

Ich fahre Modelle mit einem Millionen-Token-Kontextfenster, und ich compacte nie manuell. Kein /compact zwischendurch, kein bewusstes Aufräumen der Session. Das Fenster ist so groß, dass es sich anfühlt, als gäbe es keine Decke – ich kann eine Session über Stunden laufen lassen, Dateien reinziehen, Tool-Outputs sammeln, Diskussionen führen, und das Fenster füllt sich, ohne dass die Session abbricht.
Und trotzdem passiert etwas, das mich anfangs irritiert hat: Tief in einer langen Session rutscht die Qualität weg. Nicht mit einem Knall, nicht mit einer Fehlermeldung. Die Antworten werden subtil schlechter – das Modell verliert einen Faden, den ich vierhundert Zeilen weiter oben gespannt hatte, oder es widerspricht einer Festlegung, die längst getroffen war. Das Beunruhigende ist nicht der Qualitätsabfall an sich. Das Beunruhigende ist, dass das Modell mit voller Confidence weiterantwortet, als wäre nichts. Kein Zögern, kein „ich bin mir hier unsicher“, kein Hinweis darauf, dass die Last zu groß geworden ist …
Der naheliegende Reflex wäre: „Dann nimm halt ein größeres Fenster.“ Aber genau dieser Reflex geht ins Leere. Das Setup, das ich beschreibe, hat bereits das größte Fenster, das ich kaufen kann. Es gibt kein „mehr“ mehr. Die Degradation passiert nicht, weil das Fenster zu klein ist – sie passiert innerhalb eines nominal riesigen Fensters.
Das hat mich zu einer anderen Frage geführt als „wie viel Context passt rein?“. Am Ende dieses Artikels steht eine Engineering-Leitfrage, die das Pipeline-Design verschiebt … und die Antwort darauf ist nicht „mehr Fenster“. Aber bevor ich dahin komme, lohnt sich der Blick auf das, was die Forschung über dieses Phänomen weiß. Denn es ist messbar.
Mental Load ist messbar
Das Phänomen, das ich erlebe, ist kein Bauchgefühl. Es ist in mehreren unabhängigen Arbeiten dokumentiert, und es lohnt sich, drei davon nebeneinanderzulegen.
Befund 1: Die Mitte fällt durch.
Liu et al. zeigen in Lost in the Middle: How Language Models Use Long Contexts (TACL 2023), dass die Performance eines Modells stark davon abhängt, wo im Kontext die relevante Information steht. Die Kurve ist U-förmig: Information am Anfang oder am Ende des Eingabe-Kontexts wird zuverlässig genutzt, Information in der Mitte fällt ab. Wörtlich:
„performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts.“
Dieser Mitten-Effekt verschärft sich mit zunehmender Kontextlänge.
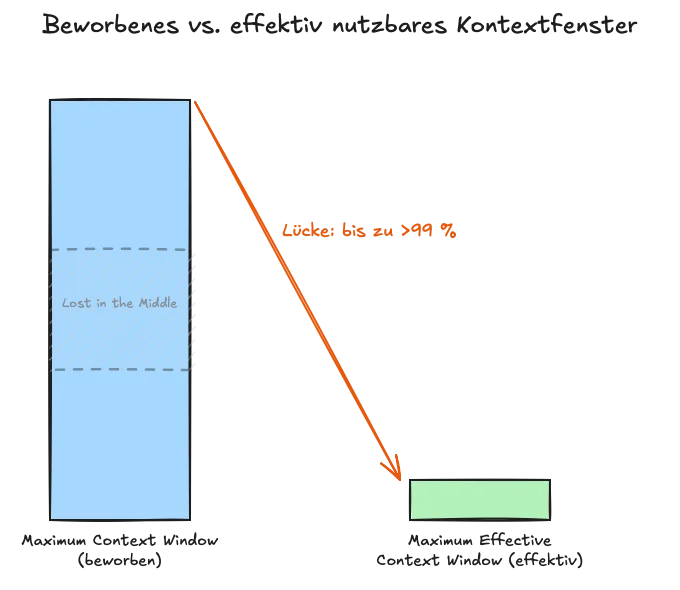
Befund 2: Das effektive Fenster ist drastisch kleiner als das beworbene.
