
Um eine ehemalige Kollegin zu zitieren: Ach lass, ich mach’s selber.
Wisst ihr eigentlich, dass ihr schwerer zu hüten seid als ein Sack voller Flöhe? Wenn ich mir die Heatmaps so ansehe: Ja, so springen Flöhe auch in der Gegend herum. Aber eins nach dem Anderen.
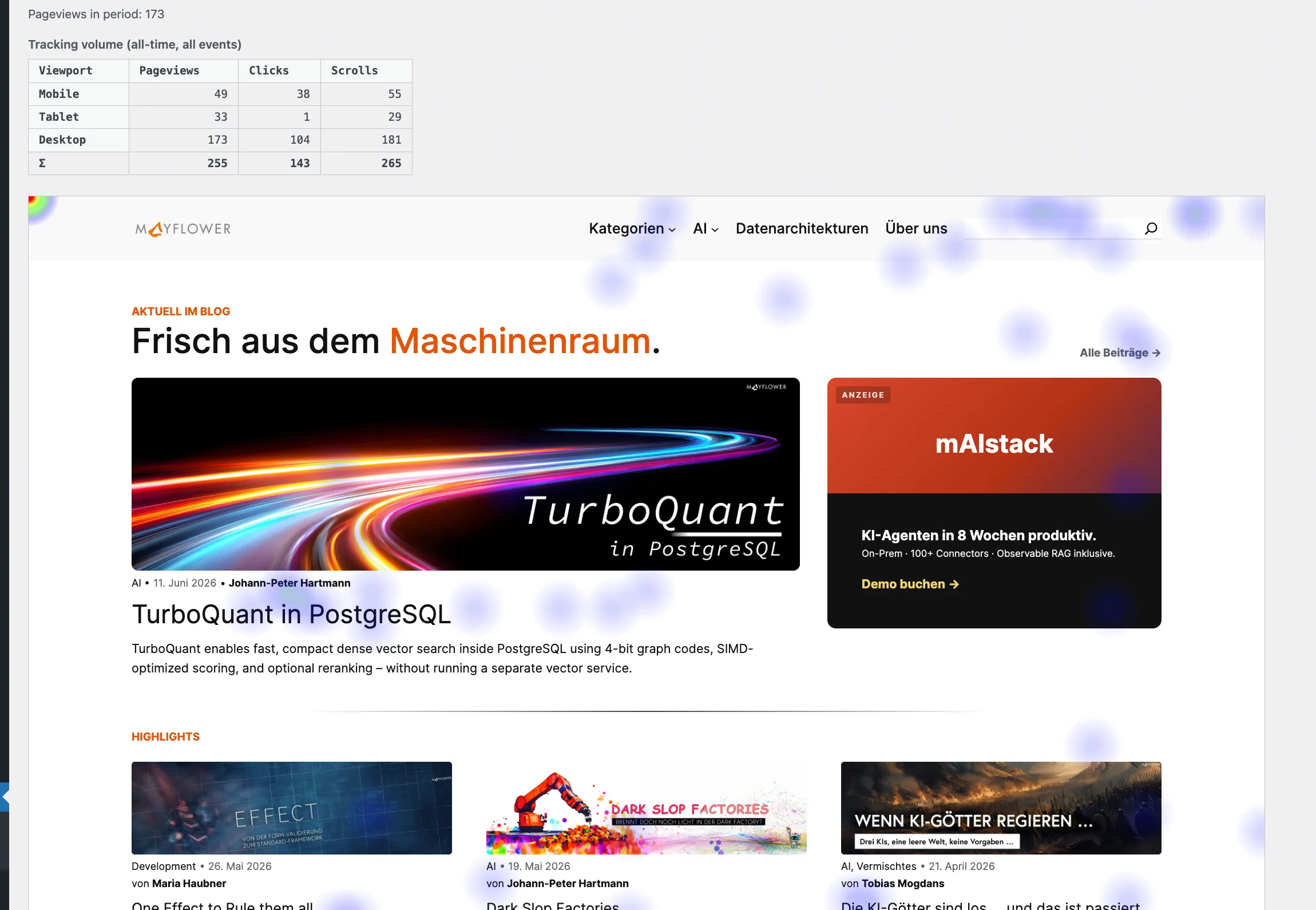
Es ergab sich die – in meinem Feld (Gestatten? Tom, Marketing.) – ganz normale Frage: Wo klicken eigentlich die Leute auf unserer Webseite? Welche Buttons funktionieren, welche werden ignoriert? Wie weit scrollt jemand auf einer Landingpage, bevor er entnervt den Tab schließt?
