

Im März 2026 schrieb ich mit Claude einen Artikel. Darin stand, Browser DevTools seien „im März dazugekommen“. Stimmte nicht. Ich korrigierte: „Im Januar-Artikel schlicht vergessen – heute täglich im Einsatz.“ Nächste Runde: „dev-tools wurden nicht bewusst vergessen, sondern einfach nur schlicht vergessen.“ Runde drei: auch nicht ganz richtig. Runde vier, endlich: „Browser DevTools sind im März nicht dazu gekommen. Waren schon da, wurden im Januar nur vergessen und jetzt endlich auch erwähnt.“
Vier Korrekturen. Ein schlicht falscher Satz, der sich durch die Rekonstruktion nicht ausräumen ließ. Jede Runde erzeugte eine kohärente, plausibel klingende Variante – und jede war falsch. Das ist nicht ein Bug, den ein besseres Modell beheben würde. Das ist, wie Schema-basiertes Gedächtnis funktioniert. Genauer: so funktioniert es, wenn es persistiert wird.
Halluzination, die bleibt
Generation-Halluzination ist flüchtig. Ein LLM produziert einen falschen Satz, der Request endet, der Context Window wird verworfen, und beim nächsten Call ist der Fehler weg. Das ist unangenehm, aber es ist ein Problem, das sich mit jedem frischen Kontext selbst auflöst.
Memory-Halluzination ist anders. Ein Agent extrahiert aus einer Konversation „Fakten“, speichert sie in einem Vektor-Store oder Knowledge Graph, und beim nächsten Retrieval kommen sie wieder hoch. Nicht als unsichere Generierung, sondern als abgelegte, strukturierte Information. Ein zweiter Agent liest sie und behandelt sie wie verifizierten Systemzustand. Ein dritter baut darauf auf. Die Halluzination ist einmal durch die Reality-Check-Barriere gewandert – danach ist sie nicht mehr Halluzination, sondern Datenbankinhalt.
Dieses Problem ist kein Gradient des alten. Bartletts Schema-Theorie liefert die Mechanik: Schemas rekonstruieren, sie reproduzieren nicht. Wenn jeder Retrieval-Cycle eine neue plausible Variante erzeugt, und jede dieser Varianten als Grundlage für den nächsten Cycle dient, konvergiert das Ergebnis nicht gegen die Wahrheit. Es konvergiert gegen „kohärent und falsch“. Die DevTools-Geschichte am Anfang dieses Artikels ist ein triviales Beispiel; ich war der Reality-Check, vier Runden lang. In einem automatisierten Memory-Extraction-Pipeline gibt es diesen Reality-Check nicht.
OWASP, MINJA, MemoryGraft: das Risiko wird konkret
Das Feld hat angefangen, das als Risiko-Kategorie zu behandeln. „Memory & Context Poisoning“ (ASI06) steht seit Dezember 2025 in den OWASP Top 10 für Agentic Applications 2026 – zusammen mit Agent Goal Hijack, Tool Misuse, Identity & Privilege Abuse, Cascading Failures, Rogue Agents und weiteren vier Kategorien. Das ist keine Autor-Hypothese mehr, sondern institutionelle Anerkennung.
Die Forschung dazu ist konkret. MINJA zeigt Memory-Korruption allein durch Query-Only Interaction, ohne privilegierten Zugriff auf den Memory-Store. Das Paper berichtet eine durchschnittliche Injection Success Rate von 98,2 % und eine Attack Success Rate von 76,8 % im Eliciting von Malicious Reasoning Steps. MemoryGraft beschreibt „persistent compromise“ durch vergiftetes Experience Retrieval: Der Agent lernt aus erfolgreich abgeschlossenen Tasks, aber wenn die gespeicherten „Erfolge“ manipuliert sind, imitiert er manipulierte Patterns. Die Angriffe funktionieren, weil das Memory-System seiner eigenen Retrieval-Quelle vertraut.