Die Arbeit Context Is What You Need: The Maximum Effective Context Window for Real World Limits of LLMs (arXiv 2509.21361) führt eine Unterscheidung ein, die mein Setup direkt trifft: zwischen dem Maximum Context Window (MCW), also der beworbenen Zahl, und dem Maximum Effective Context Window (MECW), also dem, was das Modell tatsächlich zuverlässig verarbeitet. Die Diskrepanz ist nicht klein: „All models fell far short of their Maximum Context Window by as much as >99 %.“ Mehr als 99 Prozent. Und der Frühausfall setzt teils erschreckend früh ein:
„A few top of the line models in our test group failed with as little as 100 tokens in context; most had severe degradation in accuracy by 1000 tokens in context.“
Das ist der harte Beleg unter meiner Hook-Beobachtung: Mein 1M-Fenster ist eine Marketingzahl, kein nutzbarer Arbeitsraum.
Befund 3: Inhalt korrumpiert leise.
Die wohl unangenehmste Arbeit ist LLMs Corrupt Your Documents When You Delegate (Microsoft Research, arXiv 2604.15597), die mit dem DELEGATE-52-Benchmark über 52 professionelle Domänen und 19 Modelle hinweg misst, was in langen Delegations-Workflows mit Dokument-Inhalten passiert. Das Ergebnis: „even frontier models (Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4) corrupt an average of 25 % of document content by the end of long workflows, with other models failing more severely.“ Ein Viertel des Inhalts. Und die Mechanik ist das Tückische: „they introduce sparse but severe errors that silently corrupt documents, compounding over long interaction.“ Leise und kompoundierend. Die Fehler stapeln sich und niemand schlägt Alarm. Die Titelseite beziffert es konkret: „current frontier models degrade 25% of document content after just 20 interactions.“ Agentischer Tool-Use verbessert das nicht.
Drei Befunde, drei Methoden, ein gemeinsamer Nenner. Chroma Research hat dafür 2025 einen Begriff geprägt, der sich seither durchgesetzt hat: Context Rot. In ihrem Report Context Rot: How Increasing Input Tokens Impacts LLM Performance (Hong, Troynikov, Huber, Juli 2025) fassen sie die Kernerkenntnis so: „models do not use their context uniformly; instead, their performance grows increasingly unreliable as input length grows.“
Kontext wird nicht gleichmäßig genutzt; die Zuverlässigkeit fällt mit der Eingabelänge. Das ist die Klammer um die drei Befunde und inzwischen ein etablierter Term, den auch Anthropic in seinem Engineering-Material übernommen hat.
Das Modell merkt es nicht … und genau das ist das Problem
Ich nenne diese Last Mental Load, und ich werde gleich von Self-Care sprechen. Also lass mich das einmal sauber einordnen, bevor der Begriff trägt.
„Self-Care“ ist hier eine operationale Metapher, ein Engineering-Frame für extern eingebaute Selbst-Regulation. Es geht nicht um Care-Theorie, und es geht erst recht nicht um den Hype, Modelle würden irgendetwas „fühlen“ oder unter Last „leiden“. Ein LLM erlebt keine Mental Load. Die Metapher beschreibt ausschließlich ein Systemverhalten und die Frage, wer es reguliert.
Mit dieser Klarstellung im Rücken die eigentliche Provokation: Anders als ein Mensch besitzt ein LLM keinerlei eigeninitiierte Self-Care-Mechanismen. Ein Mensch, der über Stunden an einem überladenen Problem arbeitet, erkennt irgendwann die Überlastung, signalisiert sie („ich brauche eine Pause“, „lass uns das aufteilen“), kompensiert sie (Notizen, Struktur) oder delegiert aus eigenem Antrieb. Das Modell tut nichts davon. Es erkennt die wachsende Last nicht, es signalisiert sie nicht, es kompensiert sie nicht. Und es delegiert nicht von selbst.