Was ich wollte, klang trivial. Heatmaps. Einfach mal sehen, was passiert.
A ✓ Kurze Unterbrechung · Amicable Schatten-IT bleibt. Also sanktioniere sie. 10% offene DBs bei Lovable Semgrep-Scans · isolierte Sandboxes · GitLab-versioniert Amicable Entdecken →Was ich nicht wollte, war ebenso klar: Hotjar nicht, Clarity nicht. Null zusätzliche Zeilen im Cookie-Banner. Keine Drittanbieter, die irgendwo auf einem anderen Kontinent Daten unserer Besucher:innen kreuzkorrelieren. Keine Session-Replays. Niemand soll identifizierbar sein – auch nicht pseudonym.
Bier auf (könnte sein, dass es noch früher Nachmittag war … also einigen wir uns auf einen Kaffee). Bisschen Recherche. Wie schwer kann es schon sein, ein DSGVO-konformes Open-Source-Heatmap-Tool zu finden?
Spoiler: geht-so-schwerer als gedacht.
Die Open-Source-Wüste
Erster Anlaufpunkt: Claude. Nicht zum Bauen. Zum Recherchieren. Was gibt es da draußen?
Die Antwort kam ernüchternd:
- ploi/heatmap – Open Source, MIT-Lizenz, macht genau eines: Heatmaps. Klang perfekt. Bis ich gesehen habe, dass das Projekt seit vier Jahren keinen Commit mehr hatte. Pass.
- PostHog – Open Source, self-hostable, hat alles. Habe ich mich schon gefreut, bis ich gesehen habe: „As of May 2023, PostHog no longer supports Kubernetes deployments.“ Mein Deployment-Ziel wäre unser interner K8s-Cluster gewesen. Pass. Mit Sternchen dran.
- Matomo – Open Source, aber die Heatmap-Funktion ist ein kostenpflichtiges Plugin von InnoCraft. Und es koppelt Heatmaps zwangsläufig mit Session Recording. Genau das, was ich nicht wollte. Pass.
- Microsoft Clarity – kostenlos, aber kein Self-Hosting. Daten gehen zu Microsoft. Pass.
Drei Stunden Recherche. Wenig brauchbare Ergebnisse. Zum Glück wurde das Bier nicht schal.
Selber machen (lassen)
Wenn es da draußen nichts gibt, bleiben zwei Optionen: das Thema vergessen, oder selbst bauen.
Vergessen war keine Option. Aus Prinzip schon nicht. Unser SonarQube brauchte neues Futter, ich hatte Blut geleckt … und die Eingangsfragen waren noch immer nicht beantwortet. Also: Lieber Claude, wenn wir das Projekt selbst umsetzen … wie lange brauchen wir?
Die Antwort war wie üblich sehr konkret. Zwei, vielleicht drei Wochen für eine produktive Version. Oder, na ja, was Claude eben so denkt, wie lange zwei bis drei Wochen in KI-Zeit dauern. Architektonisch kein Hexenwerk: Ein JavaScript-Snippet, das Click-Koordinaten und Scroll-Tiefe sammelt. Ein Backend, das die Daten sofort in Buckets aggregiert (kein Event-Storage, also nichts Personenbeziehbares). Eine Admin-UI mit Heatmap-Overlay. Fertig.
Spannend an der Diskussion: die Stolpersteine. Layout-Änderungen, die alte Heatmaps unbrauchbar machen. SPAs ohne richtigen Pageload. Responsive Viewports, die separat behandelt werden müssen.
