
Joon Sung Park und sein Team haben 2023 eines der überzeugendsten Experimente zum episodischen Gedächtnis in LLM-Agenten gebaut – und Endel Tulving nicht einmal zitiert. Trotzdem ist ihre Architektur die präziseste Übertragung seiner Gedächtnistaxonomie, die je implementiert wurde.
Nicht nur nicht zitiert: Wenn du das Paper (Park et al., 2023) nach „Tulving“, „episodic memory“, „autonoetic“ oder „mental time travel“ durchsuchst, bekommst du null Treffer. Der einzige klassische Kognitionspsychologe in der Referenzliste ist John R. Anderson mit Rules of the Mind – ACT-R, eine andere Tradition. Tulvings Vokabular kommt im Paper nicht vor. Seine Architektur schon.
Kurz zum Setup, falls du das Paper nicht kennst: Park et al. bauen 25 KI-Agenten in eine simulierte Kleinstadt, angelehnt an The Sims. Die Agenten wachen auf, frühstücken, gehen arbeiten, treffen sich am Nachmittag, tauschen Informationen aus, planen Abendaktivitäten. Jeder Agent hat seine eigene Grundbeschreibung (Name, Beruf, Beziehungen) und eine Gedächtnisarchitektur, die während der Simulation wächst. Diese Architektur bezeichnet das Lerndokument der Tulving-Serie als „bislang elaborierteste Umsetzung episodischen Gedächtnisses in einem KI-System“ – deshalb dieser Deep Dive.
Im zweiten Teil habe ich Tulvings episodisch-semantisches Gedächtnismodell als Erklärungsrahmen für Agenten-Architekturen eingeführt. Was dort Theorie war, wird hier zum Beleg: Park et al. haben genau dieses Modell nachgebaut, ohne es zu kennen. Dieser Artikel zeigt die Entsprechung komponentenweise, bringt dann den empirischen Beweis – und markiert am Ende das eine Tulving-Merkmal, das keine Architektur simulieren kann.
Der Plan: drei Komponenten im Detail (Memory Stream, Reflection, Planning), der dreidimensionale Retrieval-Mechanismus, die Ablationsstudie mit ihrem emergenten Sozialverhalten, die autonoetische Grenze, ein Ausblick auf kollektives Gedächtnis als offene Frage.
Memory Stream = episodisches Gedächtnis
Was Park als Memory Stream einführt, ist in der Sache episodisches Gedächtnis nach Tulvings Definition – nur dass weder Park noch der Paper-Text diesen Namen tragen.
Jeder Eintrag im Memory Stream besteht aus genau vier Feldern:
| Feld | Inhalt |
|---|---|
| Natürlichsprachliche Beschreibung | Was ist passiert, aus Agentensicht |
| Zeitstempel der Erstellung | Wann wurde das Ereignis beobachtet |
| Zeitstempel des letzten Abrufs | Wann zuletzt abgerufen |
| Importance Score | Wie bedeutsam ist dieses Ereignis |
Stell dir eine chronologische Liste solcher Einträge vor, die mit jeder Handlung, jedem Dialog, jeder Beobachtung länger wird. Das ist der komplette Memory Stream – ein autobiografisches Log in natürlicher Sprache. Bei 25 Agenten und einem simulierten Tag wachsen die Memory Streams auf hunderte Einträge pro Agent: von „kocht Kaffee in der Küche“ bis „hat mit Maria über ihre Party gesprochen“. Der Importance Score wird dabei nicht statisch festgelegt, sondern vom LLM selbst beim Anlegen des Eintrags vergeben: ein trivialer Alltagseintrag bekommt niedrige Werte, ein emotional oder motivational bedeutsames Ereignis (eine Verabredung, ein Streit, eine neue Nachbarschaft) bekommt höhere.
