
A/B-Tests haben in der digitalen Produktentwicklung den Ruf, die verlässlichste Methode zu sein, um Designentscheidungen zu validieren. Wer eine Annahme hat, testet sie – und die Daten entscheiden.
So weit die Theorie. In der Praxis erleben viele Teams, dass A/B-Tests mehr Aufwand erzeugen als sie lösen: Testaufbauten, die Wochen dauern, Ergebnisse ohne statistische Aussagekraft, und Backlogs voller Testhypothesen, die niemand mehr priorisieren kann.
Im Rahmen unseres Projekts mit einem etablierten deutschen Mode-Versandhändler habe ich genau diese Herausforderungen zum Anlass genommen, strukturierte Werkzeuge dafür zu entwickeln. Das Besondere: Beide Werkzeuge sind in enger Zusammenarbeit mit Claude Sonnet, dem KI-Modell von Anthropic, entstanden.
m w5 Kurze Unterbrechung · mAIstack Von PoC zu Produktion. In Wochen, nicht Quartalen. Median-Time-to-first-Usecase: 5 Wochen · On-Premise · 100+ Connectors mAIstack Ansehen →Was in einer klassischen Workshop-Reihe Wochen gedauert hätte, war in wenigen iterativen Gesprächen mit der KI praxisreif – ein Entscheidungsbaum, der klärt, wann ein A/B-Test überhaupt sinnvoll ist, und ein Priorisierungs-Framework, das strukturiert bewertet, welche Tests zuerst durchgeführt werden sollten.
Dieser Artikel stellt beide Werkzeuge vor, zeigt, wie sie im Zusammenspiel funktionieren und beleuchtet, was dieser KI-gestützte Entwicklungsprozess für Produktteams bedeutet.
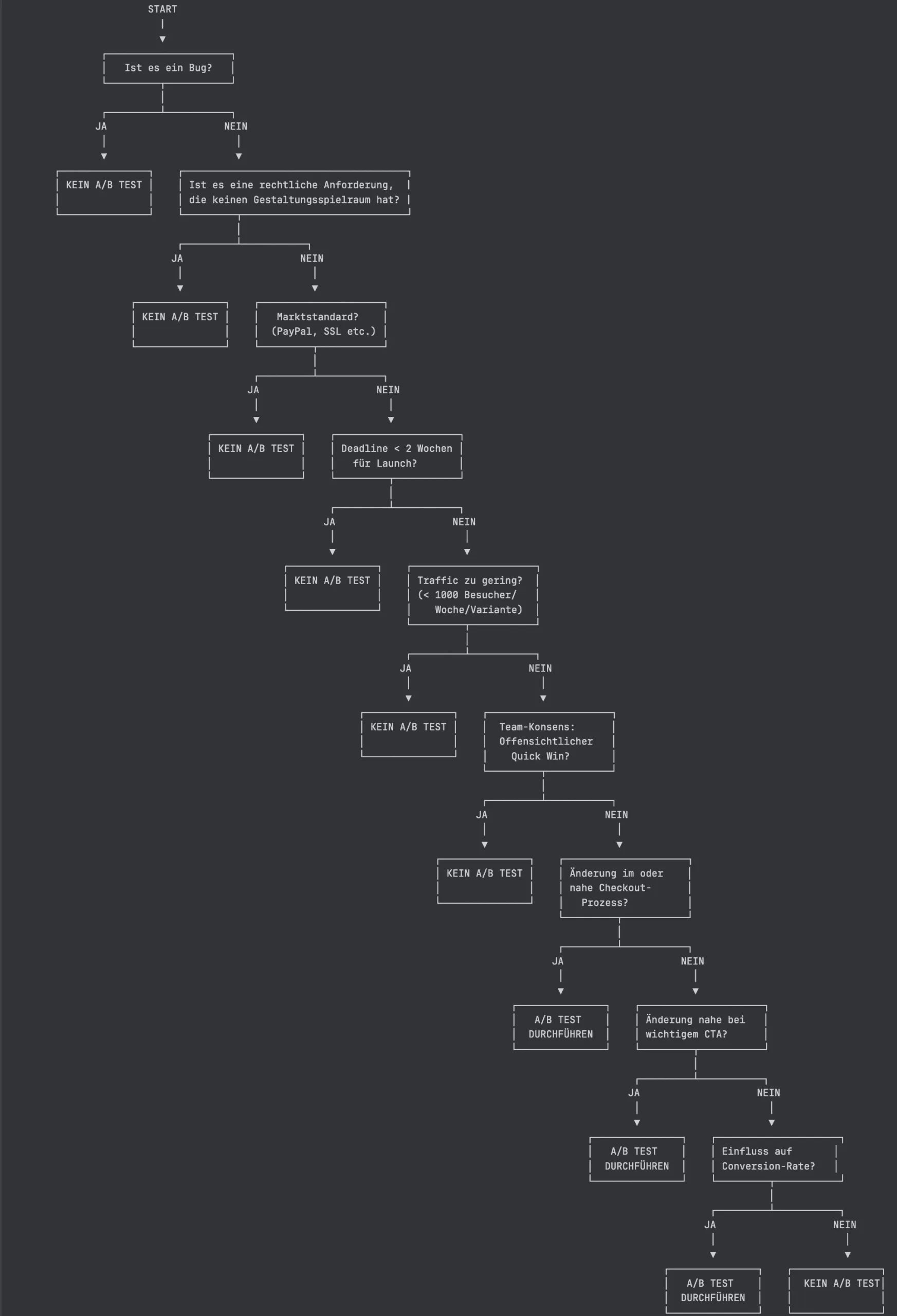
Die sechs Ausschlusskriterien
- Ist es ein Bug? Bugs werden behoben, nicht getestet. Eine fehlerhafte Funktion zu reparieren ist keine Hypothese, sondern eine Notwendigkeit. Wer einen Fehler im A/B-Test versteckt, riskiert, den Schaden zu messen, statt ihn zu beseitigen.
