

Im Mem0-Paper vom April 2025 steht eine Zeile, die mich lange beschäftigt hat. Auf dem LoCoMo-Benchmark erreicht der simpelste Baseline – einfach das komplette Conversation-Protokoll in den Prompt kippen – 72.90 % Accuracy. Alle Memory-Systeme, die in den letzten zwei Jahren gebaut wurden, lagen darunter. Mem0 bei 66.88 %, OpenAI-Memory bei 52.90 %. Der einzige Trick: Full-Context-Prompts brauchen 17 Sekunden und kosten 26.000 Tokens.
Dann, Anfang 2026, kam Letta mit einem Filesystem-Ansatz – grep, search_files, open – und landete bei 74.0 %. Erstmals war ein Memory-System nicht nur schneller, sondern auch besser als das stumpfe Alles-Hineinkippen. Drei Monate später erscheint ein Paper von ByteDance, das die Frage anders stellt: Was, wenn das Modell seine Gewichte während der Antwort anpasst?
In den ersten beiden Teilen dieser Serie habe ich die Memory-Landschaft und die kognitionspsychologische Tiefe hinter KI-Memory beschrieben. Dieser dritte Teil zeigt, womit wir Memory messen – und warum die nächste Idee nicht „noch ein Memory-Store“ ist, sondern das Modell selbst.
Teil 1: Die Benchmark-Lage
Vier Messlatten
Memory-Architekturen lassen sich seit 2024 endlich vergleichen. Vier Benchmarks tragen den Großteil der empirischen Diskussion:
| Benchmark | Fokus | Publikation | Skala |
|---|---|---|---|
| LoCoMo | Long-term conversational memory | Maharana et al., Feb 2024 | ~300 Turns, ~9K Tokens, bis zu 35 Sessions |
| DMR (Deep Memory Retrieval) | Single-turn Fact-Retrieval | MemGPT-Team 2023, Primary Metric des MemGPT-Papers | 60 Messages pro Conversation |
| LongMemEval | 5 Memory-Fähigkeiten: Info-Extraction, Multi-Session Reasoning, Temporal Reasoning, Knowledge Updates, Abstention | Wu et al., ICLR 2025 | Lange interaktive Chat-Sessions |
| RULER | Context-Length-Stresstest | NVIDIA, RULER Repository | 13 Task-Konfigurationen, 4K bis 128K Tokens |
Letta bringt es in ihrem Benchmarking-Blog prägnant auf den Punkt:
„Memory is more about how agents manage context than the exact retrieval mechanism used.“
Letta (2025)
Die interessante Frage ist damit nicht „welche DB?“, sondern „wie misst der Agent unter Last?“. Und hier erzählen die Zahlen drei Geschichten, die erst zusammen ein Bild ergeben.
Story A – Full-Context als Obergrenze, Mem0 als Kosten-Tradeoff
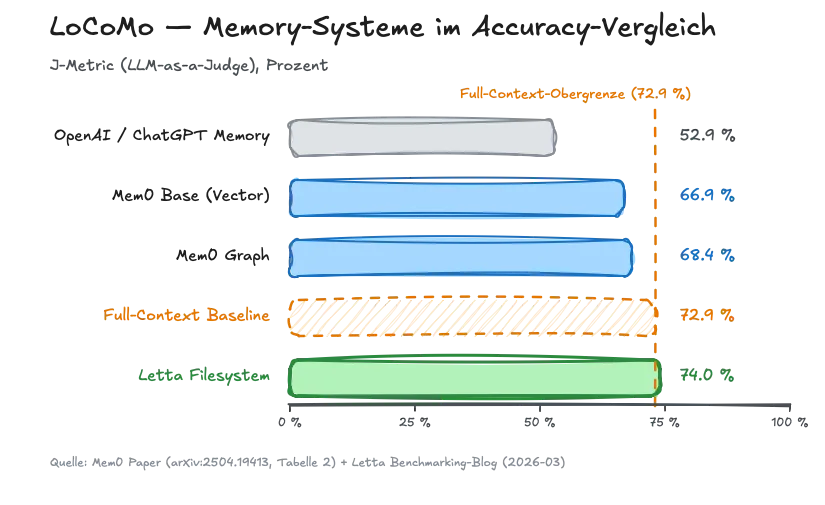
Das Mem0-Paper vergleicht Memory-Systeme systematisch auf LoCoMo. Die Tabelle 2 ist nüchtern und aufschlussreich:
| System | LoCoMo J-Metric | Retrieval-Tokens / Query | p95-Latenz |
|---|---|---|---|
| OpenAI / ChatGPT Memory | 52.90% ± 0.14 | — | — |
| Mem0 Base (Vector) | 66.88% ± 0.15 | ~1.764 | 1.440 s |
| Mem0 Graph | 68.44% ± 0.17 | ~3.5K | 2.590 s |
| Full-Context Baseline | 72.90% ± 0.19 | ~26.000 | 17.117 s |
| Zep / Graphiti | — | >600.000 (Speicher) | — |
Die Logik ist simpel: Full-Context ist die Obergrenze. Alles in den Prompt, das Modell liest selbst. Das kostet 17 Sekunden und 26K Tokens. Mem0 opfert 6 Punkte Accuracy (66.88 vs. 72.90), gewinnt dafür 91 % Latenz-Reduktion und 93 % weniger Tokens pro Query. Zep greift das andere Extrem an – maximale Fakten-Tiefe über einen temporalen Knowledge Graph – und verbraucht dafür 600.000+ Tokens im Speicher-Footprint.
