
The first two articles in this series used one vector per document or passage. That is the common shape for dense retrieval: embed every chunk into one vector, index those vectors, and retrieve the nearest neighbours for a query vector.
That works well for many RAG systems, but it has a limitation: one vector is a summary. It compresses the important terms, entities, syntax, and meaning of a passage into one point. Sometimes that is exactly what you want. Sometimes it hides the evidence you care about.
ColBERT-style late interaction uses a different shape. Instead of one vector per passage, it keeps many token vectors per passage. At query time, each query token looks for the best matching token in a document, and the document score is built from those token-level matches.
pg★ Kurze Unterbrechung · Open Source Der Code zur Serie. Auf GitHub, zum Selberrechnen. Dense Hybrid Late Interaction pgturbohybrid · PostgreSQL-Extension GitHub Repo öffnen →pgturbohybrid adds an experimental turbohybrid_multivector type for this style of retrieval. The index can search token vectors as graph subnodes, but SQL still returns PostgreSQL rows.
Why one vector per document is sometimes not enough
A passage can contain several pieces of evidence:
The PostgreSQL extension retries failed webhook deliveries when the gateway returns ERR-8492.
A single embedding may capture the general meaning: PostgreSQL, extension, webhook retry, gateway failure. But a search system may need token-level precision:
PostgreSQLextensionwebhookgatewayERR-8492
Late-interaction retrieval keeps more of that token-level evidence alive.
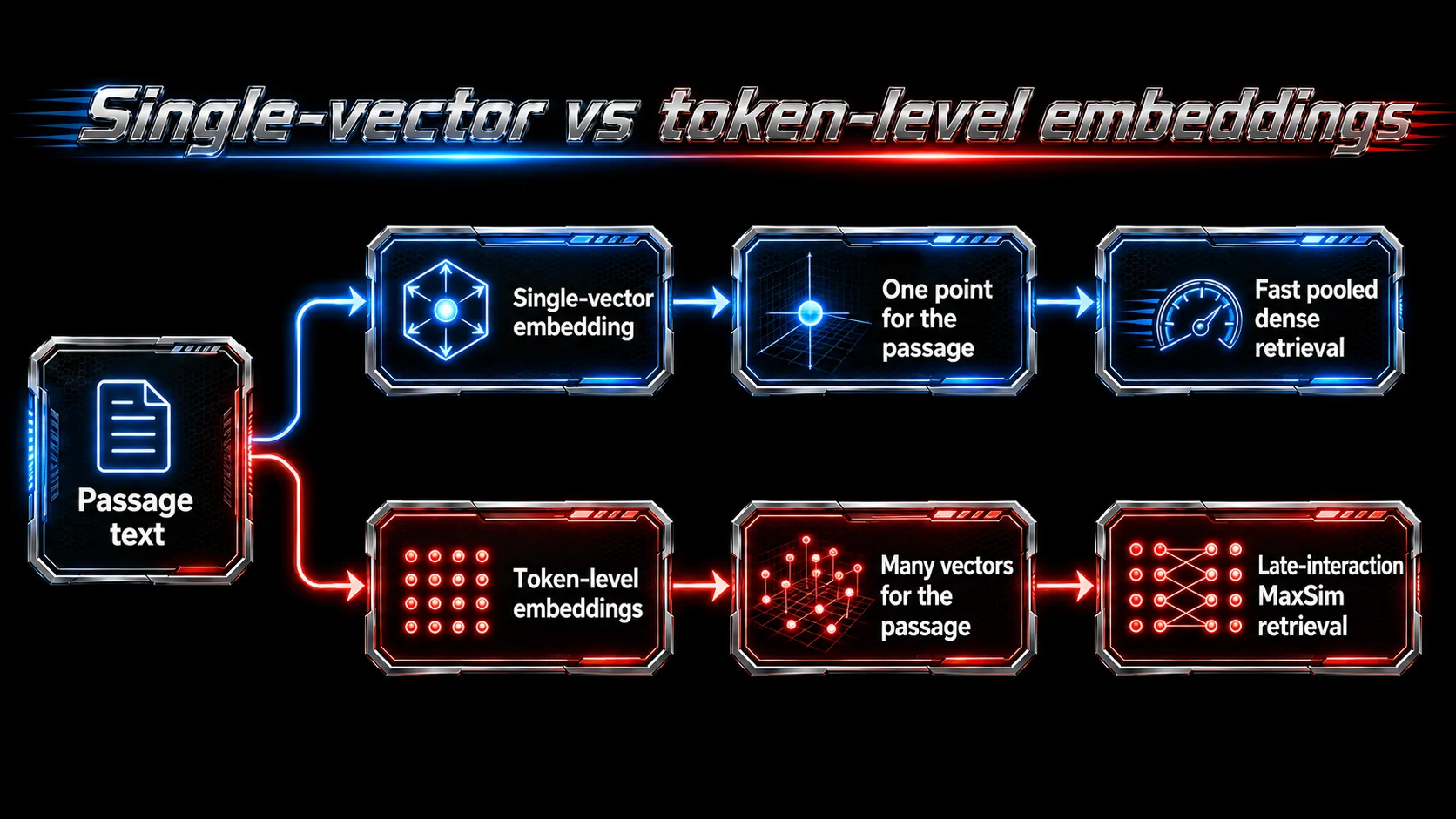
The tradeoff is obvious: multivector retrieval is richer, but more expensive. There are more vectors to store, index, search, and score.