- Gibt es keinen Gestaltungsspielraum? Manche Änderungen sind gesetzlich oder regulatorisch vorgeschrieben. Datenschutzhinweise, Impressumspflichten oder Barrierefreiheitsanforderungen sind keine Variablen – sie werden implementiert, ohne zu testen.
- Ist es ein Marktstandard? Bestimmte Elemente wie das PayPal-Logo, ein SSL-Zertifikat oder Standard-Checkout-Flows sind in ihrer Grundform etabliert. Ihr Einsatz erzeugt Vertrauen durch Wiedererkennung. Diese Entscheidungen müssen nicht hinterfragt werden.
- Ist die Deadline kürzer als zwei Wochen bis zum Launch? A/B-Tests brauchen Zeit für den Aufbau, die Laufzeit und die Auswertung. Wer ein Feature in weniger als zwei Wochen liefern muss, sollte es ohne Test releasen und gegebenenfalls später testen.
- Ist der Traffic zu gering? Als Faustregel gilt: weniger als 1.000 Besucher pro Woche und Variante macht statistisch valide Ergebnisse kaum erreichbar. Tests unter dieser Schwelle liefern Rauschen statt Erkenntnisse.
- Ist es ein offensichtlicher Quick Win mit Team-Konsens? Wenn das gesamte Team einer Maßnahme zustimmt und der positive Effekt als sehr wahrscheinlich gilt, kann der Aufwand eines Tests größer sein als sein Nutzen. In solchen Fällen ist es legitim, direkt zu entscheiden.
Die drei Fälle, in denen getestet wird
Wenn keine der Ausschlussfragen mit „Ja“ beantwortet wird, stellen sich drei positive Kriterien:
- Die Änderung liegt im Checkout-Prozess oder in direkter Nähe dazu.
- Die Änderung befindet sich in der Nähe eines wichtigen Call-to-Action.
- Die Änderung hat einen potenziellen Einfluss auf die Conversion Rate (CR).
Wer den Entscheidungsbaum konsequent anwendet, wird feststellen, dass immer noch eine beachtliche Anzahl an Testhypothesen übrig bleibt. Die nächste Herausforderung ist die Priorisierung: Welcher Test bringt den größten Mehrwert? Welcher ist dringlich, welcher kann warten?
