
Dense vector search looks deceptively simple from SQL:
SELECT id, title FROM documents ORDER BY embedding <~> turbohybrid_query(vector_query => $1::vector) LIMIT 10;
The hard part is everything that happens underneath. A database has to compare a query embedding with enough candidate vectors to find good nearest neighbours, while keeping latency low and memory use predictable. Once a table grows to hundreds of thousands or millions of rows, dense retrieval is not just a math problem. It is a memory-layout, cache, and query-execution problem.
pg★ Kurze Unterbrechung · Open Source Der Code zur Serie. Auf GitHub, zum Selberrechnen. Dense Hybrid Late Interaction pgturbohybrid · PostgreSQL-Extension GitHub Repo öffnen →pgturbohybrid approaches that problem with TurboQuant: a compact dense retrieval path that stores quantized graph codes instead of full float vectors in the index fast path. The goal is not to make dense retrieval mysterious. The goal is to make it practical inside PostgreSQL.
This article explains how the dense path works, why 4-bit graph codes can be fast, how approximate scoring is corrected and optionally reranked, and how to use it from SQL.
Why dense vector search gets expensive
A dense embedding turns text, images, or other objects into a vector of floating-point numbers. For text retrieval, a document chunk might become a 768-, 1,536-, or 3,072-dimensional vector. At query time, the embedding model turns the query into another vector. Retrieval means finding stored vectors that are close to the query vector.
For cosine-style search, the basic score is related to the dot product:
cosine_distance(q, x) = 1 - dot(q, x) / (||q|| * ||x||)
Lower distance means a better match. For inner product search, larger dot product means a better match, and database operators usually expose that through a smaller-is-better distance form.
The formula is simple. The cost is not. If you have one million vectors with 1,536 dimensions and each dimension is a 32-bit float, the raw vector data is already several gigabytes before indexes, graph edges, visibility metadata, or cache overhead. A fast retrieval engine has to avoid reading and scoring too much full-precision data for every query.
That is where quantization helps.
The dense API in pgturbohybrid
pgturbohybrid is a PostgreSQL extension installed alongside pgvector. It uses pgvector’s vector type, but provides its own turbohybrid index access method and operator classes.
A dense-only table can look like this:
CREATE EXTENSION vector;
CREATE EXTENSION pgturbohybrid;
CREATE TABLE documents (
id bigserial PRIMARY KEY,
title text,
body text,
embedding vector(1536)
);
Create a dense TurboHybrid index:
CREATE INDEX documents_dense_idx
ON documents
USING turbohybrid (
embedding vector_cosine_turbohybrid_ops
);
Query it with turbohybrid_query(...):
SELECT id, title
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector
)
LIMIT 10;
The SQL shape intentionally looks like normal PostgreSQL: an indexed ORDER BY ... LIMIT query. The difference is the index access method behind it.
What TurboQuant stores
A straightforward dense index could store full vectors in graph nodes and use exact float scoring for candidate comparisons. That is simple, but expensive. TurboQuant uses a different layout: encode the vector into a compact code, store that code in the index, and score graph candidates using the compact representation.