MaxSim in one small math box
In ColBERT-style late interaction, the query and document are both represented as multiple vectors.
Query: q1, q2, q3, ... qQ Document: d1, d2, d3, ... dD
For each query token vector, find the best matching document token vector:
best(qi, document) = max_j dot(qi, dj)
Then sum those best matches:
MaxSim(query, document) = sum_i max_j dot(qi, dj)
A higher MaxSim score means a better match.
PostgreSQL index scans usually expose smaller-is-better distances for ORDER BY. Therefore pgturbohybrid exposes multivector distance as:
distance = -MaxSim(query, document)
The core invariant
The most important design rule in pgturbohybrid multivector search is this:
graph node = token vector / subvector SQL result = PostgreSQL heap tuple / document row score = document-level MaxSim ORDER BY = -MaxSim distance
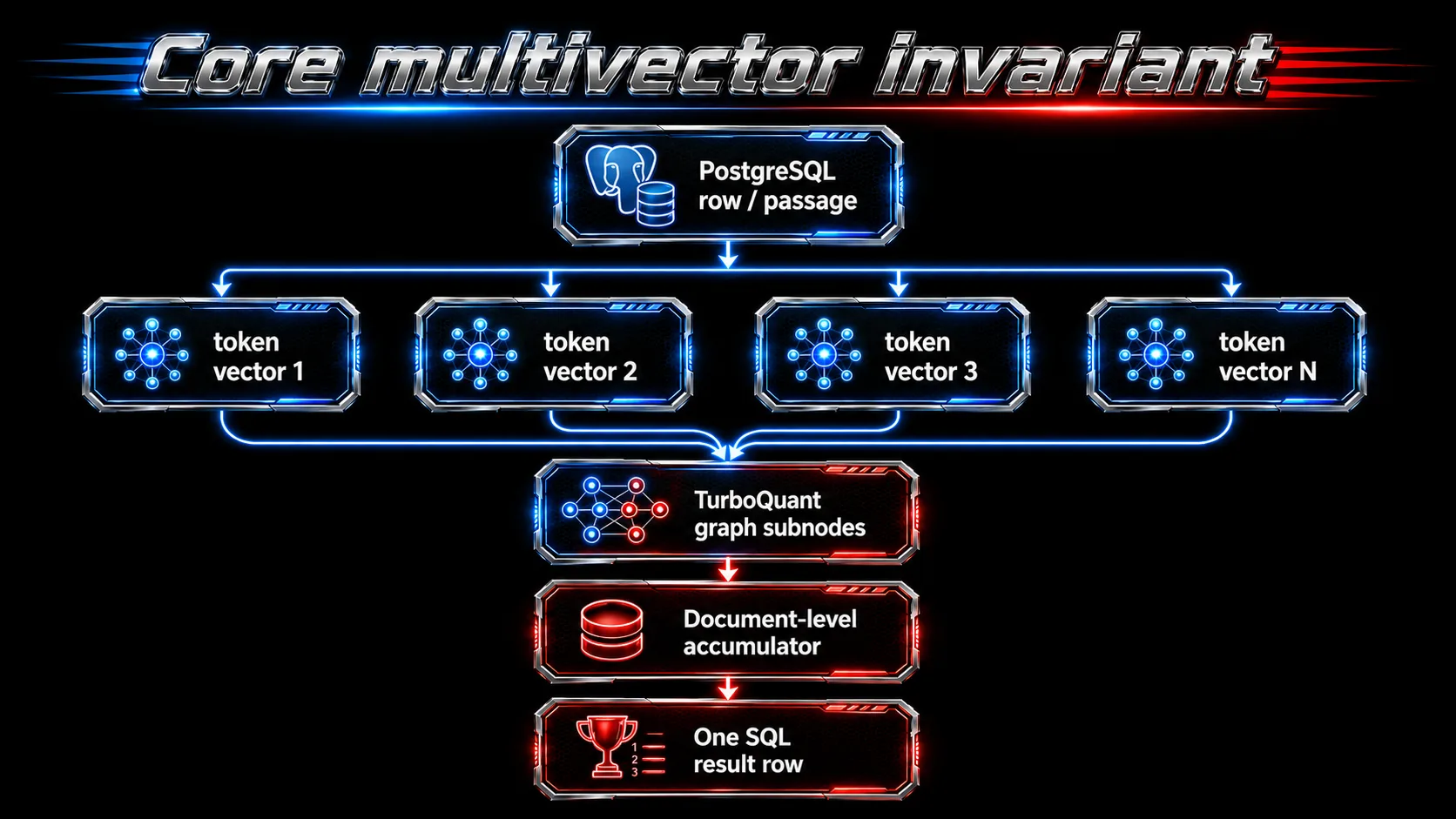
Internally, the index searches many subnodes. Externally, the user still gets rows. This is the difference between implementation identity and result identity.
That invariant prevents a common bug in multivector systems: returning the same document multiple times because several token vectors matched. In pgturbohybrid, token hits are folded back into document-level candidates.
The turbohybrid_multivector type
A turbohybrid_multivector stores multiple same-dimensional token vectors in one PostgreSQL value.
You can build one from an array of pgvector values:
CREATE EXTENSION vector;
CREATE EXTENSION pgturbohybrid;