20×20
Klicks landen auf einem 20×20-Pixel-Raster, bevor sie überhaupt zur Datenbank wandern. Aus einem 1920×1080-Viewport wird so ein 96×54-Grid. Granular genug, um zu sehen, welcher Button die Aufmerksamkeit abbekommt. Viel zu grob, um daraus die exakte Cursor-Bewegung einer Person zu rekonstruieren.
Und egal, wie wild jemand klickt: Die Datenbank sieht pro Request maximal drei SQL-Statements. Aggregiert wird im PHP-Memory, bevor die DB überhaupt davon erfährt – dann fliegt pro Tabelle ein einziger INSERT … ON DUPLICATE KEY UPDATE raus. Kein Event-Stream. Keine „Letzten 1000 Klicks von User XY“. Das Plugin könnte gar keine Session rekonstruieren, selbst wenn es oder ich es wollte.
Übrigens: Der Tracker prüft vor jedem Request navigator.doNotTrack === "1" und navigator.globalPrivacyControl === true. Wenn die gesetzt sind, herrscht komplette Schweige-Pflicht, der Server erfährt nicht mal, dass jemand existiert.
Und weil es so schön ist, gibt es noch eine Kleinigkeit: Selbst die Server-Antworten sind identisch, egal ob ein Klick gespeichert wurde, der Post nicht existiert oder die Daten Müll waren. Wer von außen lauscht, lernt: nichts.
Na gut, denk ich mir. Problem von Zukunfts-Tom. Aber dann war da ja noch eine andere Sache …
Plot-Twist: WordPress-Plugin
Zwischen Bier … Kaffee drei und fünf fiel mir irgendwie wieder ein, dass wir ja das Ganze auch als WordPress-Plugin bauen könnten.
Weil unsere Webseite läuft auf WordPress. Wir haben einen eigenen Server. Mehr als 50.000 Pageviews am Tag haben wir selten … ein Plugin würde eigentlich alles deutlich einfacher machen:
- Kein separater Server, kein K8s, kein Helm-Chart, kein nichts
- WordPress-DB statt eigener Postgres-Instanz
- WordPress-Auth statt OIDC-Setup
- Heatmaps an Post-IDs gekoppelt statt an URLs; das löst zumindest schon mal das URL-Problem (Slug ändert sich, Heatmap überlebt). Das echte Layout-Problem – Hero-Block wird neu gebaut, alte Klicks landen plötzlich auf der falschen Position – bleibt offen. Aber gut, dafür ist ja Zukunfts-Tom da.
- Aufwand: rund die Hälfte des Standalone-Projekts. Sagt Claude.
Und noch besser: Wenn ich das schon baue, kann ich es als Open-Source-Plugin auf WordPress.org veröffentlichen. Es gibt in dem Bereich eine echte Lücke; alle existierenden Heatmap-Plugins sind entweder Hotjar-Wrapper oder kostenpflichtig. Zwei Sternchen dran.
Bingo. Verschmitzt lächelnd noch mehr Ehrgeiz in den Fingern.
Spezifikation
Mal unter uns: Das ist ja nicht das erste Plugin, das ich baue. Viele Kleinigkeiten sind wegautomatisiert, viele Spielereien mittlerweile in kleine Plugin-Sammlungen gegossen, damit sie auch jeder im Team anwenden kann.
Auf dieser Reise habe ich viel Blödsinn versucht. Einsilbige Prompts, die je einen kleinen Teil des gewünschten Features beschreiben.
Nicht meine beste Idee.
Irgendwann Ralph-Loops, die zwar funktionierten, in ungünstigen Fällen mein Fünf-Stunden-Limit aber schneller durchprügelten als der Kollege vom THW und ich die erste Halbe bei einem sommerlichen Grillgelage auf der Dachterrasse.
Zielführend? Na ja … zumindest nicht meine dümmste Idee.
Aktuell fahre ich einen Mittelweg: Spezifikationen ausarbeiten, daraus einen Implementierungsplan erstellen, dann mehr-oder-weniger betreutes Entwickeln-lassen. Die Dark Factory ist noch nicht ganz hier angekommen.