Bartletts Mechanik auf Agent-Memory
Wie ich in Teil 2 der Memory-Serie gezeigt habe, ist Frederic Bartletts Schema-Theorie (1932) die Mechanik hinter LLM-Halluzination. Der Artikel dort führt das Framework ein: Gedächtnis ist rekonstruktiv, nicht reproduktiv; Schemas transformieren neue Information in Richtung kulturell Vertrautes; „effort after meaning“ zwingt zu Kohärenz, selbst wenn die Datenlage lückenhaft ist. Dieser Artikel macht einen zusätzlichen Schritt: Was passiert mit diesem Mechanismus, wenn Memory nicht mehr flüchtig ist, sondern persistiert wird?
Bartletts zentrale Beobachtung aus dem „War of the Ghosts“-Experiment lohnt ein kurzes Zurückholen. Englische Studenten sollten eine First-Nations-Folklore nacherzählen. Über wiederholte Reproduktionen zeigten sich vier systematische Verzerrungen: Leveling, Sharpening, Rationalisierung und kulturelle Assimilation. „Etwas Schwarzes kam aus seinem Mund“ wurde zu „Er schäumte vor Wut“. Die Probanden konfabulierten kohärente, aber zunehmend ungenaue Versionen und waren zunehmend sicher, sich korrekt zu erinnern. „Kohärenz steigt, Genauigkeit sinkt.“
Exakt denselben Mechanismus wendet ein LLM an, wenn es aus seinem gelernten Pattern-Raum rekonstruiert. Das DRM-Paradigma – Roediger & McDermott 1995, Journal of Experimental Psychology: Learning, Memory, and Cognition 21(4), 803–814 – macht das quantitativ: Probanden hören Wortlisten wie Bett, Ruhe, Wach, Müde, Traum, Kissen, Nacht und „erinnern“ später das Wort „Schlaf“, obwohl es nie präsentiert wurde. In Experiment 2 des Papers liegt die False-Recall-Rate bei 55 %. Das Schema erzeugt eine False Memory, die sich subjektiv nicht von echter Memory unterscheidet.
Extraction-Hallucination: wenn Speichern selbst halluziniert
Für Agent-Memory-Systeme hat das eine spezifische Konsequenz: Extraction-Hallucination. Ein Agent liest eine Konversation, extrahiert „Fakten“ und speichert sie strukturiert ab. Diese Extraktion ist selbst ein rekonstruktiver Schritt – der Agent fabriziert einen strukturierten Eintrag aus unstrukturiertem Text, und was er extrahiert, wird von seinen Schemas geprägt. Die „effort after meaning“ gilt nicht nur beim Generieren, sondern auch beim Speichern.
Bei flüchtiger Generation hilft der nächste frische Kontext. Der Fehler wird nicht zum System-Fakt, weil er im nächsten Request weg ist. Bei Memory-Persistenz wird er zum System-Fakt, weil der nächste Agent ihn als gespeicherte Information liest, nicht als möglicherweise halluzinierte Generierung. Die Halluzination wandert einmal durch die Reality-Check-Barriere, und danach behandelt das System sie wie Wahrheit.
Löschung, Berichtigung, Consent: DSGVO trifft Vektor-Store
Wenn Memory-Halluzination einmal gespeichert ist, stellt sich sofort die Frage: wie wird sie wieder entfernt? Und an diesem Punkt trifft Agent-Memory auf die DSGVO. Artikel 17 der DSGVO – das Recht auf Löschung – ist ein zentrales Nutzer-Grundrecht. Aber der Artikel sagt nicht, was „Löschen“ in einem AI-System bedeutet. Das MDPI-2025-Paper „GDPR and Large Language Models: Technical and Legal Obstacles“ macht diese Unbestimmtheit zum Kern des Konflikts: Personal Data existiert parallel in Raw-Daten, in Derived Data wie Embeddings, in Model Weights, in Fine-Tune-Adaptern. Eine DSGVO-konforme Löschung müsste alle Schichten treffen.