CREATE TABLE passages (
id bigserial PRIMARY KEY,
body text,
colbert turbohybrid_multivector NOT NULL
);
INSERT INTO passages (body, colbert)
VALUES (
'PostgreSQL supports extensions.',
turbohybrid_multivector(ARRAY[
'[1,0,0]'::vector,
'[0,1,0]'::vector
])
);
Inspect dimensions and token-vector count:
SELECT
id,
turbohybrid_multivector_dims(colbert) AS dim,
turbohybrid_multivector_count(colbert) AS token_vectors
FROM passages;
If an embedding extension already has flat row-major float4 data, it can avoid building intermediate vector[] values:
SELECT turbohybrid_multivector_from_float4(
ARRAY[1, 0, 0, 0, 1, 0]::real[],
3
);
That represents two 3-dimensional token vectors.
Dense-only multivector search
For new multivector indexes, use multivector_maxsim_ip_turbohybrid_ops:
CREATE INDEX passages_colbert_idx
ON passages
USING turbohybrid (
colbert multivector_maxsim_ip_turbohybrid_ops
);
Then query with a multivector payload:
SELECT id, body
FROM passages
ORDER BY colbert <~> turbohybrid_query(
multivector_query => turbohybrid_multivector(ARRAY[
'[1,0,0]'::vector,
'[0,1,0]'::vector
]),
dense_k => 100,
final_k => 10
)
LIMIT 10;
The operator is still <~>, but the left side is a turbohybrid_multivector, and the query payload uses multivector_query instead of vector_query.
Do not mix vector_query and multivector_query in the same turbohybrid_query(...). They represent different dense query shapes.
How the scan works
A multivector scan has more stages than single-vector dense retrieval.