Von der Anforderung zur Architektur
Erst die Anforderungen rausgearbeitet:
- Tracking nur auf explizit aktivierten Seiten (Opt-In per Checkbox im Editor)
- Eingeloggte Nutzer:innen standardmäßig ausschließen, rollenbasiert konfigurierbar
- Mobile, Tablet, Desktop separat
- Datenschutz-Story: keine Cookies, keine IDs, keine IPs, nur aggregierte Counter, automatische Löschung nach 90 Tagen
Dann die Architektur:
- Datenmodell mit drei Tabellen (Clicks, Scrolls, Pageviews)
- REST-Endpoint mit Origin-Check als CSRF-Schutz
- Frontend-Tracker in TypeScript, ~2 KB minified
- Admin-Dashboard mit
iframe-Renderer undheatmap.js-Overlay (statt komplizierter Screenshot-Pipeline) - Retention-Cron, der nach 90 Tagen alle Daten löscht
Dann die Compliance-Schicht, und schließlich die Test- und Qualitätsstrategie:
- PHPUnit Unit- und Integration-Tests
- Vitest für den TypeScript-Tracker
- Playwright für End-to-End-Tests
- SonarQube angeschlossen, Quality Gate bei ≥85% Coverage, A-Rating für Security
- GitHub Actions für CI/CD

Spec, TODO, fertig
Das Ergebnis: eine Spec mit 23 Abschnitten, ungefähr 4.000 Zeilen Markdown. Ready für die Umsetzung.
Daraus wurde dann eine TODO.md generiert: 21 Phasen, etwa 85 sequentielle Aufgaben. Jede mit klaren Acceptance-Kriterien und einem Notes-Block zum Ausfüllen. Damit Claude Code später nicht nur weiß was zu tun ist, sondern auch in welcher Reihenfolge, und dokumentieren kann, was passiert ist.
Merk’s dir selbst
Warum eine TODO.md mit angeschlossenem Gedächtnis? Claude arbeitet die Liste sequenziell ab. Er hakt die Punkte ab, mit denen er fertig ist und macht sich Notizen, warum etwas wie umgesetzt wurde. Bei Blockern meldet er sich.
… und manchmal, wenn er wieder vergessen hat, welche Dateien er anfassen darf. Oh well.
Jedenfalls arbeitet er sich so durch die Phasen und notiert sich Dinge, die später erledigt werden müssen oder die unter Umständen zu einem Problem werden könnten. Wo wir übrigens gerade über Phasen reden:
Phase 1: Repository-Setup, Composer-Konfig, NPM-Konfig, PHP-Tooling, JS-Tooling, SonarQube-Konfig, Plugin-Header. Abgehakt, notiert, weiter.
Phase 2: Datenbank-Schema mit allen dbDelta-Quirks (zwei Leerzeichen nach PRIMARY KEY, sonst läuft das Ding nicht idempotent – Claude wusste das aus der Spec). Activator, Deactivator, Migrator, Integration-Tests. Abgehakt.
Phase 3 bis 13: Storage-Layer, REST-API, Tracker, Admin-UI, Meta-Box, Viewer mit iframe-Overlay, Retention-Cron, Uninstall-Logik. Mit Tests; mit i18n; mit allen Sanitization-Regeln; mit Plugin-Check-Compliance.
Phase 14 bis 20: Internationalisierung, lokale Quality Gates, Plugin Check, CI/CD-Workflows, SonarQube-Anbindung.
Ich habe nach jeder vollen Phase pausiert, mir die Notizen angeschaut, gegebenenfalls Klarstellungen gegeben, dann weitergemacht. In insgesamt knapp vier Stunden durch die Implementierung. Und dann das Deployment … da mag er mich nicht, aber höchstwahrscheinlich bin ich ja das Problem.
Brace Yourself, Results are Coming
Ein WordPress-Plugin. Open Source. Läuft jetzt schon etwas länger ohne Probleme. SonarQube ist grün, das Plugin Check Tool meldet null Errors aus der Repository-Kategorie.
Und – das wichtigste – die ersten Heatmaps zeigen interessante Dinge. Unser CTA-Button auf der Karriere-Seite ist tatsächlich zu weit unten. Der Scroll-Drop-Off auf unserer wichtigsten Landingpage liegt bei 47% – die Hälfte der Besucher sieht unseren eigentlichen Hauptinhalt nie.
