What is Hadoop?
Apache Hadoop is a Java-Framework for large-scale distributed batch processing infrastructure which runs on standard computers. The biggest advantage is the ability to scale to hundreds or thousands of computers. Hadoop is designed to efficiently distribute and handle large amounts of work across a set of machines. When I speak of very large amounts of data, in this case I mean hundreds of Giga-, Tera- or Peta-Bytes. There is not enough space for such an amount of data on a single node. Therefore, there is a separate „Hadoop Distributed File Systems (HDFS)“ which splits data into many smaller parts and distributes each part redundantly across multiple nodes. Hadoop can handle lower amounts of data and is even able to run on a single computer, but it is not particularly efficient because of the resulting overhead. There are better alternatives like Gearman in such a case.
A Hadoop-Cluster often consists of thousands of nodes whereof errors are a daily occurrence. Therefore, it has a high degree of fault tolerance to correct failures as quickly and as automatically as possible.
Hadoop Distributed File Systems (HDFS)
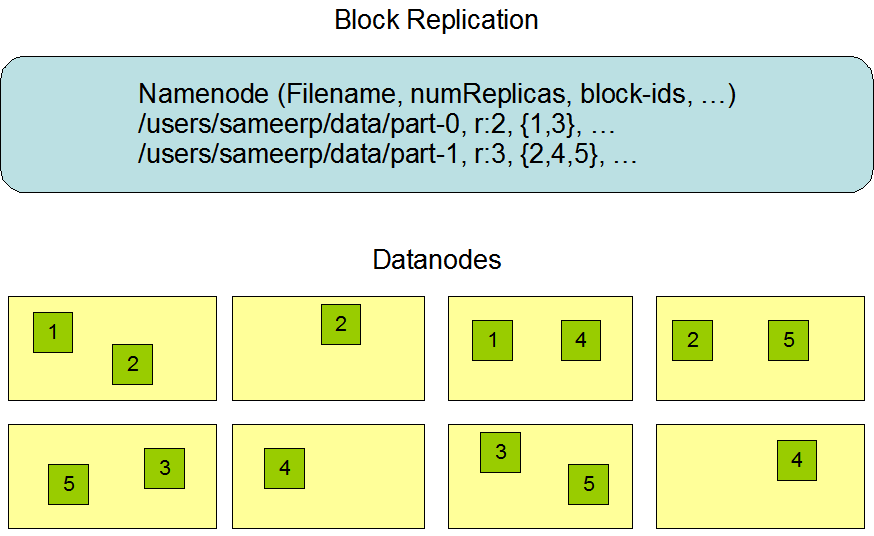
The HDFS consists of a name node and multiple data nodes. A file is not stored completely on a single node but distributed accross multiple data node and split into 64MB chunks by default. With the default replication value, each of these chunks are distributed redundantly on three nodes.
The name node stores all metadata such as file name, permissions, and on which data nodes each chunk is distributed. Because of the relatively low amount of metadata per file all of this information can be stored in the main memory of the name node, allowing fast access to the metadata. Furthermore the name node coordinates the distribution of files and monitors failures of nodes.
In the HDFS data are written once and read many times. Advantages are a simple data-coherent, very fast data throughput and an efficient and automatic distribution.
Because chunks are distributed in clusters each data node is able to – independently of other nodes – process a single chunk in parallel. The NameNode is not directly involved in this bulk data transfer, keeping its overhead to a minimum. A high performance is achieved by switching the calculation to the data. Moving data to different nodes in order to calculate these would take a long time and cost network bandwidth.
More information: http://hadoop.apache.org/common/docs/current/hdfs_design.html
MapReduce
MapReduce is a programming model / framework that allows you to quickly write an application which performs
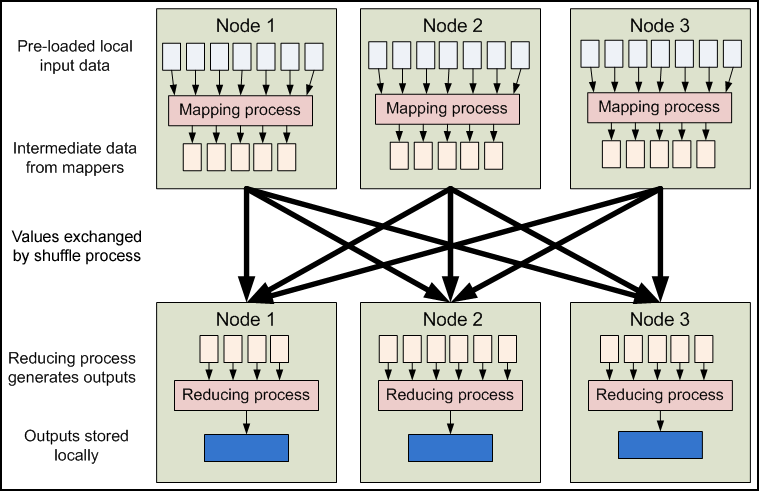
computation on these large amounts of data across nodes. You only have to write two methods named ‚map‘ and ‚reduce‘ and to define a JobConfig. Everything else is optional. The JobConfig defines – among others – input and output paths, input and output formats, the map and the reduce method.