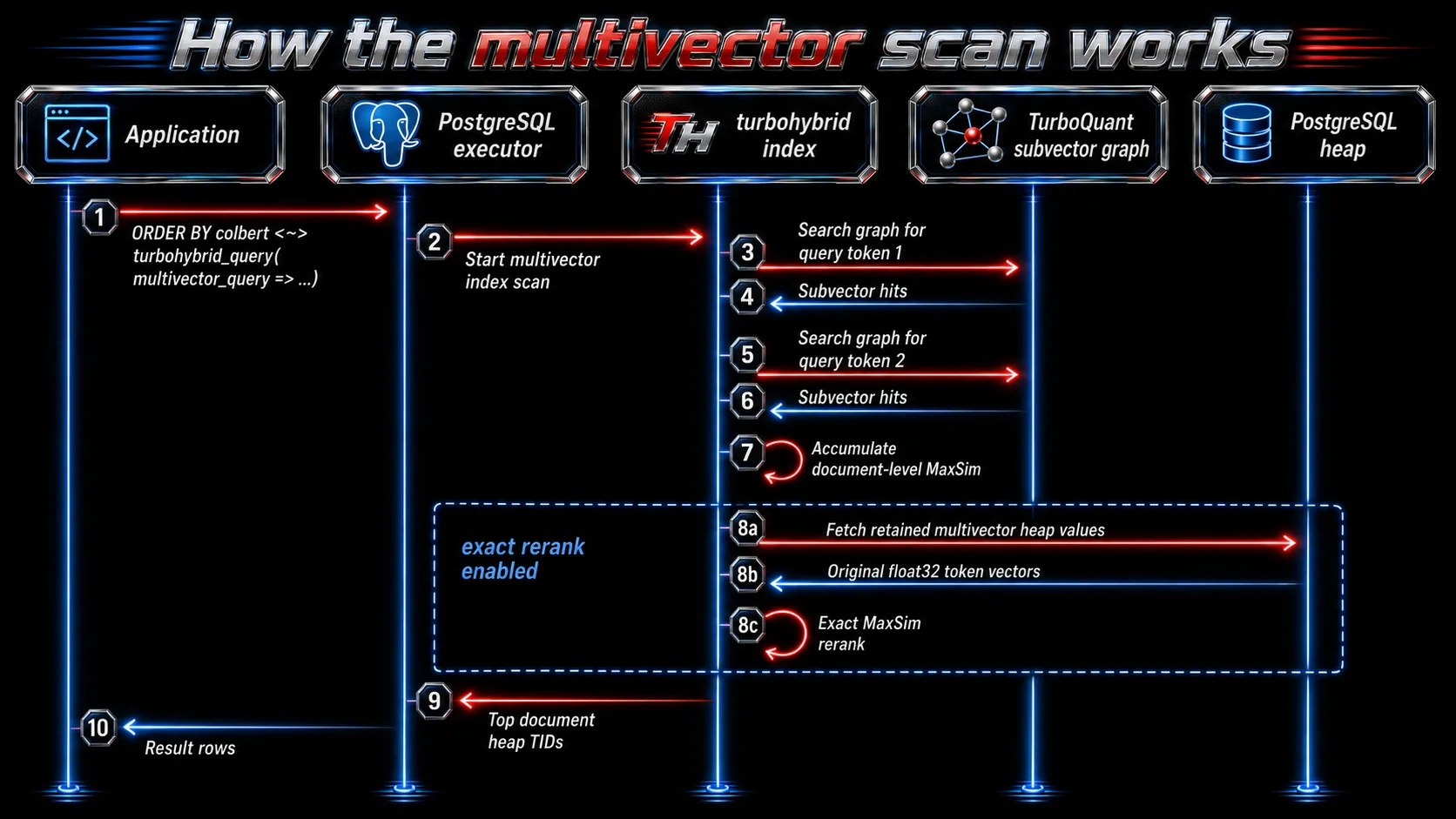
The approximate candidate collection works like this:
- Each query token vector searches the TurboQuant graph.
- The scan receives token-level hits.
- Hits are mapped back to document/heap tuple identity.
- For each document candidate, the scan accumulates an approximate MaxSim score.
- The scan keeps a bounded set of document candidates.
- Optionally, the scan fetches heap multivectors and computes exact float32 MaxSim for the retained prefix.
The important performance detail is that the accumulator is document-level, not global over all documents and all tokens. Candidates stay bounded rather than materializing a full query-token by corpus-token matrix.