Die vier Merkmale im Tulving-Mapping
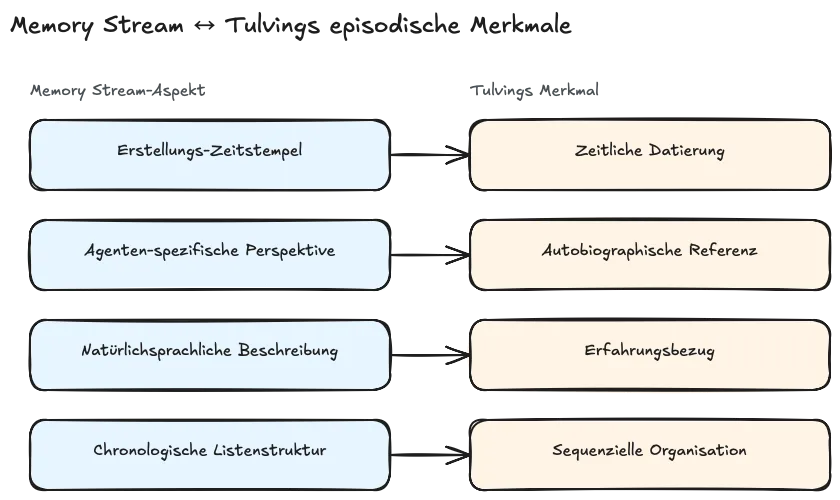
Jetzt die Tulving-Zuordnung. Episodisches Gedächtnis ist in Tulvings Taxonomie durch vier Kernmerkmale definiert. Park implementiert jedes einzelne, ohne es zu benennen:
| Tulvings Merkmal | Memory Stream Implementation |
|---|---|
| Zeitliche Datierung | Erstellungs-Zeitstempel |
| Autobiographische Referenz | Agenten-spezifische Perspektive |
| Erfahrungsbezug | Natürlichsprachliche Beschreibung aus Agentensicht |
| Sequenzielle Organisation | Chronologische Listenstruktur |
Ein Beispieleintrag könnte lauten: „Abe betritt das Café. Er sieht Maria an einem Fenstertisch sitzen und winkt ihr zu.“ Zeitstempel 2023-02-13T14:33, zuletzt abgerufen beim letzten Gespräch über Maria, Importance-Score 3 (alltäglich, keine starke Bedeutung). Ein anderer Eintrag, Stunden später, könnte sein: „Maria hat mir erzählt, dass sie nächste Woche umzieht.“ Derselbe Abe, derselbe Memory Stream, aber dieser Eintrag bekommt Importance 8 – er wird in späteren Abrufen bevorzugt gewichtet, weil er für die Beziehung zu Maria und für Abes Zukunftsplanung zentral wird.
Vier Felder, vier Merkmale – die Entsprechung ist strukturell, nicht rhetorisch. Was im Paper eine Engineering-Datenstruktur ist, ist in Tulvings Framework ein Gedächtnistyp mit eigenem Namen.
Aber Episoden allein reichen nicht. Tulving beschreibt, wie aus wiederholten Erfahrungen handlungsrelevantes Wissen wird – und dafür hat Park einen eigenen Mechanismus.
Reflection = episodisch-semantische Konsolidierung
Reflection ist in Tulvings Sprache episodisch-zu-semantische Konsolidierung – Park zeigt den Prozess in vier Stufen, Tulving in einem Satz. Der Mechanismus läuft periodisch und stufenweise ab.
