keine Sorge – Hilfe ist nah! Melde Dich unverbindlich bei uns und wir schauen uns gemeinsam an, ob und wie wir Dich unterstützen können.
- Der Name der Funktion muss mit dem Namen der betroffenen Tabelle übereinstimmen, gefolgt von einem „_“.
- Das erste Argument einer solchen Funktion hat den Typen der betroffenen Tabelle.
- Die Funktion darf nicht VOID als Rückgabetypen haben.
- Muss in SQL als `STABLE` oder `IMMUTABLE` markiert sein.
- Die Funktion muss im selben PostgresSQL-Schema definiert sein wie die betroffene Tabelle.
Funktionen die mit `VARIADIC` deklariert sind, sowie Überladene Funktionen, werden derzeit nicht unterstützt. PostGraphile kann also nur Funktionen verwenden, bei denen alle Argumente definiert sind.
Für unser Beispiel legen wir also eine Datei functions.sql an und beginnen mit der Funktion, mit der wir bei der Tabelle Writer die Anzahl der verfassten Blogposts lesen wollen:
CREATE FUNCTION writer_number_of_authored_posts(writer_in writer) RETURNS INT
STABLE
LANGUAGE SQL AS
$$
SELECT COUNT(id) FROM blogpost WHERE writer_id = writer_in.id
$$
Schon finden wir das Feld `numberOfAuthoredPosts` in unserem Schema:
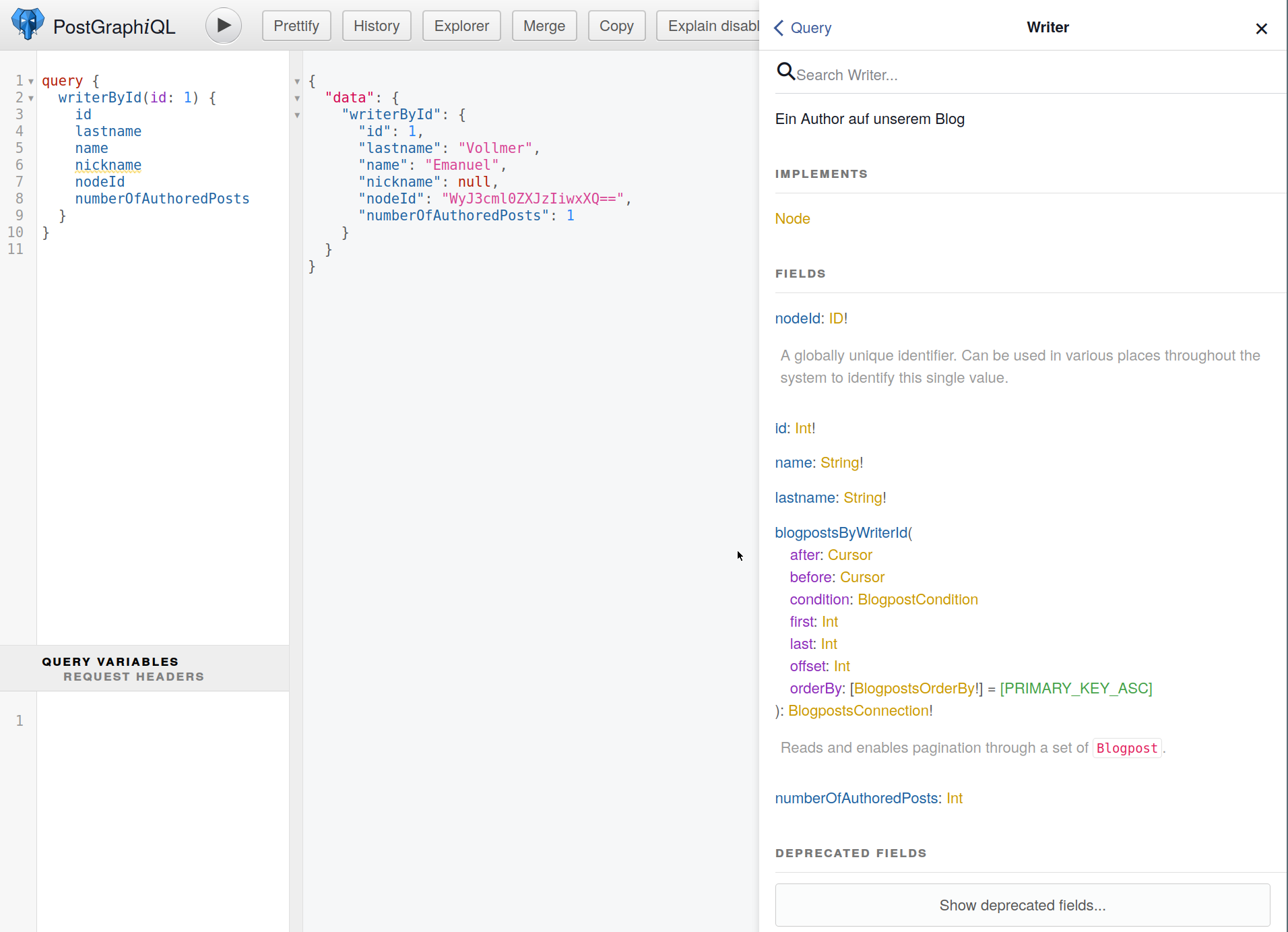
Auf die selbe Weise können wir nun auch unsere Blogposts um das `writerDisplayName`-Feld erweitern:
CREATE FUNCTION blogpost_writer_display_name(blogpost_in blogpost) RETURNS TEXT
STABLE
LANGUAGE plpgsql AS
$$
DECLARE
author writer;
BEGIN
SELECT *
FROM writer
WHERE id = blogpost_in.writer_id
INTO author;
IF (author.nickname IS NOT NULL) THEN
RETURN author.name || ' (' || author.nickname || ') ' ||
author.surname;
ELSE
RETURN author.name || ' ' || author.surname;
END IF;
END
$$
Nun finden wir bei erneutem Blick ins Schema auf GraphiQL den `writerDisplayName`, mit Beispielen für beide Fälle, also ob ein Spitzname verwendet wird oder nicht:
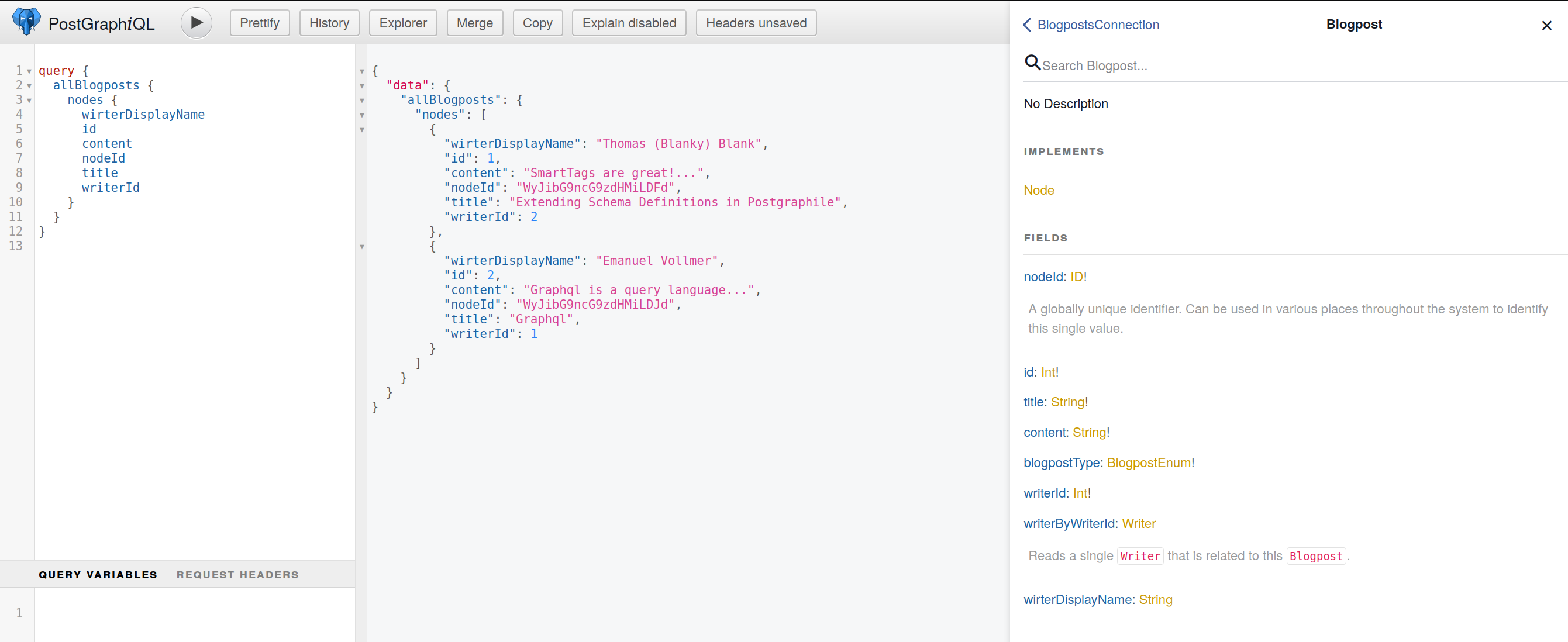
Wenn wir uns also an ein paar einfache Konventionen halten, können wir unser GraphQL-Schema mit beliebiger Information füllen indem wir SQL-Funktionen definieren, die unseren Anwendungsfall abdecken.