Tuning knobs
The main candidate-collection knobs are:
SET turbohybrid.multivector_subvector_k = 100; SET turbohybrid.multivector_unique_docs_per_token = 100; SET turbohybrid.multivector_max_raw_hits_per_token = 400; SET turbohybrid.multivector_doc_candidate_k = 100;
A practical interpretation:
| Setting | What it controls |
|---|---|
multivector_subvector_k | Initial raw subvector hit target per query token |
multivector_unique_docs_per_token | Desired document diversity per token |
multivector_max_raw_hits_per_token | Hard cap for widened token searches |
multivector_doc_candidate_k | Final approximate document candidate budget |
Exact reranking is controlled separately:
SET turbohybrid.multivector_exact_rerank = 'topk'; -- or 'off' SET turbohybrid.multivector_exact_rerank_k = 100;
With exact rerank enabled, the index still uses compact TurboQuant subvector nodes for candidate generation. For a bounded number of retained document candidates, it fetches the original turbohybrid_multivector value from the heap and computes exact float32 MaxSim.
That gives the same basic pattern as dense TurboQuant retrieval:
compact approximate candidate generation
-> bounded exact rerank when needed
Hybrid multivector + BM25
The multivector path can also be combined with the BM25 branch in a hybrid index:
CREATE TABLE hybrid_passages (
id bigserial PRIMARY KEY,
body text NOT NULL,
body_tsv tsvector GENERATED ALWAYS AS (
to_tsvector('english', body)
) STORED,
colbert turbohybrid_multivector NOT NULL
);
CREATE INDEX hybrid_passages_idx
ON hybrid_passages
USING turbohybrid (
colbert multivector_maxsim_ip_turbohybrid_ops,
body_tsv bm25_tsvector_turbohybrid_ops
);
Query with document-level RRF:
SELECT id, body
FROM hybrid_passages
ORDER BY colbert <~> turbohybrid_query(
multivector_query => $1,
text_query => websearch_to_tsquery('english', $2),
fusion => 'rrf',
dense_k => 100,
bm25_k => 100,
final_k => 10
)
LIMIT 10;
The fusion happens at document level:
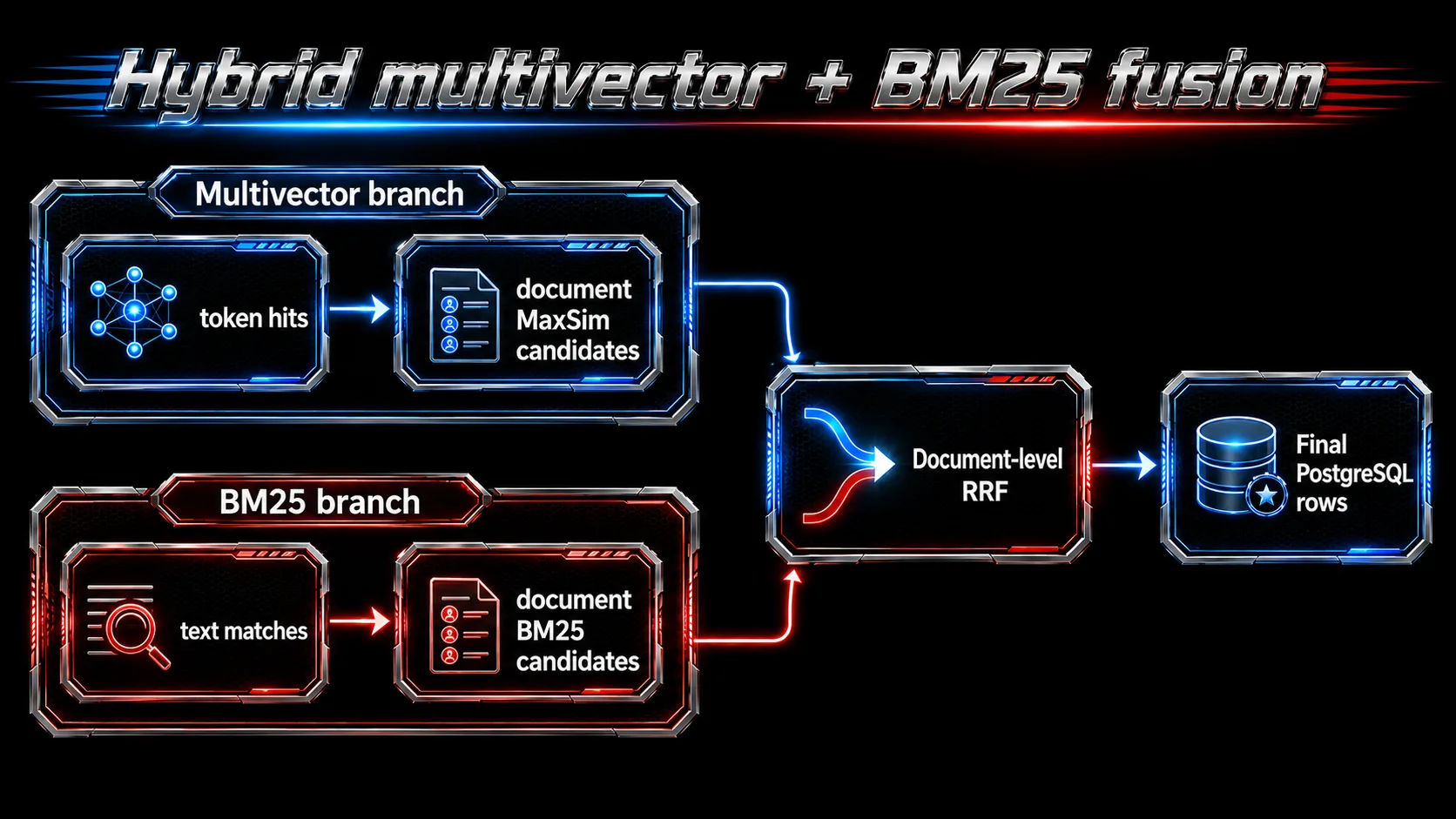
This is the safe story to tell today: multivector MaxSim candidates and BM25 candidates are both keyed by heap tuple/document, then RRF combines document ranks.
Score-level fusion modes are more limited for multivector hybrid scans. For alpha-stage use, treat document-level RRF as the primary supported path.
Generating multivectors with pg_colbert_llama
A multivector index needs multivectors. You can generate them outside PostgreSQL and insert them, but pgturbohybrid also includes a companion extension: pg_colbert_llama.
The split is intentional:
pg_colbert_llama handles model loading, tokenization, projection, normalization, and embedding policy. pgturbohybrid stays focused on storage, indexing, graph search, MaxSim aggregation, and fusion.
Install the extensions:
CREATE EXTENSION vector; CREATE EXTENSION pgturbohybrid; CREATE EXTENSION pg_colbert_llama;
Generate a query multivector:
SELECT colbert_mv(
'sauerkraut-modern:query',
'What is PostgreSQL?'
);
Generate a document multivector:
SELECT colbert_mv(
'sauerkraut-modern:doc',
'PostgreSQL is an extensible relational database.'
);
The model string uses this shape:
<alias>:query <alias>:doc
The alias resolves to an administrator-installed GGUF file under pg_colbert_llama.model_dir.
Ingest with local embeddings
A practical table for ColBERT-style passage retrieval might look like this:
CREATE TABLE passages (
id bigserial PRIMARY KEY,
doc_id bigint NOT NULL,
chunk_no int NOT NULL,
body text NOT NULL,
body_tsv tsvector GENERATED ALWAYS AS (
to_tsvector('simple', body)
) STORED,
colbert turbohybrid_multivector NOT NULL
);
Ingest should be explicit rather than a generated column, because model output depends on model bytes, extension version, llama.cpp version, hardware/backend settings, prefixes, and tokenization settings:
INSERT INTO passages (doc_id, chunk_no, body, colbert)
SELECT
doc_id,
chunk_no,
body,
colbert_mv('sauerkraut-modern:doc', body)
FROM staging_passages;
Build a hybrid index:
CREATE INDEX passages_colbert_hybrid_idx
ON passages
USING turbohybrid (
colbert multivector_maxsim_ip_turbohybrid_ops,
body_tsv bm25_tsvector_turbohybrid_ops
);
Search with local query embedding and BM25 RRF:
SELECT id, doc_id, chunk_no, body
FROM passages
ORDER BY colbert <~> turbohybrid_query(
multivector_query => colbert_mv('sauerkraut-modern:query', $1),
text_query => websearch_to_tsquery('simple', $1),
fusion => 'rrf',
dense_k => 300,
bm25_k => 300,
final_k => 20
)
LIMIT 20;
This query contains a lot of machinery in one SQL expression:
text query -> local query multivector -> multivector MaxSim candidate search -> BM25 candidate search -> document-level RRF -> PostgreSQL rows
What the embedding engine does internally
pg_colbert_llama exposes several functions:
colbert(model text, input text) RETURNS jsonb colbert_vectors(model text, input text) RETURNS vector[] colbert_float4(model text, input text) RETURNS real[] colbert_dim(model text, input text) RETURNS int4 colbert_mv(model text, input text) RETURNS turbohybrid_multivector colbert_model_info(model text) RETURNS jsonb
The colbert_mv(...) path is the convenient one for pgturbohybrid indexing.