A MapReduce job is usually monitored by one JobTracker and one TaskTracker per data node. The JobTracker pushes work out to available TaskTracker in the cluster, striving to keep the work as close to the data as possible. If, for instance, an error occurs on a data node, the JobTracker simply restarts the computation on another TaskTracker / data node that contains the same chunk. Usually, a data node performs multiple Mapper and Reducer simultaneously.
You can imagine a simple MapReduce application that counts the number of occurrences of each word in a given input set in PHP syntax as follows:
function map ($filename, $content) {
foreach (explode('', $content) as $word) {
collect($word, 1);
}
}
function reduce($word, $values) {
$numWordCount = 0;
foreach ($values as $value) {
$numWordCount += $value;
}
collect($word, $numWordCount);
}
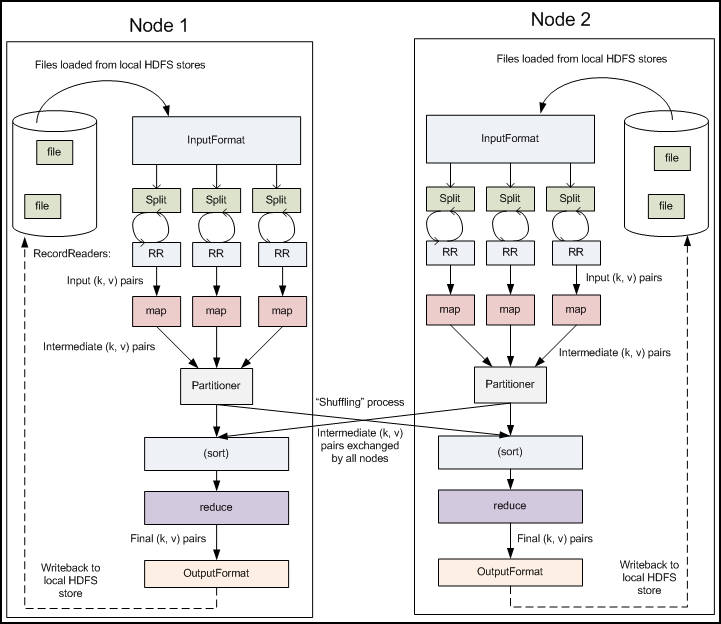
The MapReduce process roughly looks like this:
The InputFormat determines how to generate key/value pairs from the input data.
Given a key and a value, the map method processes the input data and emits zero or any amount of output key/value pairs to the Reducer. The map method runs parallel and isolated each from another on all data nodes that contain a chunk of the data file. No communication between these nodes is necessary. This leads to good performance.
To emit output data to the Reducer „output.collect(key, value)“ is used. For example:
output.collect('hallo', 1);
After the first map tasks have completed all emitted keys will be sorted on each Mapper. The intermediate results are written in a set of so-called partitions. Partitions are the inputs to the reduce tasks. The Partitioner controls that all values for the same keys are written into the same partition regardless of which Mapper is its origin. Now, the framework distributes each partition randomly to a Reducer.
Before the set of intermediate results is presented to the Reducer, Hadoop automatically sorts the received keys again because each partition contains keys from different Mappers. For each key in the partition, the Reducer’s reduce method is called once. This receives a key as well as an iterator over all the values associated with the key. Typically the reduce method reduces the set of intermediate values to a smaller set of values using „output.collect (key, value)“. The output of the reduce task is typically written to the FileSystem.
A sample implementation in Java can be found here, an explanation on the basis of concrete data on this page. The Hadoop MapReduce platform is very flexible and contains many components. I recommend this tutorial as an introduction.
Hadoop & PHP (Streaming)
Hadoop Streaming is a utility which provides a common API that allows you to use Hadoop’s MapReduce in almost any programming language, also in PHP. In doing so both the Mapper and Reducer read the input data from stdin and emit the output data to stdout.
The utility can be started, for example, as follows:
bin/hadoop jar contrib/hadoop-streaming.jar -mapper /home/user/mapper.php -reducer /home/user/reducer.php -input php5-logs/* -output php5-log
Within PHP you are able to read the input data using „fgets(STDIN)“, process the data and emit the output data using “echo”.
Interesting links are http://wiki.apache.org/hadoop/HadoopStreaming and http://hadoop.apache.org/common/docs/r0.15.2/streaming.html
There are further extensions available such as HBase which is similar to Googles Bigtable. An overview can be found at http://hadoop.apache.org. Hadoop is used – amongst others – at Facebook, Google and Twitter (http://wiki.apache.org/hadoop/PoweredBy). An alternative is, for example, DryadLINQ.

Schreibe einen Kommentar