Genau das schließt den Kreis zu meiner Eingangsbeobachtung. Die Confidence bleibt unverändert, während die Qualität fällt. Das Modell hat keinen internen Sensor, der „ich werde gerade unzuverlässig“ zurückmeldet. Die Forschung verschärft das noch: Die Degradation verläuft je Modellfamilie unterschiedlich. Manche Modelle (etwa die Claude-Reihe) neigen unter Unsicherheit eher dazu, eine Antwort zu verweigern, andere (etwa GPT-Modelle) zeigen mit Ablenker-Dateien höhere Halluzinations-Raten. Aber selbst das „bessere“ Verhalten ist kein eigeninitiiertes Self-Care-Signal, es ist nur ein anderes Ausfallmuster. Keines der Modelle meldet aktiv: „Ich habe gerade die Hälfte des Dokuments stillschweigend kaputtgemacht.“
Das ist der Punkt, an dem die Diagnose unbequem wird. Die messbare Last aus Kapitel zwei trifft auf ein System, das diese Last weder wahrnimmt noch von sich aus gegensteuert. Die Lücke liegt nicht in der Last selbst, denn Last ist erwartbar. Die Lücke liegt darin, dass niemand im System sie bemerkt und niemand im System sie schließt.
Externe Self-Care ist strukturelle Pflicht, keine Komfort-Funktion
Wenn das Modell die Regulation nicht selbst leistet, dann muss sie von außen kommen. Das ist kein Bonus und keine nette Optimierung für Fortgeschrittene, es ist die direkte logische Konsequenz aus der Lücke, die der vorige Abschnitt aufgemacht hat. Die Selbst-Regulation, die ein Mensch mitbringt, muss bei einem LLM extern in die Pipeline gebaut werden. Strukturell, nicht optional.
Das ist auch nicht meine private Meinung, die ich dem Feld überstülpe. Das Feld behandelt Kontext längst genau so. Anthropic formuliert in Effective context engineering for AI agents den Rahmen explizit: „Context is a critical but finite resource for AI agents.“ Kontext ist eine kritische, aber endliche Ressource; mit abnehmendem Grenznutzen, je voller das Fenster wird. Und das Ziel der Disziplin wird ebenso klar benannt: „finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome.“ Die kleinstmögliche Menge hochsignalhafter Tokens. Wenn Kontext eine endliche Ressource mit abnehmendem Grenznutzen ist, dann ist der Umgang damit eine Engineering-Aufgabe. Und die externe Self-Care ist nichts anderes als die Verwaltung dieser Ressource.
Wie sieht diese externe Self-Care konkret aus? Im Feld haben sich vier Patterns herausgebildet, die jeweils eine andere Achse der Regulation bedienen: Last reduzieren, Last verteilen, Last begrenzen und Last auslagern. Ich stelle sie als Konvergenz vor, die sich beobachten lässt. Nicht als „die einzig richtigen vier“ und nicht als vollständigen Best-Practice-Katalog. Vier Achsen, die zusammen das abdecken, was ein Mensch intuitiv täte und ein Modell eben nicht tut.
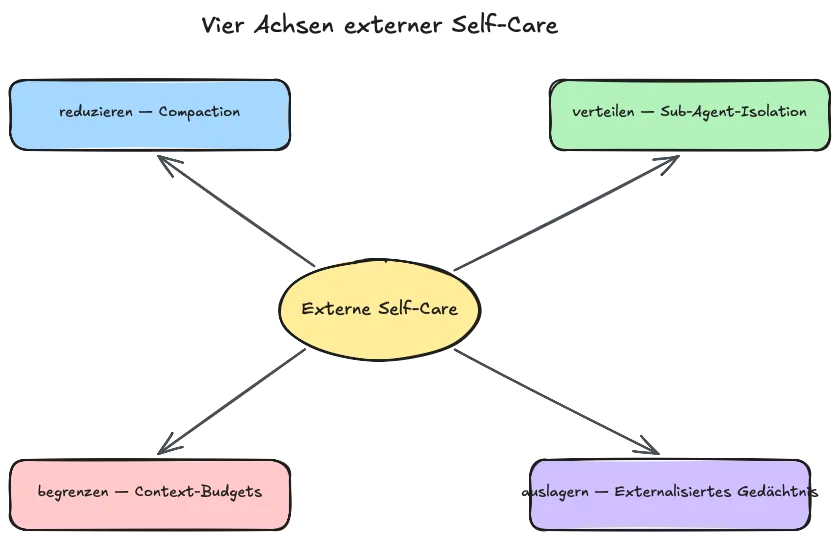
Compaction: Last aktiv reduzieren
Die erste Achse ist die direkteste: Wenn der Kontext sich füllt, reduziere die Last, indem du die Konversation zusammenfasst und Platz schaffst. Das ist Compaction.