Erst qualifizieren, dann priorisieren
Das BUYER-Framework, das ich gemeinsam mit Claude Sonnet für unseren Kunden entwickelt habe, gibt auf diese Fragen eine strukturierte Antwort. Der Name ist dabei kein Zufall: Ausgangspunkt war die Frage, welche Kriterien direkt auf Kundennutzen und Kaufverhalten einzahlen – und Claude Sonnet hat nicht nur die Kriterien vorgeschlagen, sondern sie auch so formuliert, dass sie das Akronym BUYER ergeben.
Jedes Kriterium wird auf einer Skala von 1 bis 10 bewertet, wobei messbare Schwellenwerte die Bewertung objektivieren und subjektive Diskussionen im Team minimieren.
Kurze Unterbrechung – der Artikel geht gleich weiter!
Dein Thema?
Das klingt, als könnten wir dich bei deinem Thema unterstützen? Dann schreibe uns eine Nachricht und wir melden uns ganz unverbindlich bei dir!
Die fünf BUYER-Kriterien
B – Buying Journey Impact
Dieses Kriterium bewertet, wie nah die Änderung am Kaufmoment liegt und wie stark sie die CR beeinflussen kann. Eine Optimierung im Checkout erhält einen hohen Score (8–10), eine Anpassung im Footer einen niedrigen (1–3). Die Bewertung orientiert sich an der erwarteten CR-Steigerung: Werte über 5 Prozent gelten als hoher Impact, unter 0,5 Prozent als geringer.
U – User Experience Improvement
Hier wird gemessen, wie stark die Änderung die Benutzerfreundlichkeit verbessert. Entscheidend sind die Task Success Rate (wie erfolgreich schließen Nutzer Aufgaben ab?), der erwartete NPS-Delta (Veränderung der Weiterempfehlungsbereitschaft) und die mobile Performance. Ein Wert von 10 steht für mehr als 90 Prozent Task-Erfolg und einen NPS-Gewinn von über 20 Punkten.
Y – Yield per Customer
Dieses Kriterium fokussiert auf den monetären Ertrag pro Kunde: Steigt der durchschnittliche Bestellwert (AOV)? Wird Cross- oder Upselling gefördert? Eine AOV-Steigerung über 15 Prozent ergibt den Höchstwert, unter 2 Prozent den Mindestwert.
E – Engagement Enhancement
Hier fließt ein, ob die Änderung die Interaktion der Nutzer mit der Seite erhöht – gemessen an der Verweildauer, der Seitentiefe pro Session und der Feature-Adoption-Rate. Eine Feature-Adoption über 50 Prozent entspricht einem Score von 10.
R – Retention & Repeat Purchase
Das Retention-Kriterium bewertet den langfristigen Wert: Steigt die Wiederkaufrate? Sinkt die Churn-Rate? Verbessert sich der Customer Lifetime Value (CLV)? Eine Wiederkauf-Steigerung über 25 Prozent ist der Maximalwert.
Gewichtung und Gesamtscore
Nicht alle Kriterien sind gleich bedeutsam. Da Kaufverhalten und Kundennutzen im Vordergrund stehen, wird der Buying Journey Impact stärker gewichtet als beispielsweise das Engagement-Kriterium:
Gesamt-Score = (B×3 + U×2 + Y×2 + E×1,5 + R×2,5) ÷ 11
Das Ergebnis ist eine normierte Zahl zwischen 1 und 10. Tests mit einem Score über 7 werden priorisiert, Werte zwischen 4 und 7 kommen auf die mittelfristige Roadmap, darunter liegende Tests werden zurückgestellt oder verworfen.
Praxisbeispiel: Farbauswahl-Umrandung auf der Produktdetailseite
Schritt 1: Entscheidungsbaum anwenden
Die Änderung ist kein Bug, keine rechtliche Anforderung und kein Marktstandard. Die Deadline erlaubt ausreichend Zeit. Der Traffic auf der Produktdetailseite übersteigt deutlich die 1.000-Besucher-Grenze, und es gibt keinen Team-Konsens darüber, dass es sich um einen offensichtlichen Quick Win handelt.
Das positive Kriterium: Die Produktdetailseite liegt in direkter Nähe zum Warenkorb-CTA und beeinflusst potentiell die Kaufentscheidung. Damit ist der Test qualifiziert.