… es geht auch komplexer
Die hier gezeigten Beispiele sind ein wenig simpel gehalten. Für uns sind jedoch alle Regeln von SQL-Funktionen erlaubt! Wir können mit Hilfe von Computed Colums in Zukunft auf eine deklarative Art per SQL-Funktionen inklusive dortiger Features wie Transaktionen, Typecasts und allem was unser Herz begehrt unser Schema beliebig anreichern!
Auch zusätzliche Argumente können bei Computed Columns sehr einfach verwendet werden:
CREATE FUNCTION writer_job(writer_in writer, job_in TEXT) RETURNS TEXT
STABLE
LANGUAGE SQL AS
$$
SELECT COALESCE(writer_in.nickname,writer_in.name) || ' is a ' || job_in || ' working at Mayflower! -- COALESCE gibt uns den writer.name, falls der betroffene writer keinen nickname hat
$$
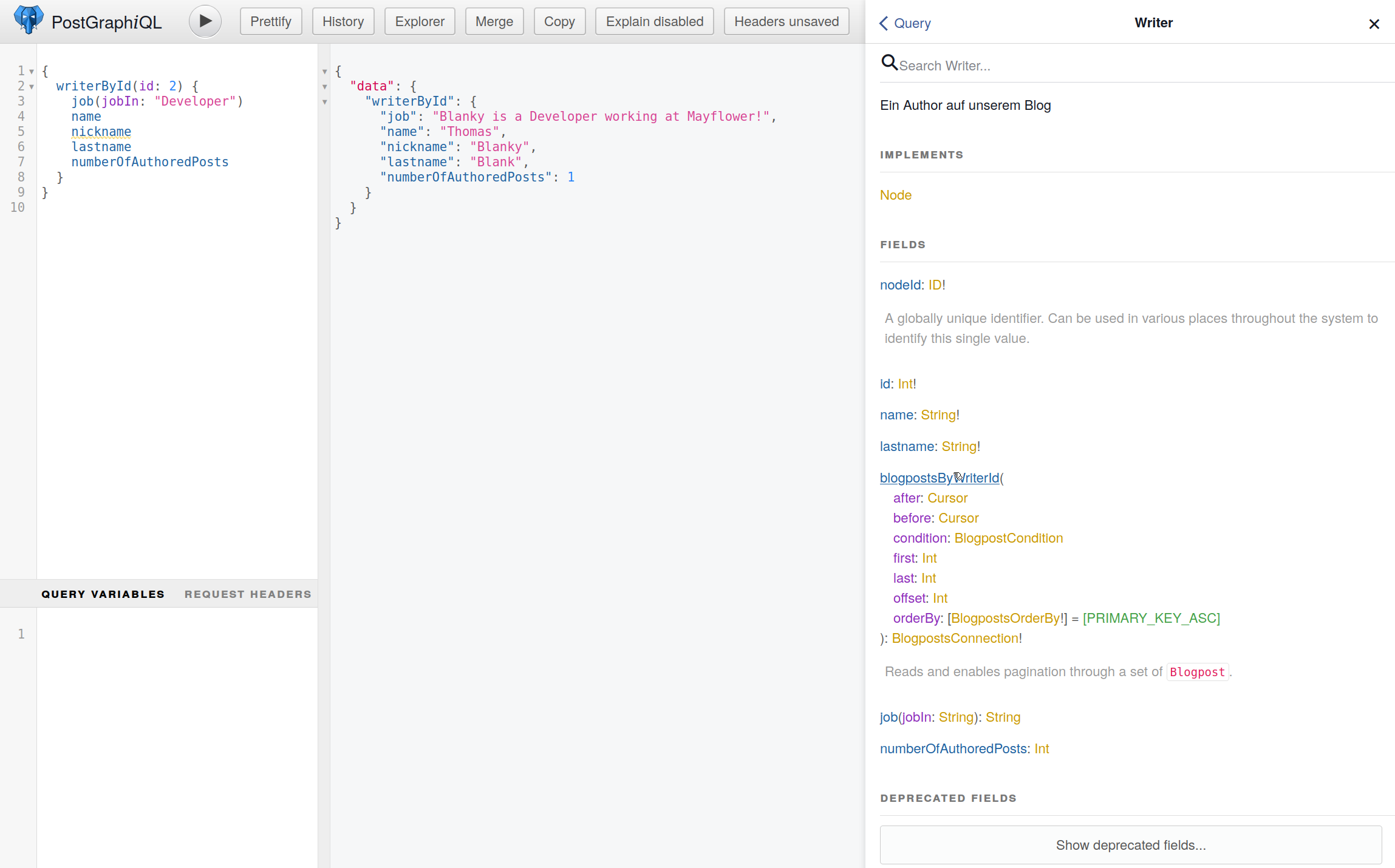
Um unsere Computed Columns noch ein wenig besser zu machen, können wir wieder Smart Tags verwenden, um unsere Spalten sortierbar und filterbar zu machen:
COMMENT ON FUNCTION writer_number_of_authored_posts(writer_in writer) is E'@sortable';
Und schon schenkt Postgraphile uns die Möglichkeit bspw. bei der allWriters-Query, orderBy mit den Argumenten `NUMBER_OF_AUTHORED_POSTS_ASC` und `NUMBER_OF_AUTHORED_POSTS_DESC` verwenden zu können:
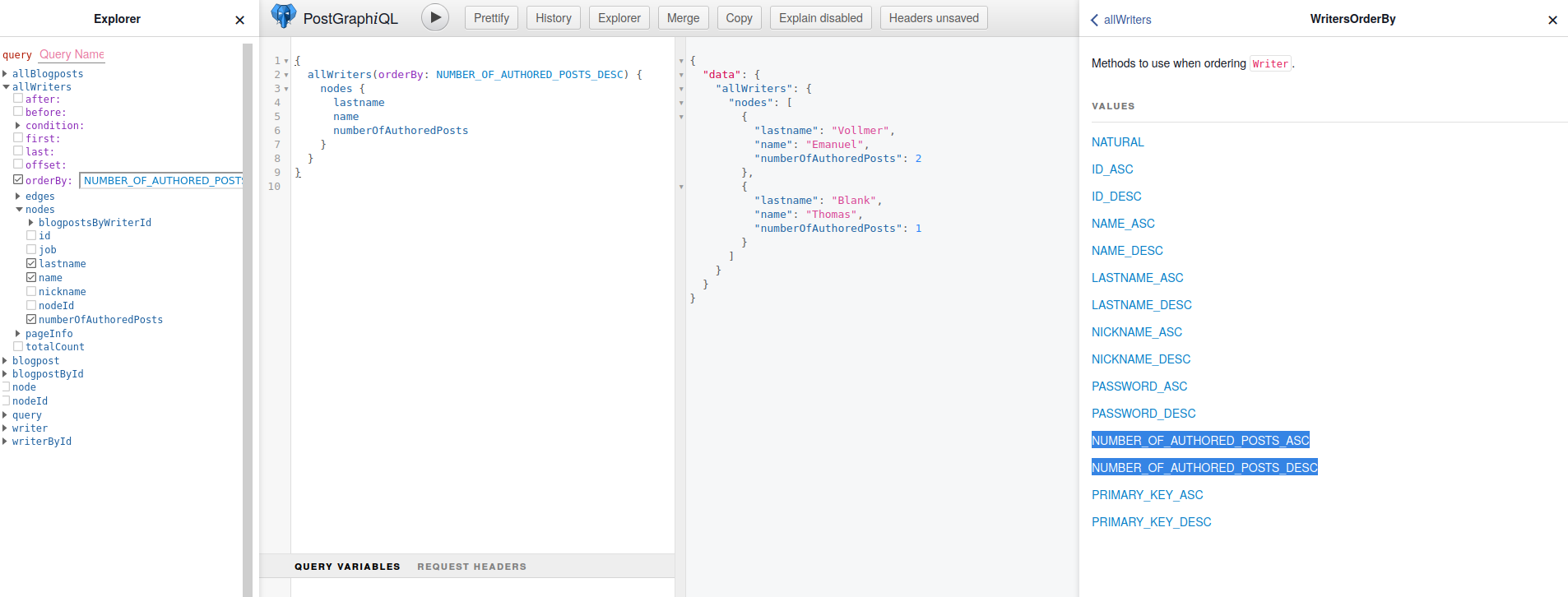
Wenn wir zusätzlich noch filtern wollen (bspw. nach Writern, die nur einen oder zwei Posts verfasst haben), können wir an die selbe Funktion auch den Smart Tag @filterable anbringen:
COMMENT ON FUNCTION writer_number_of_authored_posts(writer_in writer) is E'@sortable\n@filterable';
Und wieder ein Geschenk von Postgraphile: die condition-Funktion, die uns numberOfAuthoredPosts angeben lässt:
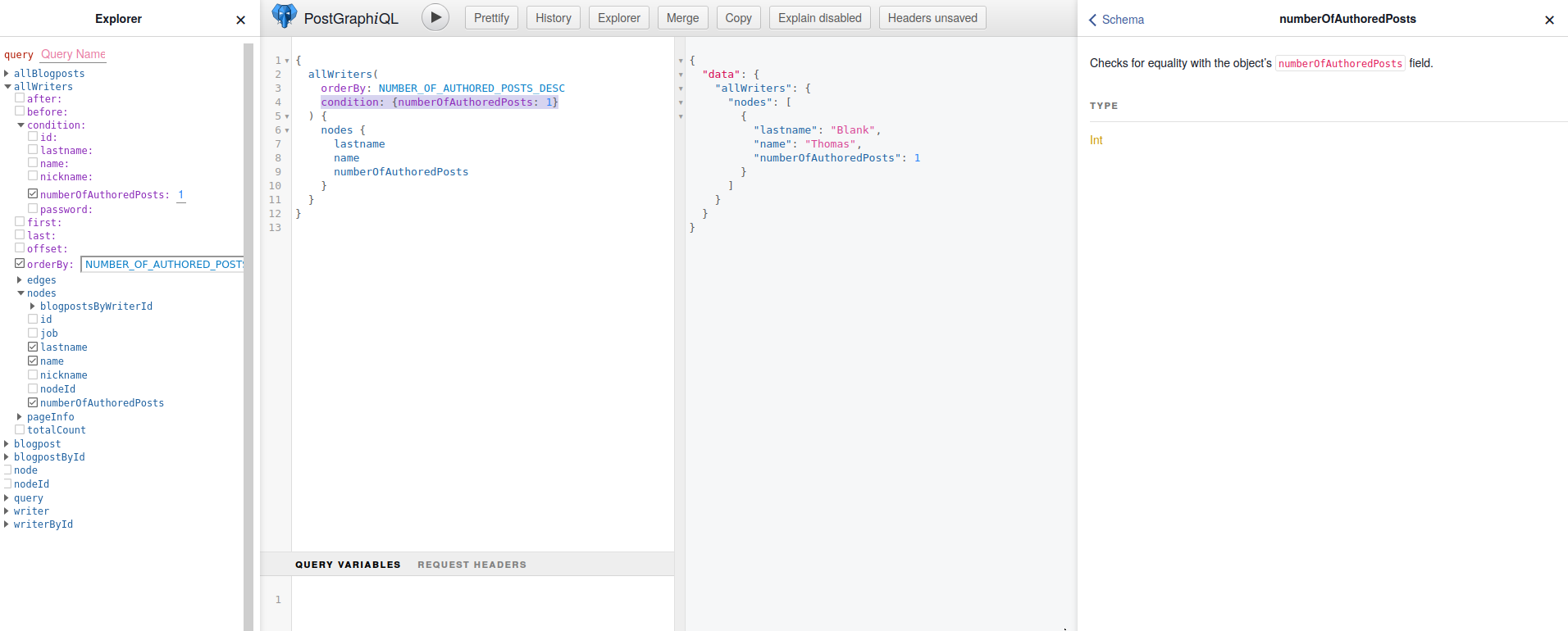
Neue Writer registrieren – Custom Mutations