Und ihr? Drop-Off auf der Blog-Startseite bei etwas mehr als 40 %. Ihr seht gar nicht, dass auf der Startseite noch ein paar spannende Sachen zu finden wären. Das wäre ohne Daten reine Vermutung gewesen. Jetzt ist es eine handlungsrelevante Erkenntnis.


Also: Scrollt weiter nach unten!
Das goldene Setup …
… das bei mir funktioniert hat:
- Erst denken, dann bauen. Mit Claude im Chat das Problem vollständig durchgekaut, bevor irgendeine Datei angelegt wurde.
- Spec schreiben. Eine vollständige, ausführliche Spezifikation. Klingt nach Overhead, ist aber mein Geheimnis. Jede Frage, die in der Spec geklärt ist, muss Claude später nicht raten.
- TODO sequenziell aufteilen. Aus der Spec wird eine Abarbeitungs-Reihenfolge mit Acceptance-Kriterien. Damit weiß Claude immer, was als nächstes ansteht.
- Notes-Block ist Pflicht. Claude dokumentiert nach jeder Aufgabe, was er gemacht hat. So bleibt nachvollziehbar, was passiert ist – und Probleme werden sichtbar, bevor sie sich verstecken.
- Quality Gates härter machen, nicht weicher. SonarQube, Plugin Check, Linter, Type-Checker – alle scharf gestellt. Lieber dreimal nachbessern als später mit halb funktionierendem Code dastehen. (Und ja, meine Commit-Historie würde manch einer als gruselig beschreiben)
- Phasenweise pausieren. Nach jeder Phase kurz draufschauen. Nicht ganze Tage durchlaufen lassen. So weit wie Johann bin ich noch nicht.
- MCPs öffnen Claude die externen Systeme. SonarQube-Befunde, Browser-Network-Logs, Live-DB-Inhalte – alles im selben Flow. Der Agent kann seinen eigenen Output verifizieren, nicht nur produzieren.
Was ich gelernt habe
Bla. Irgendwas mit Ende (oder auch nicht) von Softwareentwicklung. Will sagen: Möglicherweise sollte hier eine Reflexion zum „Ende der Softwareentwicklung“ hingehören. Aber wer bin ich, das zu beurteilen?
Mein Job aber verändert sich ebenfalls. Wo es früher hieß Bitte werfen sie noch eine Münze ein, baut man sich heute die Plugins (und noch so einiges mehr) selbst. Zielgerichtet auf die Anforderung, integriert in das bestehende Ökosystem.
Ja, Software entsteht gerade en masse. Und ja, manchmal dürfte sie mehr Lücken aufreissen als wirkliche Probleme lösen. Das verändert nicht die Notwendigkeit von Engineering. Aber es verändert, wer in welcher Phase mitdenken kann.
Vielleicht nicht die schlechteste Idee.
Was bleibt?
Ein WordPress-Plugin, das Heatmaps in vier Stunden Implementierung produktiv gebracht hat. Eine Spec, die sich rückwirkend als die wertvollste Investition entpuppt hat. Und die Erkenntnis, dass die Flöhe nicht einfacher zu hüten werden. Aber jetzt sehe ich wenigstens, wo sie hinspringen. Und kann meine Schlüsse daraus ziehen.
Mit Sternchen dran: Mittlerweile haben wir auch eine PostHog-Instanz auf unserem Cluster laufen. Was auch läuft: Die Evaluation. Es bleibt spannend.
Zwei Sternchen dran: Nun, am Ende habe ich mich doch dagegen entschieden, das Plugin auf WordPress zu veröffentlichen. Ist es hilfreich? Klar. Funktioniert es? Yup. Fühlt es sich fertig an? Nicht die Bohne. Seit ich den Post hier begonnen habe, sind zahlreiche Verbesserungen eingeflossen. Ein PDF-Export der Ergebnisse, beispielsweise. Und ein Bugfix, denn wie sich herausstellt sind vh in iFrames eher … schwierig. Mal sehen, was die nächste Zeit noch an neuen Features mit sich bringen.

Schreibe einen Kommentar