Bei Trainingsgewichten ist Erasure nach aktuellem Stand nahezu unmöglich ohne kostspieliges Re-Training oder experimentelle Machine-Unlearning-Methoden. Das bedeutet zweierlei:
- Der DSGVO-Konflikt ist strukturell, nicht bürokratisch.
- Die Memory-Architektur-Wahl wird zur Compliance-Entscheidung, nicht nur zur technischen.
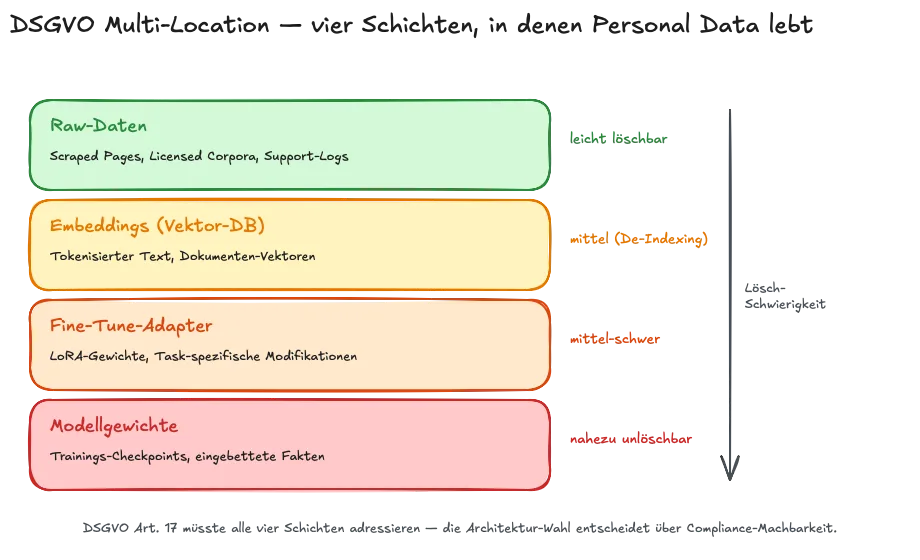
Die deutsche Datenschutzkonferenz hat diese Logik 2025 in einer Orientierungshilfe aufgenommen und RAG-Systeme explizit als datenschutzkonforme Architektur-Option positioniert. Daten, die in einer Vektor-DB liegen statt in Modellgewichten, können gelöscht, berichtigt, abgefragt werden. Die klassischen Nutzer-Rechte aus DSGVO, also Auskunft, Berichtigung, Löschung und Widerspruch, sind erfüllbar. De-Indexing und Vector-Space-Rekalibrierung sind technisch realisierbar. Das ist ein erstaunlich konstruktiver Befund aus einer Datenschutzbehörde: Ja, AI ist DSGVO-tauglich, aber nur mit der richtigen Architektur. Für die Grundlagen verweise ich auf Teil 1 der Memory-Serie.
Garante vs. OpenAI: der Präzedenzfall
Dass das kein theoretischer Konflikt ist, zeigt der Fall Garante vs. OpenAI. Am 30. März 2023 verhängte die italienische Datenschutzbehörde einen interim emergency ban gegen ChatGPT in Italien. Am 2. November 2024 folgte die finale Entscheidung, publiziert am 20. Dezember 2024: 15 Millionen Euro Strafe, plus eine sechsmonatige Public-Awareness-Campaign-Auflage in italienischen Medien. Die Vorwürfe: fehlende Transparenz über die Datenverarbeitung, fehlende Rechtsgrundlage fürs Training, Inakkuratheit der Informationen, die ChatGPT über reale Personen ausgibt, fehlende Altersverifikation.
Die konkrete AI-Act-Wirkung erlebt man aktuell bei OpenAI selbst. Das ChatGPT-Memory-Feature ist in der EU, im EWR, in UK, der Schweiz, Norwegen, Island und Liechtenstein nicht verfügbar, weil die Feature-Architektur in diesen Jurisdiktionen nicht compliance-fest ist. Das ist der härteste denkbare Beweis, dass der EU AI Act nicht Papier ist. OpenAI hat seine Memory-Funktion für einen ganzen Wirtschaftsraum ausgeschaltet, statt sie umzubauen.