Wir haben das Passwort-Feld aus unserem Schema verbannt. Wenn wir die createWriter-Mutation jetzt verwenden, bekommen wir folgenden Fehler:
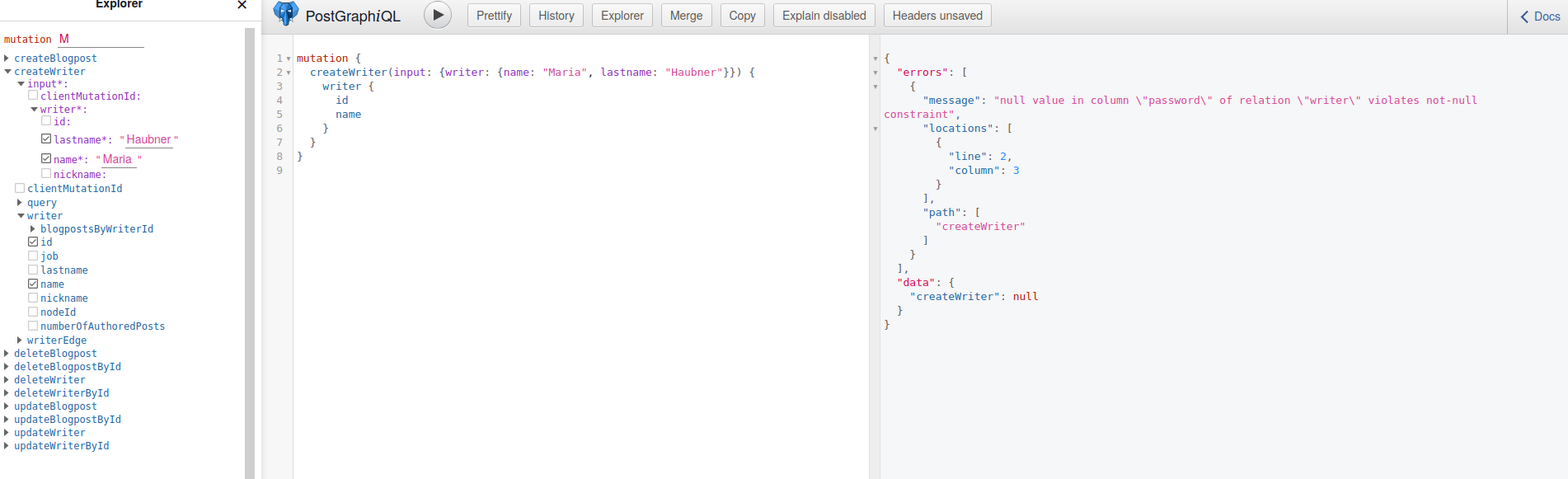
Wie können sich nun neue Autoren bei unserer Plattform registrieren? Und wie stellen wir am besten noch sicher, dass jeder Writer nur ein Profil erstellt (Name + Lastname – Kombination)? Vielleicht wollen wir ja auch ein paar nervige Regeln für Passwörter erzwingen, wie eine Mindestlänge? Dafür deaktivieren wir als erstes die „kaputte“ `createWriter` -Mutation mit: `comment on table writer is E’@omit create‘;`
Dann erstellen wir uns eine SQL-Funktion für die Registrierung:
CREATE FUNCTION writer_register(name text, lastname text,
password text,
nickname text = NULL
) RETURNS writer
STABLE
LANGUAGE plpgsql AS
$$
DECLARE
result writer;
BEGIN
IF (SELECT EXISTS(SELECT 1
FROM writer w
WHERE w.name = writer_register.name