Story B – Einfach schlägt komplex
Im März 2026 stellt Letta in einem Benchmarking-Paper ihren Filesystem-Ansatz gegen die etablierte Memory-Szene. Die Agenten bekommen nichts Spezielles, nur grep, search_files, open, close und ein answer_question-Tool. Das Modell: gpt-4o-mini, also bewusst nicht das teuerste. Das Ergebnis:
- Letta Filesystem: 74.0 % auf LoCoMo
- Mem0 Graph: 68.5 %
- OpenAI Memory: 52.9 %
Hier kippt die Statistik: Letta Filesystem schlägt sogar die Full-Context-Baseline. Zum ersten Mal ist ein Memory-System nicht nur billiger und schneller als „alles in den Prompt“, sondern auch genauer. Die Letta-Autoren erklären das plausibel: CLI-Tools wie grep sind massiv in den Trainingsdaten vertreten, das Modell weiß intuitiv, wann es sie wie einsetzt. Spezialisierte Memory-Operations hingegen sind seltene Konstrukte, die das Modell erst lernen muss.
Die Moral finde ich unbequem: nicht die DB entscheidet, sondern das Agent-Design.
Story C – DMR ist durch, LongMemEval ist jetzt
Während LoCoMo der Vergleichsstandard wurde, hat die alte MemGPT-Messlatte DMR ihren Zenit überschritten. Zep/Graphiti liefert gegen gpt-4-turbo 94.8 %, gegen gpt-4o-mini sogar 98.2 %. Die Zep-Autoren schreiben offen, dass DMR zu einfach geworden ist: Single-turn, 60 Messages pro Conversation — passt in jedes moderne Context Window. Sie etablieren LongMemEval als Ersatz.
Die neue Latte schmerzt. GPT-4o erreicht im offline-Setup (nur die Session, die die Antwort enthält) rund 92 %. Im online-Setup (das echte Long-Term-Memory-Szenario mit vielen Sessions dazwischen) fällt dieselbe Baseline auf ~58 %. 30 bis 60 Prozentpunkte Abstand – das ist der wahre Memory-Schmerz, und er tritt erst bei LongMemEval sichtbar hervor.
Zep hilft dem Modell auf LongMemEval um 18.5 Prozentpunkte auf, bei 90 % weniger Latenz. Strukturiertes Reading mit Chain-of-Note bringt nochmal 10 Punkte. Aber das Grundproblem bleibt: Long-Context-Modelle sind schlechter im Erinnern als ihre Context-Window-Werbung behauptet.
Die RULER-Pointe
Genau das zeigt RULER noch schärfer. NVIDIAs 13-Task-Benchmark stresst moderne LLMs bei 4K, 8K, 16K, 32K, 64K, 128K Tokens. Die Definition „effective length“ bindet an einen Performance-Threshold von 85.6% (Llama-2-7B bei 4K). Das Ergebnis für Modelle mit 128K-Claim:
- Jamba-1.5-large: >128K effective, 96.0 % avg
- Gemini-1.5-Pro: >128K effective, 95.8 % avg
- GPT-4-1106-preview: nur 64K effective trotz 128K claimed, 91.6 % avg
Moderne LLMs haben auf einfachen Needle-in-a-Haystack-Tests nahezu 100 %; sobald die Tasks reicher werden, bröckelt die Performance vor dem beworbenen Limit. Context-Fenster sind gewachsen, Memory-Kapazität nicht.
