What’s ITIL at all ?
ITIL (IT Infrastructure Library) is a description of different
processes to manage the whole IT
Infrastruture from the first use of
a software to user helpdesks. The aim of the defined processes
provide high qualitiy software and therefore satisfied users. ITIL
procedures are widely
implemented in hundreds of organisations all
over the world. ITIL is not a theoratical set of information
and
process descriptions. ITIL best pratice tries to adapt working
processes in IT Infrastructure which
had been effective in the past.
The aim is
-
to
reduce costs -
have
satisfied customers -
provide
high quality IT -
to
create a basis for quality management -
better
communication between customers and IT staff -
more
satisfied IT staff to reduce staff fluctuations.
To reach the above descripted aims the Service Management is divided
in serveral parts:
Kurze Unterbechung
Das ist dein Alltag?
Keine Sorge – Hilfe ist nah! Melde Dich unverbindlich bei uns und wir schauen uns gemeinsam an, ob und wie wir Dich unterstützen können.
-
Business
Management -
Application
Management -
Service
Management -
Security
Management -
IT
Infrastructure Management
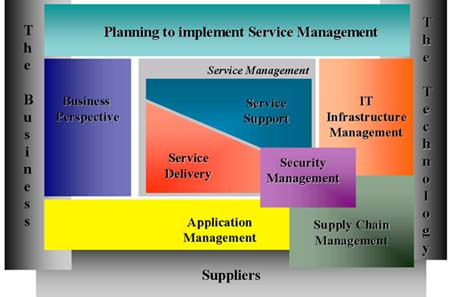
For more details on the different management levels have a look at
http://www.itsmf.com or
http://www.itil.co.uk.
Staging
Process for Software Release
I’d like to take a look onto the stages a new application release has
typically go through.
First of all there is some kind of specification which changes, fixes
and features should be presented in
the next release. Let’s imagine
the specifications are given and the developers did there best to
meet them.
Before the new product release can be used by the customer it has to
prove itself to be working and
beeing without any critical bugs. That
most of the times means the software has to go through some
kind of
testing. There are a lot a different attempts for testing. Most of
them have in common that the
tests are done in some kind of test
environment.
Let’s imagine the developers have been working on some kind of
developing environment. The first
developer tests show, that the
application is ready to be released because no malfunctions have been
found. Let’s call this first environment the IT Environment. The
experiences show that the technical IT
environment is most of the
time not exactly the same as the one the application should work on
later.
Furthermore not all of the different interfaces to other
systems the application is working with are reachable
from the IT
System.
After finishing all relevant tests in the IT environment the
application release can take the next stage to
become a productive
peace of software. The application and all changes on the databases
have to be
handed over by a defined process to the quality assurance
stage. This environment should be build up
like the one the
application will finaly work on. The consistency or at least
similarity of the systems is
requisite to ensure the same behaviour
on both systems. This enhances the chance to find problems and
bugs
happening under special circumstances or environments. After
finishing the tests of the application
on the second stage the
application can finally be released in a productive area.
The descripted process defines 3 different stages the application has
to go through and work on:
-
IT
environment -
qualitiy
assurance environment -
production
environment
Normally each stage finds itself in different surroundings which
means different adjustments to the software
in each stage for example
the IP of a Proxy. Different configurations like an IP adress for a
proxy means you
should handle the different configurations in a
somekind of intelligent way.
Handling
different Configurations
Let’s imagine again. Imagine a little application with
-
database
connection -
mail
delivery -
a
hand full of defined variables
Let’s see how we can handle the configurations on the systems under
different conditions.
First assumption:
You know ALL configuration settings on all systems.
Easiest way:
-
1
File with all the configuration which do not change between the
systems -
1
File with environment specific data
The configurations which are depending on the system or environment
can be defined by an easy
switch-statement.
<?php
define(CONF_ENVIRONMENT, ‚IT‘);
switch (CONF_ENVIRONMENT) {
case ‚IT‘:
define(CONF_MAIL_PROXY, ‚Proxy_IT‘);define(CONF_DB_NAME, ‚test‘);
define(CONF_DB_USER, ‚user1‘);
define(_CONF_DB_PASSWORD, ‚password‘);
break;case ‚QAS‘:
define(CONF_MAIL_PROXY, ‚Proxy_QAS‘);
define(CONF_DB_NAME, ‚project1‘);
define(CONF_DB_USER, ‚projectuser1qas‘);
define(_CONF_DB_PASSWORD, ‚password‘);
break;case ‚PROD‘:
default:
define(CONF_MAIL_PROXY, ‚Proxy_PROD‘);
define(CONF_DB_NAME, ‚important‘);
define(CONF_DB_USER, ‚importantuser‘);
define(_CONF_DB_PASSWORD, ‚passwordprod‘);
break;}
This can be done for kind of small configuration files and under the
assumption the informationen of
all systems are known by the
developers. It is not too elegant but it is working fine.