AND w.surname = writer_register.lastname)) THEN
RAISE EXCEPTION 'Writer with the same name and lastname already exists!';
END IF;
IF (LENGTH(writer_register.password) < 8) THEN
RAISE EXCEPTION 'Password is not strong enough! Should be at least 8 characters long!';
END IF;
INSERT INTO writer (name, surname, nickname, password)
VALUES (writer_register.name, writer_register.lastname,
writer_register.nickname,
crypt(writer_register.password, gen_salt('bf', 8)))
RETURNING * INTO result;
RETURN result;
END
$$:
Die SQL-Funktion kümmert sich für uns schon darum, dass Name + Lastname zusammen nicht erneut vergeben werden und dass unser Passwort mindestens acht Zeichen lang bleibt. Mit einem Blick auf unser GraphiQL finden wir die neue Mutation:
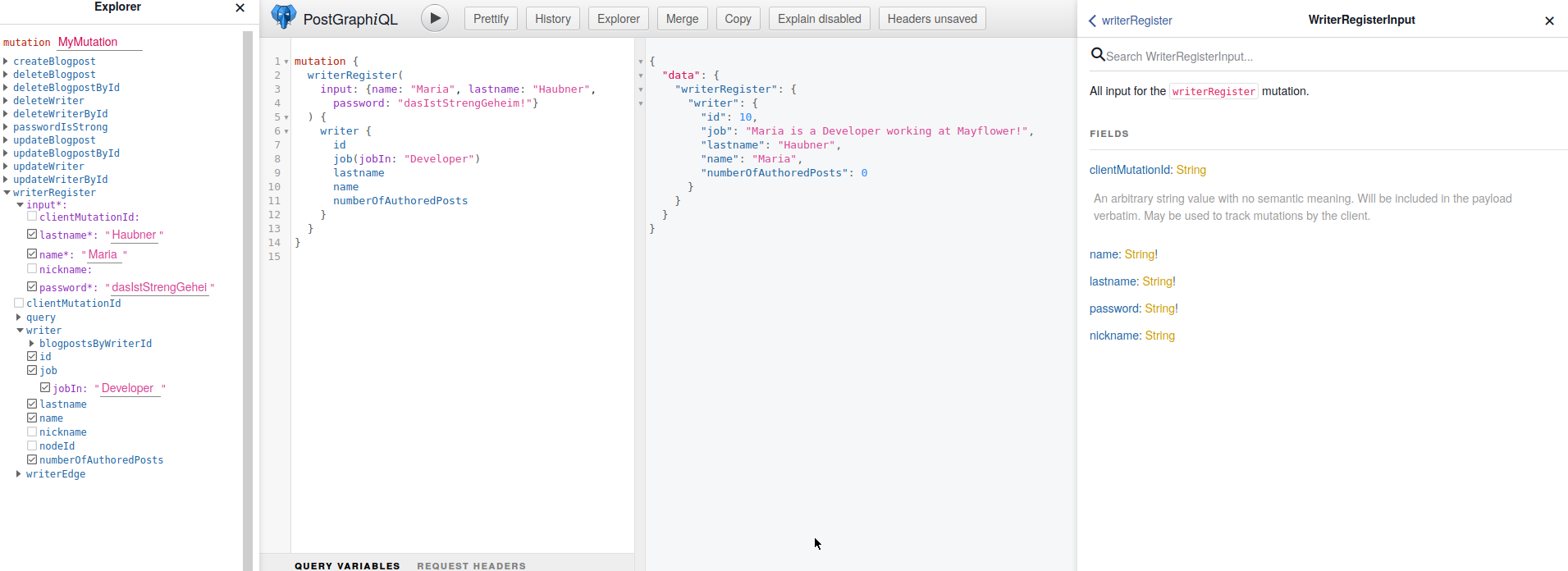
Wer mag, kann ja einfach mal ausprobieren gegen unsere „Regeln“ zu verstoßen und mit einem kürzeren Passwort oder bereits vergebenen Daten eine Registrierung auszuführen und zu testen, was PostGraphile hier mit unserem „RAISE EXCEPTION“ in der GraphQL-Antwort macht.
Ausblick
Wir haben also die Möglichkeit, komplett frei mit Computed Columns zu entscheiden, was wir noch zusätzlich in unserem Schema haben wollen. Mit den Smart Tags, die wir im vorherigen Post schon kennengelernt hatten, können wir auch unsere Computed Columns noch mit Extra-Features wie Sortierung und Filterung anreichern.
Dann haben wir noch unsere Registrierung repariert und mit unseren eigenen Regeln versehen.
Weil das ja noch immer nicht genug ist, packen wir im nächsten Post die Keule aus und zwingen PostGraphile mit Hilfe des großartigen Plug-In-Systems unseren Willen auf!
… kleiner Spoiler vorneweg: Es wird Katzenbilder geben!
PostGraphile in-depth







Schreibe einen Kommentar