Die Wand
Die drei Stories zeigen eine Wand. Die bisherigen Fortschritte kamen aus besserem Management um das Modell herum – bessere Stores, schlauere Retrieval-Strategien, schlankere Prompts. Letta Filesystem ist der Endpunkt dieser Linie: simplere Tools, bessere Nutzung. Die nächsten Prozentpunkte auf LongMemEval und RULER werden schwerer. Die Gewichte bleiben eingefroren, während die Kontexte länger werden. Hier setzt die nächste Idee an.
Kurze Unterbrechung – es geht gleich weiter im Artikel!
Du suchst den Austausch?
Wenn Du den Austausch suchst oder jemanden benötigst, der dieses Thema bei Dir implementieren kann, bist du bei uns richtig. Schreibe uns eine kurze Nachricht und wir machen finden einen kurzen, unverbindlichen Termin, in dem wir uns Deine Herausforderung gemeinsam ansehen.
Deal?
Dieses Formular wird über HubSpot eingebunden und benötigt Marketing-Cookies, die du gerade nicht akzeptiert hast.
Lieber direkt: kontakt@mayflower.de
Teil 2: Eine neue Antwort: In-Place Test-Time Training
Was ByteDance vorschlägt
Am 7. April 2026 veröffentlichen Guhao Feng und sechs Co-Autoren von ByteDance-Seed das Paper „In-Place Test-Time Training“ (arXiv:2604.06169). Es wird als ICLR 2026 Oral angenommen — was in der Szene die oberste Qualitätsstufe ist, reserviert für Arbeiten mit substanzieller neuer Einsicht. Der Code liegt unter Apache 2.0 auf GitHub.
Das Abstract argumentiert direkt gegen das statische Deploy-Paradigma: LLMs im Einsatz bekommen keine Chance, sich an kontinuierliche Datenströme anzupassen. Test-Time Training (TTT) wurde als Antwort vorgeschlagen, scheiterte aber bisher an drei Barrieren — Architektur-Inkompatibilität, Compute-Ineffizienz und falsch ausgerichteten Objectives. In-Place TTT adressiert alle drei.
Fast Weights in den MLPs
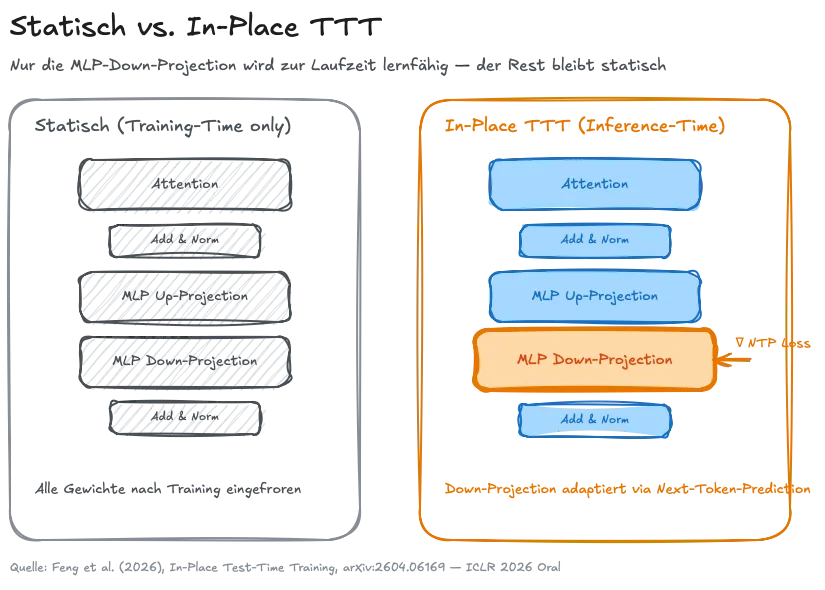
Der architektonische Trick ist bemerkenswert zurückhaltend: Keine neuen Module, keine Sidecars, keine parallelen Pfade. Stattdessen wird die Final Projection Matrix jedes MLP-Blocks als adaptierbare fast weight behandelt:
„the final projection matrix of the ubiquitous MLP blocks as its adaptable fast weights“
Feng et al. (2026)
Diese Matrix darf sich während der Inferenz ändern, alle anderen Gewichte bleiben statisch. Das Modell ist im Kern eingefroren, an einer klar definierten Stelle aber lernfähig. „Drop-in“, kompatibel mit jedem bestehenden Transformer.