Anthropics gestaffelter Weg
Anthropic macht es anders: Die Claude-Memory-Funktion wurde gestaffelt ausgerollt; zunächst für Pro-User, seit dem 2. März 2026 für alle Tiers inklusive Free-Usern auf claude.ai und in der Claude-App. Nicht auf API oder Claude Code. Consumer brauchen seit August 2025 ein Opt-in für Training-Nutzung; bei Opt-in bis zu 5 Jahre Retention für de-identified Daten. Claude for Work, Enterprise, Education und Gov sind von Training-Nutzung ausgenommen. Unterschiedliche Policy-Ebenen, unterschiedliche DSGVO-Exposition.
Konsistenz, Konflikte, temporale Wahrheit
Juristische Governance sagt, was gelöscht werden darf. Die technische Ebene stellt eine vorgelagerte Frage: welcher Memory-Eintrag ist überhaupt noch gültig? Denn selbst wenn die juristische Frage geklärt ist, bleibt die technische Frage der Konsistenz. Bei jedem längerlaufenden Memory-Betrieb sind widersprüchliche Memories der Normalfall, nicht die Ausnahme. Fakten ändern sich: Anna arbeitet jetzt bei Firma X, vor drei Monaten bei Y. Zwei Agent-Instanzen, die parallel laufen, können dieselbe Quelle unterschiedlich interpretieren und widersprüchliche Memories erzeugen. Welche gilt?
Zeps Antwort darauf ist ein bi-temporales Modell (arXiv:2501.13956, Rasmussen et al., 20. Januar 2025). Das Memory-System führt zwei parallele Zeitachsen: eine für die reale Welt – wann war eine Information wahr – und eine für die Transaktionen des Systems – wann hat Zep diese Information aufgenommen. Updates überschreiben nicht, sie erzeugen neue Kanten im Knowledge Graph. Das macht das System non-lossy: Die alte Information bleibt, sie ist nur als „nicht mehr gültig ab Zeitpunkt X“ markiert. Für Audit-Trails ist das Gold wert, weil die Historie nachvollziehbar bleibt.
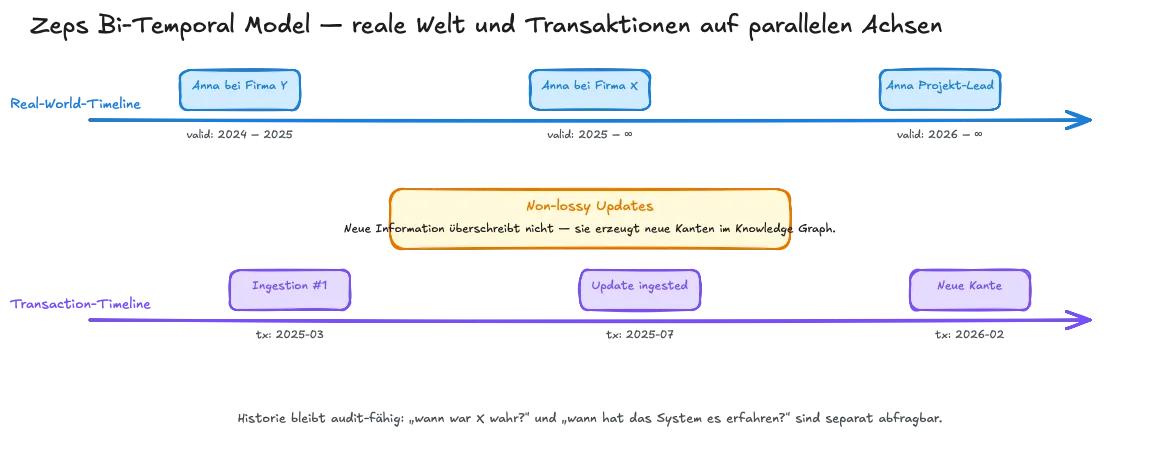
Die Zahlen, die Zep dabei erreicht, sind beachtlich. Im DMR-Benchmark liegt Zep bei 94,8 % gegenüber MemGPTs 93,4 %. Im LongMemEval-Benchmark bis zu 18,5 % Accuracy-Improvement bei 90 % Latenz-Reduktion. Teil 3 der Memory-Serie geht auf die Benchmark-Seite im Detail ein.