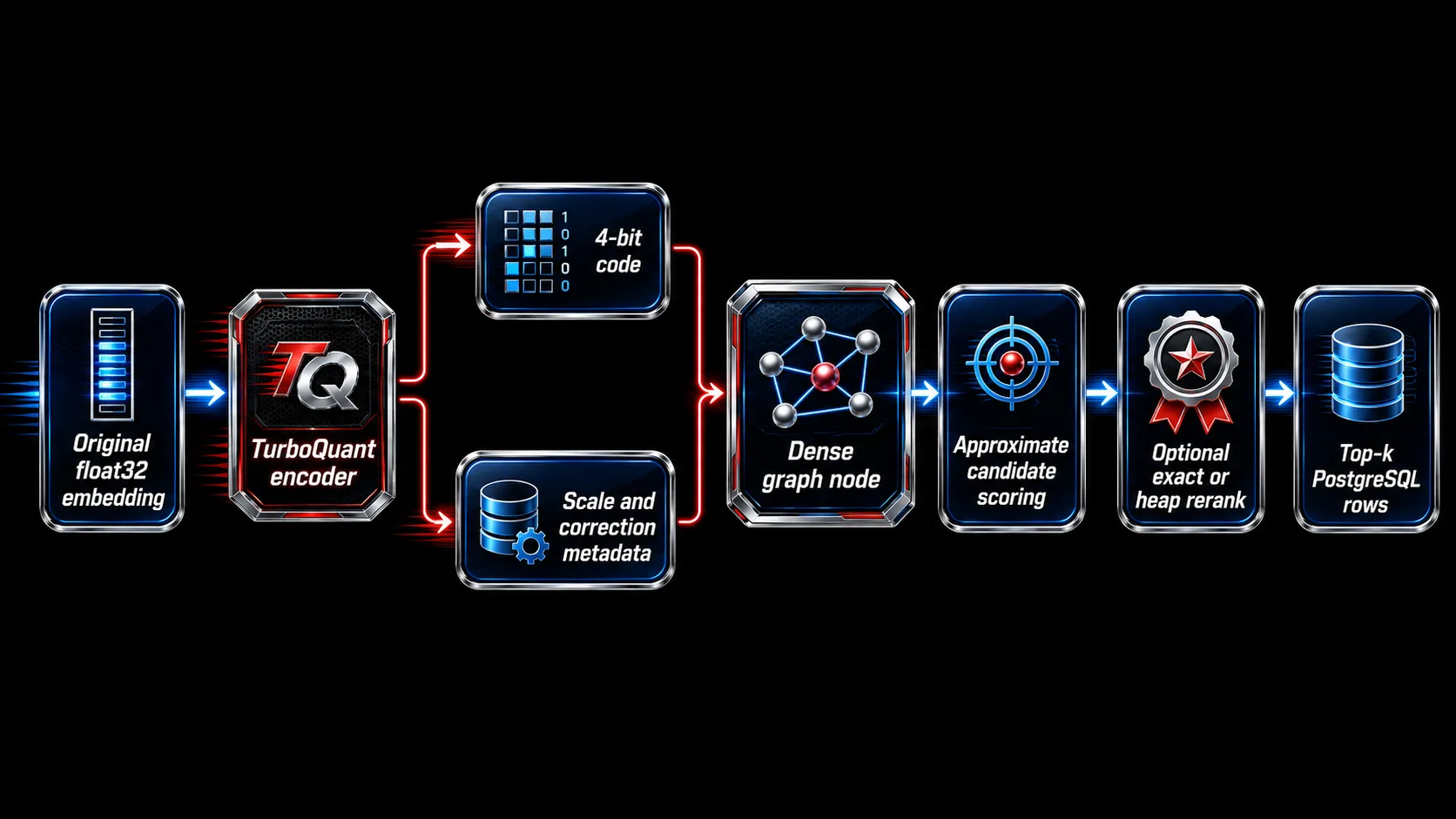
At a high level, each vector coordinate is mapped to a small codebook value. With 4-bit quantization, each coordinate can be represented by 16 possible code values. This reduces storage dramatically compared with keeping a 32-bit float per coordinate in the index fast path.
A useful mental model is:
float32 vector x -> compact code c(x) -> scale/correction metadata -> graph node
The code is not the original vector. It is an approximation. The scoring path then estimates the distance between the query and the stored vector using the code plus correction metadata.
A small amount of math
Quantized scoring is an approximation:
approx_score(q, x) ≈ score(q, decode(c(x))) + correction
Where:
qis the query vector.xis the original stored vector.c(x)is the compact TurboQuant code.decode(c(x))is the vector implied by the codebook centres.correctionaccounts for information not captured by the simple code lookup.
In implementation terms, pgturbohybrid’s scoring code works with code centres, per-vector scale values, and correction terms. For some paths, the encoder emits both the quantized code and extra correction metadata in one pass. This lets the scorer get closer to the original vector score without storing the full float vector in the hot index path.
That is the core tradeoff:
use fewer bytes per vector
-> score approximate candidates faster
-> rerank when exactness matters
Why compact codes help
Dense retrieval often bottlenecks on memory movement. The CPU can perform a lot of arithmetic quickly, especially with SIMD instructions. But if every graph step requires scattered reads of large float vectors, the query can spend too much time waiting for memory.
Compact codes change the shape of the workload:

The performance story is not only that 4-bit codes are smaller. It is that smaller codes make graph traversal and candidate scoring friendlier to CPU caches and SIMD kernels.
pgturbohybrid includes scalar fallbacks, but the dense hot path is designed to use hardware-specific kernels where available. On x86 this includes AVX2 and AVX-512/VNNI-family paths. On ARM it includes NEON paths. The implementation also contains query-split scoring paths for high-dimensional 4-bit search and batch scoring paths that score multiple candidates together.