Der zweite theoretische Fortschritt ist das Training-Objective. Bisherige TTT-Ansätze benutzten generische Rekonstruktions-Objectives – was rekonstruiert wird und was das Modell später eigentlich tun soll, driftete auseinander. In-Place TTT koppelt das Update explizit an Next-Token-Prediction:
„a tailored, theoretically-grounded objective explicitly aligned with the Next-Token-Prediction task“
Feng et al. (2026)
Das klingt nach Detail, ist aber der Grund, warum dieser Ansatz auf Sprachaufgaben funktioniert, während frühere TTT-Varianten stagnierten.
Der dritte Baustein: Chunk-weise Updates, kompatibel mit Context Parallelism. Statt nach jedem Token die Gewichte anzufassen, fasst das System Chunks zu stabilen Updates zusammen, skalierbar und numerisch robust.
Was RULER zeigt
Die Evaluation läuft dort, wo Teil I die Wand verortete: RULER. Das 4B-Parameter-Modell wird bei Kontexten bis 128K Tokens auf allen 13 Task-Konfigurationen getestet, über OpenCompass bis hinauf zu 256K. Das Paper berichtet „consistently outperforms competitive TTT-related approaches“ bei Pretraining-from-Scratch. Die empfohlene Konfiguration setzt TTT auf jeder sechsten Layer ein (Indices 0, 6, 12, 18, 24, 30, 36), bei Learning Rate 3, Chunk Size 4096, Sequence Length 65536.
Das schließt den Bogen zu Teil I. Genau die RULER-Lücke, an der GPT-4 mit seinen 64K effective length scheitert, ist das Ziel.
Produktionsnäher als man denkt
Der Code-Stack liest sich wie ein aktuelles ML-Infrastruktur-Handbuch: PyTorch 2.8, FlashAttention 2.8.3, VeOmni, FSDP2. Empfohlene Target-Modelle sind Qwen3-8B und LLaMA-3.1-8B – Open-Weight-Klassiker. Das ist aus meiner Sicht kein Spielzeug, sondern ein Forschungsartefakt mit Production-Pfad. Wir können das heute reproduzieren.
Was das mit Memory zu tun hat
Im ersten Teil dieser Serie habe ich das CoALA-Framework vorgestellt: fünf Gedächtnistypen, darunter „parametrisches“ und „episodisches“ Gedächtnis als getrennte Kategorien. Parametrisch war dort synonym mit eingefroren – das Wissen, das beim Training in die Gewichte ging. Episodisch war das, was in der aktuellen Session passiert.
In-Place TTT verwischt diese Trennung. Episoden aus dem laufenden Kontext sickern in die Gewichte; kontrolliert, lokal begrenzt auf eine Projection-Matrix pro Layer, aber real. Die saubere Taxonomie, die Tulving und CoALA aufgeschrieben haben, bekommt einen Riss.
Teil 3: Was das bedeutet
Die neue Bruchlinie
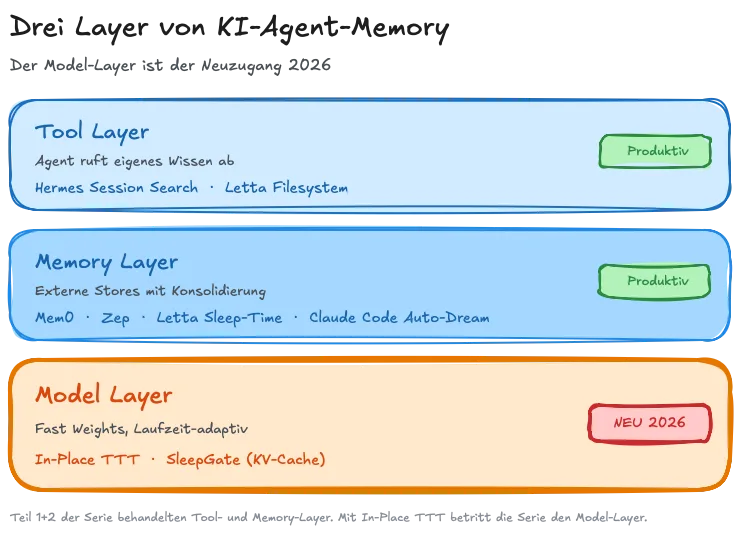
Memory lässt sich seit Teil 1+2 auf drei Ebenen einordnen – TTT füllt die Lücke, die bis vor einem Jahr offen stand:
| Layer | Paradigma | Beispiele | Stand |
|---|---|---|---|
| Model-Layer | Fast Weights, Laufzeit-adaptiv | In-Place TTT, SleepGate (KV-Cache) | Forschung, ICLR 2026 |
| Memory-Layer | Externe Stores mit Konsolidierung | Mem0, Zep, Letta Sleep-Time, Claude Code Auto-Dream | Produktiv |
| Tool-Layer | Agent ruft eigenes Wissen ab | Hermes Session Search, Letta Filesystem | Produktiv |
Teil 2 beschrieb Memory-Layer (Dreaming, Konsolidierung) und Tool-Layer (Self-Search). Teil 3 ist der erste Artikel, der den Model-Layer betritt.