Wie das mechanisch funktioniert, ist gut dokumentiert. In den Claude-Code-Docs heißt es zum manuellen Schritt: „/compact summarizes the conversation to free space while keeping key information.“ Die Konversation wird verdichtet, Schlüssel-Information bleibt erhalten, Ballast fällt weg. Entscheidend für mein Setup: Das passiert auch automatisch. Wenn das Fenster volläuft, beendet das die Session nicht; Claude Code fasst selbsttätig zusammen, und „the automatic pass works the same way as the /compact step in the timeline.“ Der automatische Durchlauf arbeitet also wie der manuelle Schritt, nur ohne dass ich eingreifen muss.
Genau hier muss ich ehrlich sein: Ich betreibe keine ausgefeilte eigene Compaction-Politik. Ich compacte nicht manuell und habe keine selbstgebaute Heuristik dafür, wann verdichtet wird; ich verlasse mich auf die Auto-Compaction und das große Fenster. Compaction ist insofern das Pattern, das in meinem täglichen Betrieb am ehesten für mich passiert statt durch mich. Das macht es nicht weniger relevant, im Gegenteil: Es ist die externe Self-Care, die das Tooling schon übernimmt, die erste Last-Reduktion, die greift, bevor ich überhaupt darüber nachdenke. Aber es ist auch die, bei der man am leichtesten vergisst, dass sie überhaupt stattfindet.
Sub-Agent-Isolation: Last verteilen
Die zweite Achse verteilt die Last, statt sie zu reduzieren. Die Idee: Nicht alles muss durch dasselbe Kontextfenster. Eine Teilaufgabe, die viel Verbose-Output erzeugt – eine ausufernde Recherche, ein langer Test-Lauf – würde die Haupt-Konversation fluten und genau die Mitte aufblähen, die laut Lost-in-the-Middle ohnehin durchfällt.
Sub-Agenten lösen das durch Isolation. Laut den Claude-Code-Docs gilt: „Each subagent runs in its own context window with a custom system prompt, specific tool access, and independent permissions.“ Jeder Sub-Agent hat sein eigenes Fenster. Der Verbose-Output bleibt dort, wo er entsteht: „the subagent does that work in its own context and returns only the summary.“ Nur die relevante Zusammenfassung kehrt in die Haupt-Konversation zurück. Die Last wird auf mehrere isolierte Fenster verteilt, statt sich in einem einzigen zu stapeln. Der Effekt ist genau der, den ein Team mit Delegation erzielt: Das Detail-Rauschen einer Teilaufgabe muss nicht das Hauptbewusstsein belasten, solange das Ergebnis sauber zurückkommt.
Ich selbst betreibe kein eigenes Sub-Agent-Setup, das ist nicht Teil meiner täglichen Praxis. Aber es ist das Pattern mit dem meiner Meinung nach größten Architektur-Hebel.
Context-Budgets: Last begrenzen
Die dritte Achse begrenzt die Last, bevor sie entsteht: Behandle das Token-Volumen als bewusste Engineering-Variable und nicht als etwas, das sich einfach so ergibt. Das ist die direkte praktische Konsequenz aus dem Anthropic-Prinzip der kleinstmöglichen Menge hochsignalhafter Tokens. Statt „rein damit, das Fenster ist groß“ lautet die Haltung: Jedes Token, das reingeht, sollte sich rechtfertigen.
Dass die Konfiguration des Kontexts ernst zu nehmen ist, lässt sich auch von der Modell-Seite belegen. Anthropic zeigt in Quantifying infrastructure noise in agentic coding evals, dass schon die Infrastruktur-Konfiguration Benchmarks spürbar verschieben kann: „Infrastructure configuration can swing agentic coding benchmarks by several percentage points – sometimes more than the leaderboard gap between top models.“ Das sind mehrere Prozentpunkte, teils mehr als der Abstand zwischen den Top-Modellen im Leaderboard. Wenn schon Konfigurations-Rauschen so viel bewegt, dann ist das, was man bewusst ins Fenster lädt, erst recht eine Variable, die man steuern und nicht dem Zufall überlassen sollte.