For database users, the practical result is simple: the dense index can score many approximate candidates quickly while staying inside PostgreSQL’s index access method model.
Query path: from SQL to candidates
A dense query follows this shape:
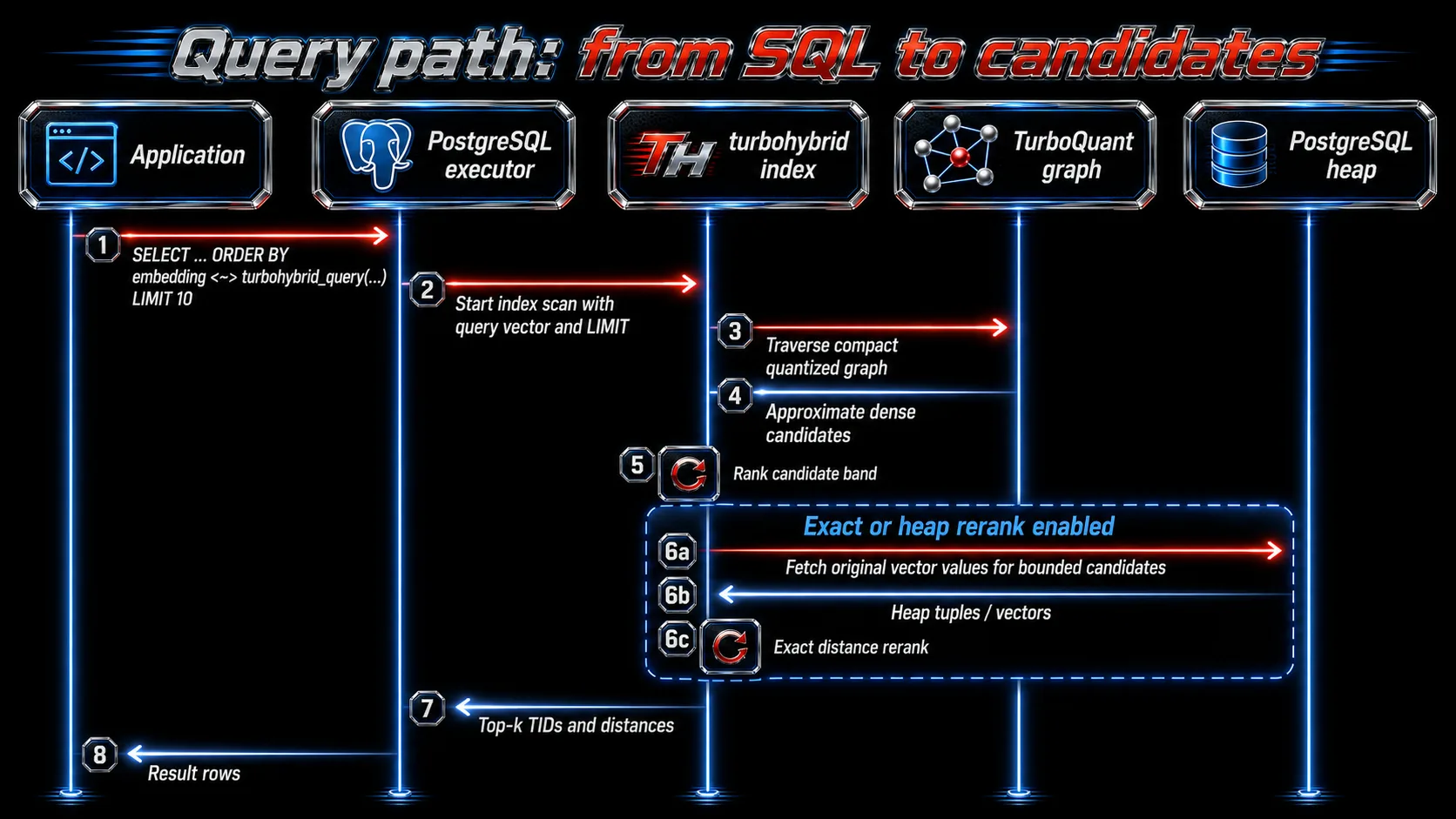
The important PostgreSQL detail is that the SQL LIMIT can become part of the retrieval shape. You ask for top 10 rows; the access method can use that top-k target to keep candidate collection bounded.