Second Way:
-
1
File with all the configurations which have the same value on each
system -
1
File for each stage -
1
File for checking
The first file includes all configurations which do not differ on the
different stages. The three configuration
files should have different
names which are identifying the files. To use them an include based
on the
system is needed or a simple copy to a defined filename is
used. Try to find an automatic way!
Configuration File stage IT: config_IT.php
<?php
define(CONF_MAIL_PROXY, ‚Proxy_IT‘);
define(CONF_DB_NAME, ‚test‘);
define(CONF_DB_USER, ‚user1‘);
define(_CONF_DB_PASSWORD, ‚password‘);
Configuration File stage QAS: config_QAS.php
<?php
define(CONF_MAIL_PROXY, ‚Proxy_QAS‘);
define(CONF_DB_NAME, ‚project1‘);
define(CONF_DB_USER,
‚projectuser1qas‘);define(_CONF_DB_PASSWORD, ‚password‘);
Configuration File stage PROD: config_PROD.php
<?php
define(CONF_MAIL_PROXY, ‚Proxy_PROD‘);
define(CONF_DB_NAME, ‚important‘);
define(CONF_DB_USER, ‚importantuser‘);
define(_CONF_DB_PASSWORD,
‚passwordprod‘);
To include the specific configuration file either inlcude it in the standardised configuration file
<?php
define(CONF_SOME_DATA,
‚definition‘);define(CONF_ENVIRONMENT,
‚IT‘);include_once(‚config_‘
. CONF_ENVIRONMENT . ‚.php‘);
or which is much nicer – define it in some kind of build process.
Much more authentic assumption:
You do not know ALL configuration settings on all systems.
Several settings have to be defined from the serveral persons in
charge on the different machines.
That means in the worst case on
each stage someone is either changing the values of the
configuration
files manually (what a mess) or copying the
configuration file from the last time to the defined place.
This
always brings up problems with adding new configurations and
forgetting to enter them into the
‚old‘ configuration files.
The most sexiest way to solve these problems is to keep ALL
configuration settings in the hand of the
developer. How is that
possible. I just said the assumption is that we do not know the
setting values.
How do you hide for example passwords from too curios
database administrators? You encrypt them.
The solution is an encryption mechanism which is put into a special
encryption and decryption file. The
persons in charge now can give
away there confidential information about the settings and the
developer
can hold all the important configuration information for
all stages together.
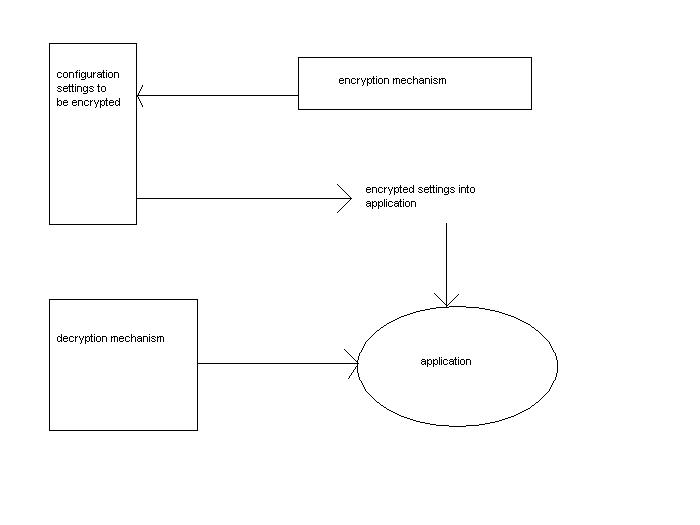
The application is storing the encryted configurations for the QAS and PROD environments internally. To get access
to the settings it can ask a decryption service to convert it into processable information.
I prefer ways were we can make as less mistakes as possible because we
are only human and someone
said that humans are not perfect. Those
who did copy or delete a wrong file without recognizing
it at once
should know – all the outhers out there should believe.
That means keep the information the application needs through all stages togehter at one point and automate us
much as possible.

Schreibe einen Kommentar