Parallel dazu gibt es Defense-Forschung, die Konsistenz architektonisch absichert. Trust-Aware Retrieval mit temporal decay und pattern-based filtering ist ein Ansatz: Memories altern in ihrer Gewichtung, bekannte Injection-Signaturen werden gefiltert. A-MemGuard ergänzt das um Consensus-based Validation über mehrere Retrieval-Pfade.
Ein einzelner Agent mit konsistentem Memory ist schwierig genug. Sobald mehrere Agenten mit geteiltem oder konkurrierendem Memory arbeiten, wird die Komplexität exponentiell. Teil 4 der Memory-Serie hat Generative Agents als Einzelstudie behandelt: 25 Agenten, die in einer Simulation emergentes Sozialverhalten zeigen. Die Frage nach Multi-Agent-Governance und Konsensbildung ist komplex genug für einen eigenen Artikel. Und keine Sorge, der wird folgen.
Kosten. Oder: die ökonomische Governance-Dimension
Juristische und technische Governance haben einen gemeinsamen Hebel: beide verteuern Memory-Operationen. Compliance-Audit-Trails, Bi-Temporal-Models, Trust-Aware Retrieval – jedes dieser Instrumente hat Inferenz-Overhead. Und jede Anfrage an einen Agent kann ohnehin mehrere Memory-Lookups triggern. In einem System mit zehntausend Usern und hundert Anfragen pro Tag wird das so messbar, dass die Produktkalkulation davon abhängt.
Mem0 ist das Gegenbeispiel, das zeigt, dass intelligente Memory-Architektur Kosten senken kann statt sie zu erhöhen. Das Paper „Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory“ (Chhikara et al., 28. April 2025) berichtet zwei Kernzahlen. Erstens: 26 % relative Improvement im LLM-as-a-Judge-Metric gegenüber OpenAIs eigenem Memory. Zweitens, und für die Kosten-Diskussion entscheidender: mehr als 90 % Token-Kosten-Reduktion. Das ist keine Einsparung um 10 %, das ist eine Größenordnung.
MarketsandMarkets prognostiziert für den globalen AI-Agents-Markt ein Wachstum von 7,84 Milliarden US-Dollar (2025) auf 52,62 Milliarden US-Dollar (2030), mit einer CAGR von 46,3 % – andere Analysten-Häuser liegen im ähnlichen Korridor. VentureBeat formulierte Anfang 2026:
„In 2026, contextual memory will no longer be a novel technique; it will become table stakes for many operational agentic AI deployments.“
Memory ist kein Differenzierungs-Feature mehr, sondern Grundvoraussetzung. Und damit verschiebt sich die Kosten-Frage.
Wer definiert, wie viele Memory-Lookups ein Agent pro Request machen darf? Welche Memory-Reichhaltigkeit rechtfertigt welche zusätzliche Latenz? Welche User-Gruppen bekommen voll ausgestatteten Memory-Zugang, welche nur reduzierten? Das sind keine technischen Fragen, das sind Policy-Fragen auf System-Ebene. Kosten-Effizienz ist Governance. Und damit ein Stück Meta-Entscheidung, das gleichzeitig die Frage aufwirft, wer überhaupt über Agent-Memory entscheiden soll.