Fast path and quality path
The default dense path is meant to be compact and predictable. In the public docs, the fast path uses 4-bit quantization, no exact vector storage in the index, and modest candidate budgets. That is the right starting point when you want low latency and acceptable approximate recall.
SET turbohybrid.profile = 'latency';
When recall matters more than raw throughput, use a profile that spends more work per query:
SET turbohybrid.profile = 'high_recall';
For quality-sensitive evaluation, you can also build an index that stores exact vectors for final rescoring:
CREATE INDEX documents_dense_quality_idx
ON documents
USING turbohybrid (
embedding vector_cosine_turbohybrid_ops
)
WITH (exact_storage = on);
A different option keeps exact vectors out of the index and rescans bounded heap candidates at query time:
SET turbohybrid.dense_heap_rescore = 'topk'; -- or 'band'
The right choice depends on your workload:
| Goal | Typical choice |
|---|---|
| Lowest latency and compact storage | latency profile, 4-bit, exact_storage = off |
| Better recall without storing full vectors in the index | Wider profile, heap rescore, more candidates |
| Highest quality reference run | exact_storage = on or heap-band exact rescore |
| Benchmarking storage/recall tradeoffs | Compare profiles and rescore settings on labeled queries |
Benchmark reference point
The README includes a DBPedia dense benchmark, originally provided by the smart folks at qdrant, on a one-million-vector corpus. In that run:
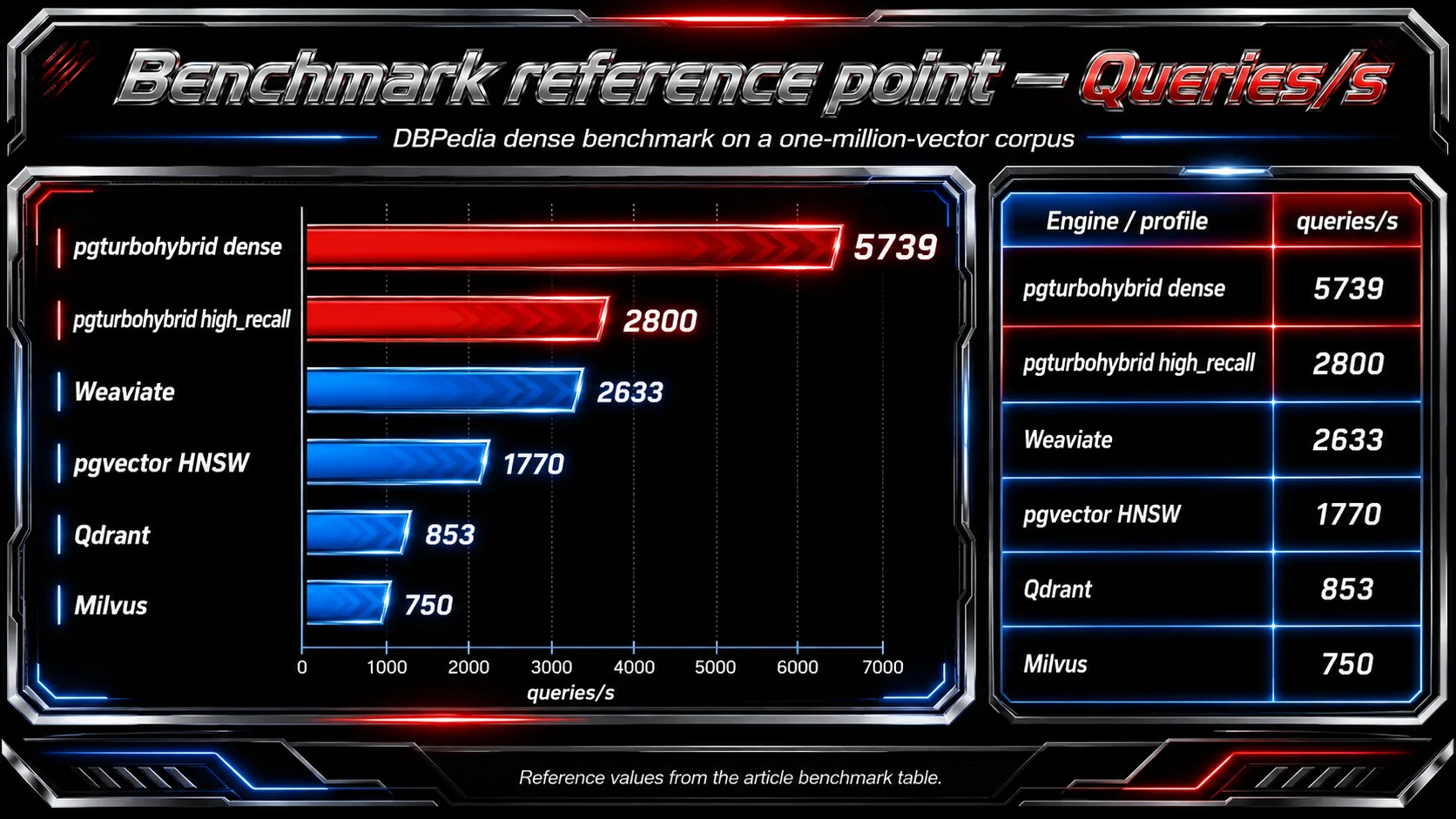
| Engine / profile | recall@10 | queries/s | mean latency |
|---|---|---|---|
pgturbohybrid dense | 0.836 | 5739 | 1.27 ms |
pgturbohybrid high_recall | 0.983 | 2800 | 2.71 ms |
| pgvector HNSW | 0.979 | 1770 | 4.37 ms |
| qdrant | 0.986 | 853 | 9.24 ms |
| milvus | 0.988 | 750 | 10.39 ms |
| weaviate | 0.977 | 2633 | 2.90 ms |
Treat these as a reference point, not a universal law. Dense retrieval performance depends on embedding model, dimensionality, corpus distribution, query distribution, hardware, index settings, and cache state. The useful takeaway is the shape of the tradeoff: compact 4-bit retrieval can be very fast, and a higher-recall profile can recover much of the quality while staying within the same PostgreSQL-native architecture.
Inspecting what happened
pgturbohybrid exposes diagnostics for the last scan:
SELECT turbohybrid_last_scan_stats(); SELECT turbohybrid_last_scan_diagnosis();
These functions are useful when tuning because they tell you whether a query was dominated by graph traversal, SIMD scoring, heap rescore, native cache setup, candidate budgets, or memory behaviour. That matters because dense retrieval tuning should not be guesswork.
A typical tuning workflow is:
-- 1. Start with the default fast path SET turbohybrid.profile = 'latency'; -- 2. Run representative queries SELECT id FROM documents ORDER BY embedding <~> turbohybrid_query(vector_query => $1) LIMIT 10; -- 3. Inspect diagnostics SELECT turbohybrid_last_scan_diagnosis(); -- 4. Try a quality-oriented profile or rescore path SET turbohybrid.profile = 'high_recall'; -- or SET turbohybrid.dense_heap_rescore = 'band';
When TurboQuant is a good fit
TurboQuant is a good fit when:
- your application is already PostgreSQL-first;
- you want dense retrieval without running a separate service on day one;
- compact index storage matters;
- latency matters, but approximate retrieval is acceptable;
- you can benchmark recall and tune profiles on your own data.
It is not a magic replacement for every vector database or every exact search workload. If your workload requires mature distributed vector search, external operational isolation, or a fully managed vector service, a dedicated engine may still be the right architecture. The interesting point is that PostgreSQL can cover more of the retrieval stack than many teams assume.
Beiträge aus dieser Reihe



Summary
TurboQuant makes dense retrieval inside PostgreSQL practical by changing the data path:
full float vectors everywhere
becomes
compact graph codes for candidate generation
plus
optional exact reranking when needed
The result is a dense index that feels like normal PostgreSQL SQL but behaves more like a purpose-built retrieval engine internally. It uses compact 4-bit codes, graph traversal, SIMD-friendly scoring, cache-aware execution, and profile-based quality controls.
Dense retrieval is only the first layer. Real search and RAG systems also need exact lexical evidence: names, IDs, rare terms, function names, product codes, and the strange strings users actually type. That is where hybrid retrieval comes in.
In the next article, we will add BM25 and reciprocal-rank fusion to the same PostgreSQL index path.
Schreibe einen Kommentar