Drei offene Fragen
Right to be Forgotten bei Fast Weights. Wenn Memory in die Gewichte einsickert, wie garantiert man Löschung? Machine Unlearning ist ein aktives Forschungsfeld, aber die existierenden Techniken sind teuer und liefern keine harten Garantien. Bei externen Stores ist Löschen ein DELETE-Statement, bei einer modifizierten Projection-Matrix wird es ein Retraining oder ein Revert auf den letzten sauberen Checkpoint.
Auditing. Letta Context Repositories (siehe Teil 2) versionieren MEMORY.md wie Source Code – Git-History, Branches, Merge-Konflikte. Für Fast-Weight-Deltas gibt es dieses Werkzeug nicht. Wie diffed man eine Projection-Matrix? Welche Änderung löste welche User-Interaktion aus? Observability-Standards dafür müssen erst entstehen.
Koexistenz oder Konvergenz. Wird Model-Layer-Memory die Memory-Layer-Stores ersetzen … oder ergänzen sie sich? Die Ökonomie spricht vorerst für Koexistenz. TTT bleibt absehbar teurer als Embedding-Lookups, weil es Gradient-Updates zur Inference-Zeit braucht. Für den Hot Path einer Conversation kann das lohnen, für Cold Storage über Wochen eher nicht. Aber langfristig ist das offen.
Fazit
Der Bogen der Serie ist gespannt. Teil 1 zeigte die Memory-Architektur-Landschaft, Teil 2 die kognitionspsychologische Tiefe und den Stand bei Konsolidierung und Retrieval. Teil 3 zeigt, wo die nächste Bewegung herkommt — nicht aus noch einem Memory-Store, sondern aus dem Modell selbst.
Drei Fragen zum Mitnehmen:
- Welcher der vier Benchmarks ist für dein Produkt tatsächlich relevant? LoCoMo ist der gemeinsame Nenner, aber LongMemEval misst, was eure User wirklich erleben.
- Wenn LongMemEval ehrlich ist, warum setzen die meisten Memory-Stacks weiterhin auf DMR-taugliche Single-Fact-Retrieval-Patterns?
- Was würde es für eure Governance-Prozesse bedeuten, wenn das Modell während der User-Interaktion lernt und vergisst?
Die Antworten werden meiner Erfahrung nach nicht mehr lange Forschungsthema bleiben. Ein ICLR-Oral-Paper mit Apache-2.0-Code auf Qwen und LLaMA ist in dieser Branche keine Vorschau mehr.
Es ist der Startschuss.
Weiterführende Quellen
Lust auf mehr Lektüre?
Auf der Rückseite dieser Karte findest du ganz viel Literatur zum nachlesen.
→ Links & Literatur
- Feng, G. et al. (2026). „In-Place Test-Time Training.“ arXiv:2604.06169 — ICLR 2026 Oral. Code: github.com/ByteDance-Seed/In-Place-TTT
- Maharana, A. et al. (2024). „Evaluating Very Long-Term Conversational Memory of LLM Agents“ (LoCoMo). arXiv:2402.17753
- Wu, D. et al. (2024). „LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory.“ arXiv:2410.10813 — ICLR 2025
- Rasmussen, P. et al. (2025). „Zep: A Temporal Knowledge Graph Architecture for Agent Memory.“ arXiv:2501.13956
- Chhikara, P. et al. (2025). „Building Production-Ready AI Agents with Scalable Long-Term Memory“ (Mem0). arXiv:2504.19413
- Lin, K. et al. (2025). „Sleep-time Compute: Beyond Inference Scaling at Test-time.“ arXiv:2504.13171 — Letta + UC Berkeley
- NVIDIA. „RULER: What’s the Real Context Size of Your Long-Context Language Models?“ github.com/NVIDIA/RULER
- Letta Blog (2025). „Benchmarking AI Agent Memory.“ letta.com/blog/benchmarking-ai-agent-memory
- Letta Blog (2025). „Letta Leaderboard.“ letta.com/blog/letta-leaderboard
Schreibe einen Kommentar