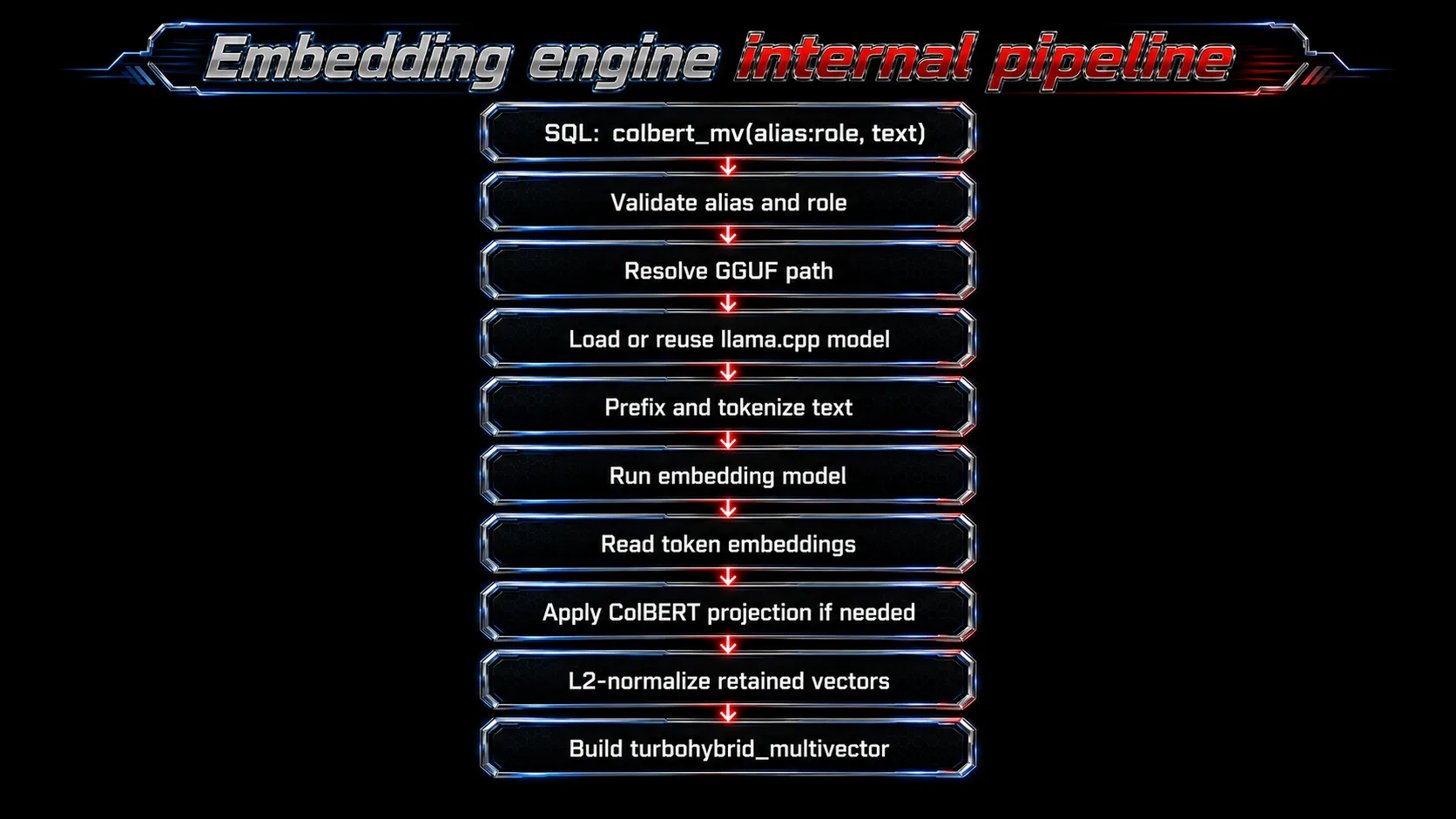
At a high level, the engine:
- parses the model alias and role;
- resolves the alias to a GGUF file under an admin-controlled model directory;
- loads the model with llama.cpp;
- enables embedding output with no pooling;
- applies query or document prefixes;
- tokenizes input text;
- optionally pads short queries with mask tokens for query expansion;
- runs the encoder;
- reads per-token embeddings;
- optionally applies a ColBERT projection;
- L2-normalizes retained token vectors;
- returns a
turbohybrid_multivector.