Vier offene Fragen und wer das Gedächtnis kontrolliert
Juristik, Technik, Ökonomie – drei Governance-Dimensionen, jede mit eigenen Antworten. Darüber liegen aber vier Forschungsfragen, auf die derzeit niemand belastbar antworten kann, und deren Antwort die Architektur-Entscheidungen der nächsten Jahre prägen wird.
- Nach 90 Jahren Kognitionsforschung ist Bartletts Analyse bestätigt: Halluzination ist keine externe Störung, sondern Konsequenz des generativen Mechanismus. Die Frage, ob Halluzination je eliminierbar ist, hat eine Antwort, die im Artikel-Ton zurückhaltend bleiben muss: wahrscheinlich nicht vollständig. Das Paradox dabei ist, dass genau die Fähigkeit, die Halluzination ermöglicht – plausible Rekonstruktion aus gelernten Patterns – dieselbe Fähigkeit ist, mit der Modelle generalisieren. Ein nicht-halluzinierendes Modell wäre keine Sprachmaschine mehr, es wäre eine Suchmaschine. Die realistische Strategie kann also Rate-Reduktion sein, nicht Elimination.
- Die zweite Frage ist philosophischer. Tulvings Konzept des autonoetischen Bewusstseins, also die Fähigkeit, sich selbst als Erlebenden der eigenen Erinnerung zu erfahren, ist bei LLMs nicht gegeben. Reicht funktionales Gedächtnis für das, was wir „Erinnern“ nennen würden, oder fehlt etwas Fundamentales? Ich habe in Teil 2 der Memory-Serie Tulvings Framework eingeführt, dort ist mehr Tiefe.
- Dritte Frage: Emergiert Metacognition aus Memory? Wenn ein Agent über seine eigenen Erinnerungen reflektieren kann – welche sind verlässlich, welche nicht – wäre das ein Meta-Level, das aktuellen Systemen fehlt. A-MemGuards Dual-Memory-Structure (ein Lessons-Store separat vom Experience-Store) ist eine mögliche Richtung.
- Die vierte Frage ist die, die uns in der Praxis am meisten beschäftigt: Wer kontrolliert das Agent-Gedächtnis? User, Developer oder Modell? Und die Antwort hängt vom Anwendungs-Kontext ab. Bei Coding-Assistenten wie Claude Code: volle Kontrolle beim Benutzer. Der Developer will sehen, was gespeichert wird, will löschen können, will entscheiden, was weiterhin gilt. Ein Tool, das den Code schreibt, darf keine Memory-Autonomie gegen den Entwickler haben.
Bei Endnutzer-Anwendungen liegt die Sache anders. Dort brauchen Entwickler architektonische Souveränität, sonst ist Produkt-Design unmöglich. Und das Modell braucht Self-Managed-Memory-Fähigkeiten, damit die Anwendung nicht bei jedem Edge-Case am User hängt. Der User bekommt Policy-Ebenen und Transparenz, keine Architektur-Hebel. Ein Mix aus Pro-Developer und Pro-Modell. Keine Universal-Antwort, sondern Domänen-Differenzierung. Wer die Kontroll-Frage universell beantwortet, beschneidet entweder die Produkt-Räume oder die User-Rechte.
Governance-Infrastruktur formiert sich
Was an diesem Punkt des Artikels düster klingen könnte, ist es bei näherem Hinsehen nicht. Die Governance-Infrastruktur für Agent-Memory formiert sich gerade; und zwar schneller, als die meisten Außenstehenden bemerken.
Der erste Schritt ist Taxonomie. Die OWASP Top 10 für Agentic Applications 2026 (veröffentlicht 9. Dezember 2025 vom OWASP Gen AI Security Project) sind der erste formale Risiko-Katalog für autonome AI-Agents. Zehn Kategorien ASI01 bis ASI10: Agent Goal Hijack, Tool Misuse & Exploitation, Identity & Privilege Abuse, Agentic Supply Chain Vulnerabilities, Unexpected Code Execution, Memory & Context Poisoning, Insecure Inter-Agent Communication, Cascading Failures, Human-Agent Trust Exploitation und Rogue Agents. Ohne Taxonomie kein Testing-Standard, ohne Testing-Standard kein Benchmark, ohne Benchmark kein Marktdruck zur Besserung. Taxonomie ist die Voraussetzung für Messbarkeit.