Schritt 2: BUYER-Score berechnen
| Kriterium | Score | Begründung |
|---|---|---|
| B | 6 | Produktdetailseite, 1–3 Prozent CR-Steigerung erwartet |
| U | 7 | Bessere Accessibility, +5–10 NPS-Punkte erwartet |
| Y | 4 | 2–5 Prozent AOV-Steigerung durch klarere Farbauswahl |
| E | 5 | 5–10 Prozent mehr Interaktion mit der Farbauswahl |
| R | 3 | Minimal bessere Kundenzufriedenheit |
Gesamt-Score: (6×3 + 7×2 + 4×2 + 5×1,5 + 3×2,5) ÷ 11 = 5,0 / 10
Interpretation
Ein Score von 5,0 signalisiert mittlere Priorität. Der Test sollte nicht sofort gestartet werden, wenn wichtigere Hypothesen verfügbar sind. Es hat aber seinen Platz in der mittelfristigen Roadmap. Er ist klar kein „Sofort“-Kandidat, aber auch kein Test, der verworfen werden sollte – denn der UX-Gewinn und die Accessibility-Verbesserung sind real messbar.
KI als Werkzeug für Methodenentwicklung
Was dieses Projekt auch jenseits der Werkzeuge selbst zeigt: KI-Modelle wie Claude Sonnet sind nicht nur für die Texterstellung oder Codegenerierung nützlich. Sie eignen sich sehr gut dafür, methodisches Wissen zu strukturieren, Bewertungskriterien zu entwickeln und Frameworks in einem iterativen Dialog zu schärfen.
Der Prozess verlief in wenigen Gesprächsrunden: Ausgangspunkt waren konkrete Fragen aus dem Projektalltag. Natürlich war unter meinen Vorschlägen für ein Priorisierungsframework nicht nur das von Claude erdachte, sondern auch eine Reihe von “etablierten” Frameworks wie ICE, BRASS und MoSCoW. Es wurde unter den Verantwortlichen abgestimmt und das BUYER Framework hat haushoch gewonnen.
Aufgrund dieses Resultats habe ich daraus Vorschläge für Kriterien und Strukturen abgeleitet, die wir im Team direkt auf unsere Realität geprüft und angepasst haben. Das Ergebnis war innerhalb eines Tages einsatzbereit – ohne Whiteboard-Workshop, ohne externe Beratung.
Das bedeutet nicht, dass die KI die inhaltliche Arbeit ersetzt. Die fachlichen Entscheidungen – welche CR-Schwellenwerte beim Kunden realistisch sind, wie stark Retention im Vergleich zu sofortigem Umsatz gewichtet werden soll – blieben im Team. Aber die KI hat die Strukturierungsarbeit übernommen, Formulierungen vorgeschlagen und den Prozess erheblich beschleunigt.
Fazit
Die Kombination aus Entscheidungsbaum und BUYER-Framework macht A/B-Tests zu einem steuerbaren Prozess statt einem Bauchgefühl-getriebenen Zufallsexperiment. Das Zwei-Stufen-Modell – erst qualifizieren, dann priorisieren – spart Ressourcen, schafft Transparenz im Team und stellt sicher, dass die Tests mit dem höchsten Kundennutzen zuerst umgesetzt werden.
Beide Werkzeuge sind bewusst adaptierbar gestaltet: Die Ausschlusskriterien im Entscheidungsbaum lassen sich an unternehmensspezifische Deadlines oder Traffic-Realitäten anpassen. Die BUYER-Gewichtung kann justiert werden, wenn sich Unternehmensziele verschieben. Und beides lässt sich – wie in diesem Projekt – gemeinsam mit einer KI weiterentwickeln, wenn sich die Anforderungen ändern.
Wenn ihr in eurem E-Commerce-Umfeld ähnliche Herausforderungen kennt – zu viele Hypothesen, zu wenig Klarheit, zu knappe Ressourcen für Tests – sprecht uns gerne an. Wir helfen dabei, ein Framework zu entwickeln, das zu eurer Produktstrategie passt.
*sort of …
Schreibe einen Kommentar