For ModernBERT/ColBERT-style models, the output dimension is normally 128 after the ColBERT projection. The embedding engine validates the expected dimension and can require token vectors to be normalized before they are returned.
Operational notes
Because this is alpha-stage functionality, operational details matter.
Model files are administrator-controlled
Callers pass aliases, not arbitrary paths:
SELECT colbert_mv('sauerkraut-modern:query', 'Was ist PostgreSQL?');
The extension resolves this to:
${pg_colbert_llama.model_dir}/sauerkraut-modern.gguf
That avoids turning SQL into arbitrary filesystem access.
Query and document roles are separate
ColBERT-style models often treat queries and documents differently. The extension supports role-specific prefixes:
pg_colbert_llama.query_prefix = '[Q] ' pg_colbert_llama.document_prefix = '[D] '
Use alias:query for user queries and alias:doc for stored passages.
Keep ingest explicit
Do not hide embedding generation in a generated column unless you have a very controlled environment. Embedding output depends on model files and runtime settings. Explicit ingest makes reindexing, re-embedding, and reproducibility easier.
Expect more storage and build work
If every passage has L token vectors, the graph indexes roughly D * L subnodes for D documents. That is the point of late interaction, but it is also the cost.
A useful sizing model is:
D = documents or passages L = token vectors per document Q = query token vectors N = graph subnodes = D * L
Candidate collection performs graph work per query token, then aggregates back to documents. Exact rerank work is roughly proportional to:
rerank_docs * query_vectors * document_vectors * dimensions
Bound the rerank prefix and token counts before evaluating large corpora.
Diagnostics
After a multivector scan, inspect:
SELECT turbohybrid_last_scan_stats();
Useful fields include:
- multivector enabled flag;
- number of query vectors;
- subvector searches;
- raw subvector hits;
- unique document candidates;
- duplicate document hits;
- MaxSim updates;
- exact rerank count;
- exact rerank pairs;
- exact kernel used;
- accumulator memory estimate.
The diagnostic goal is to answer questions like:
Did we collect enough unique document candidates per token? Did exact rerank run? Was the accumulator bounded? Are duplicate token hits dominating candidate collection? Which exact MaxSim kernel was used?
Current limitations
The main limitations to keep in mind:
- Multivector retrieval is alpha.
vector_queryandmultivector_querycannot be mixed in oneturbohybrid_query(...).- New indexes should use
multivector_maxsim_ip_turbohybrid_ops. - Stored and query token vectors should be L2-normalized when you want cosine-like ColBERT scoring with raw dot-product MaxSim.
- Hybrid multivector + BM25 should be treated as document-level RRF today.
- Exact rerank fetches heap multivectors for a bounded candidate set; the compact index does not store full float copies by default.
- The embedding engine is a companion extension and depends on local model files, llama.cpp build choices, and GGUF compatibility.
That list is not a warning away from the feature. It is the honest shape of an alpha system: useful for evaluation, demos, and research-driven product exploration, but still evolving.
Beiträge aus dieser Reihe



Summary
Single-vector dense retrieval asks:
Which document vector is closest to this query vector?
Late-interaction retrieval asks a richer question:
For each query token, which document token matches best, and how strong is the sum of those token-level matches?
pgturbohybrid maps that model into PostgreSQL with one central invariant:
internal graph nodes are token vectors; external SQL results are rows.
turbohybrid_multivector stores token vectors. The index expands them into graph subnodes. The scan aggregates approximate MaxSim back to documents. Exact rerank can fetch original heap multivectors for a bounded candidate prefix. BM25 can be fused at document level with RRF. pg_colbert_llama can generate ModernBERT/ColBERT-style multivectors locally through llama.cpp.
This is where PostgreSQL-native retrieval starts to look less like “a vector column plus an index” and more like a full retrieval stack: embedding generation, token-level search, lexical evidence, rank fusion, diagnostics, and SQL rows.
Schreibe einen Kommentar