Der zweite Schritt ist Open-Source-Tooling. Microsoft hat am 2. April 2026 das Agent Governance Toolkit veröffentlicht; nach eigenen Angaben das erste Toolkit, das alle zehn OWASP-Agentic-Risks mit deterministic, sub-millisecond Policy Enforcement adressiert. Der Cross-Model Verification Kernel (CMVK) ist einer der Kernmechanismen – Majority Voting über mehrere Modelle als Schutz gegen Memory-Poisoning. Statt einem Modell zu vertrauen, lässt man mehrere unabhängig prüfen und übernimmt nur Konsens.
A-MemGuard und Audit-Infrastruktur
A-MemGuard ist der zentrale Baustein aus der Defense-Forschung. Consensus-based Validation kombiniert mit einer Dual-Memory-Structure: Wenn ein Memory-Retrieval zu einem fehlschlagenden Agent-Task führt, wird die Lektion daraus in einen separaten „Lessons“-Store geschrieben und beim nächsten Retrieval konsultiert. Das durchbricht Fehler-Zyklen, die sonst durch persistiertes halluziniertes Memory verstärkt würden. Das Paper berichtet über 95 % Reduktion der Attack Success Rate bei minimalen Utility-Kosten.
Die nächste Ebene ist Audit- und Revocation-Infrastruktur. Statt API-Keys pro Agent zu verwalten, zeichnen Graph-basierte Delegations-Pfade nach, über welche Autoritätskette ein Agent gerade handelt – und machen diese Kette präzise widerrufbar, ohne laufende Aktivitäten anderer Agenten zu stören. In Kombination mit Zeps bi-temporalem Modell entsteht eine Audit-Fähigkeit, die sich mit klassischer Datenbank-Auditierung messen lässt.
Der Status quo … und die Schluss-Strategie
Wie groß der Weg noch ist, zeigen zwei Befunde aus 2026. Eine Kiteworks-Analyse berichtet, dass 33 % der Organisationen keine Evidence-Quality-Audit-Trails für ihre AI-Systeme haben, und dass Organisationen ohne solche Trails 20 bis 32 Punkte hinter AI-Maturity-Metriken zurückliegen. Eine parallele Red-Team-Studie (Agents of Chaos, Februar 2026, 20 Forscher aus Harvard, MIT, Stanford, CMU) zeigt: 60 % der getesteten Organisationen können einen fehlverhaltenden Agenten nicht terminieren, 63 % können Purpose-Limits nicht durchsetzen. Das ist der Status quo, nicht das Ziel. Aber der Status quo wird jetzt gemessen, und Messbarkeit ist die Voraussetzung für Verbesserung.
Die Schluss-Strategie daraus ist nicht Elimination. Sie ist Rate-Reduktion über vier Säulen: Grounding-Mechanismen senken die Häufigkeit (RAG, Tool Use), Confidence Scoring und Quellenangaben erhöhen die Erkennbarkeit, Maker-Checker-Patterns und Human-in-the-Loop minimieren die Auswirkung, transparente Kommunikation kalibriert die Nutzer-Erwartung. Keine Silver Bullet, aber ein realistischer, mehrschichtiger Ansatz.
Die DevTools-Korrekturen vom Artikel-Anfang brauchten vier Runden, aber sie fanden statt. Ich war der Reality-Check. Die Governance-Infrastruktur, um die es diesem Artikel geht, ist der Versuch, Reality-Checks einzubauen, wenn niemand mehr vier Runden mitliest. Das ist der Unterschied zwischen einem Tool und einem System. Und er entscheidet darüber, ob Agent-Memory ein Risiko bleibt oder eine verantwortbare Infrastruktur wird.
This article is also available in English on Medium.
Schreibe einen Kommentar