Auch hier gilt: Ich pflege keine formale eigene Token-Budget-Disziplin. Pattern 3 schreibe ich aus dem Feld, nicht aus einer persönlichen Routine. Aber es ist die Achse, die am ehesten Disziplin statt Tooling verlangt.
Externalisiertes Gedächtnis: Last auslagern
Die vierte Achse ist die, die ich tatsächlich täglich nutze und das einzige Pattern, bei dem ich aus eigener Praxis spreche. Die Idee: Was wichtig ist, muss nicht im Kontextfenster überleben. Es kann ausgelagert werden, in eine persistente Schicht außerhalb des Fensters.
In meinem Daily-Driver-Betrieb sieht das konkret so aus: Was eine einzelne Session nicht überleben muss, aber über Sessions hinweg gebraucht wird, wandert in ein persistentes Memory. Also Konventionen und getroffene Entscheidungen, Referenz-Pointer auf Tools und Datenquellen, der Stand laufender Arbeit samt offener Fragen, und destillierte Lehren aus früheren Sessions. Entscheidend ist die Disziplin dahinter: Das Memory ist keine Abladestelle, sondern kuratiert; ein Fakt pro Eintrag, gegen die Realität gegengeprüft statt blind vertraut, und vor jeder Ergänzung auf Dubletten kontrolliert. Das ist die einfachste und für mich verlässlichste Form externer Self-Care: Ich verlasse mich nicht darauf, dass das Modell die wichtige Festlegung vierhundert Zeilen später noch zuverlässig in der toten Mitte findet. Ich nehme sie aus dem Fenster heraus.
Damit löst Pattern 4 genau die Lücke, die Kapitel zwei und drei diagnostiziert haben. Wenn die Mitte durchfällt und Inhalt leise korrumpiert, dann ist das Sicherste, das Wesentliche gar nicht erst dem Fenster zu überlassen. Memory als persistente Schicht ist die Versicherung gegen Context Rot. Wie Memory-Architekturen das im Detail umsetzen, habe ich in meiner Artikelserie zu Memory-Architekturen ausführlicher beschrieben.
Die neue Leitfrage beim Pipeline-Design
Zurück zum Anfang. Ich fahre das größte Fenster, das ich bekommen kann, und compacte nie manuell … und trotzdem rutscht tief in der Session die Qualität weg, während das Modell mit voller Confidence weiterantwortet. Die vier Patterns sind die Antwort auf genau dieses Erleben. Sie bauen, von außen, die Selbst-Regulation, die das Modell im 1M-Fenster nicht von sich aus hat: Compaction reduziert die Last, Sub-Agent-Isolation verteilt sie, Context-Budgets begrenzen sie, externalisiertes Gedächtnis lagert sie aus.
Das verschiebt die Frage, die man sich beim Design einer LLM-Pipeline stellt. Die naheliegende Frage lautet „Wie viel Context passt rein?“ Und die ist, wie der Hook gezeigt hat, die falsche. Mehr Fenster löst das Problem nicht, weil das effektive Fenster ohnehin nur einen Bruchteil des beworbenen ausmacht und die Confidence nicht mit der Qualität fällt. Wer auf die Fenstergröße optimiert, optimiert auf die Zahl, die im Datenblatt steht, nicht auf die, mit der das Modell tatsächlich arbeitet. Die richtige Frage ist eine andere:
Wo ist in meiner Pipeline die externe Self-Care?
Wo wird die Last reduziert, verteilt, begrenzt, ausgelagert – und zwar von außen, weil das Modell es nicht selbst tut? Diese Frage gehört für mich in jedes Pipeline-Design, das über einen einzelnen kurzen Prompt hinausgeht. Für Practitioners ist sie ein Handwerks-Check: Welches der vier Patterns greift an welcher Stelle? Für Leads ist sie eine Architektur-Frage: Ist die Selbst-Regulation überhaupt irgendwo strukturell vorgesehen, oder verlassen wir uns implizit darauf, dass ein großes Fenster schon reichen wird?
Mental Load bei LLMs ist messbar, und das Modell merkt es nicht. Genau deshalb müssen wir es merken und in die Pipeline einbauen.
This article is also available in English on Medium.
Schreibe einen Kommentar