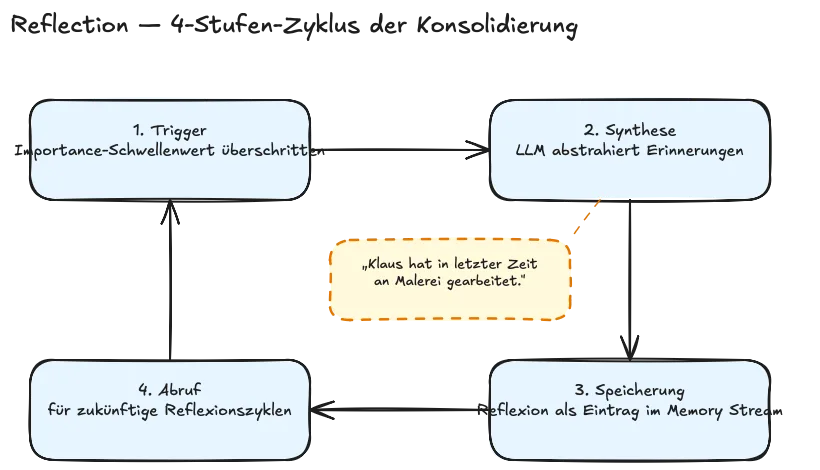
- Stufe eins ist der Trigger: Sobald die kumulierten Importance Scores jüngster Erinnerungen einen Schwellenwert überschreiten, beginnt eine Reflexionsrunde. Das ist kein Zufallstakt, sondern ein Bedeutungsschwellen-Gate – der Agent reflektiert, wenn genug passiert ist, nicht nach der Uhr.
- Stufe zwei ist die Synthese. Das LLM bekommt eine Auswahl jüngster episodischer Erinnerungen als Input und wird gebeten, abstraktere Aussagen darüber zu formulieren. Aus einer Reihe spezifischer Interaktionen wird dann zum Beispiel die Reflexion „Ich bin jetzt daran interessiert, Skifahren zu lernen“ oder „Klaus hat in letzter Zeit an Malerei gearbeitet„. Das sind keine Einzelereignisse mehr, sondern Muster – dekontextualisiert, generalisiert, handlungsrelevant.
- Stufe drei: Diese Reflexionen werden wieder im Memory Stream abgelegt, aber mit einer anderen Typ-Markierung. Sie sind jetzt episodische Einträge über episodische Einträge – ein erster Abstraktionsschritt.
- Stufe vier schließt den Kreis. Bei späteren Retrieval-Operationen können Reflexionen genauso abgerufen werden wie primäre Erinnerungen – und in zukünftigen Reflexionszyklen als Input dienen. Reflexion zweiter Ordnung, dritter Ordnung, in beliebiger Tiefe. Eine Reflexion wie „Klaus hat in letzter Zeit an Malerei gearbeitet“ kann selbst zum Input werden für eine höhere Reflexion wie „Klaus durchläuft gerade eine kreative Phase und sucht Gespräche über Kunst“ – das ist nicht mehr Einzelbeobachtung, sondern interpretatives Wissen über eine Person.
Warum Reflection Konsolidierung ist
Was das kognitionspsychologisch bedeutet, ist knapp, aber präzise: Dieser Prozess spiegelt die psychologische Beobachtung wider, dass episodische Erfahrungen über die Zeit zu semantischem Wissen konsolidiert werden – und dass dieses semantische Wissen wiederum die Interpretation neuer Erfahrungen beeinflusst. Das ist die Feedback-Schleife zwischen Tulvings episodischem und semantischem System, in Code geschrieben, ohne dass der Code nach diesem Modell fragt.
Was Reflection gegenüber reinem Logging neu macht, ist die Abstraktionsrichtung. Ein Logging-System hält fest, was passiert ist. Reflection entscheidet, was davon bedeutsam ist – und bildet daraus Aussagen, die über den Einzelfall hinausgehen. Das ist in der Terminologie der Gedächtnispsychologie der Schritt, an dem aus episodischem Material semantisches wird. In der Terminologie der LLM-Engineering ist es eine Abstraktions-Pipeline. Beide Beschreibungen treffen auf denselben Mechanismus zu.
Vier Stufen, ein Tulving-Muster – Konsolidierung ist seit Jahrzehnten dokumentiert. Park braucht für diesen Mechanismus keine Psychologie-Quelle zu öffnen, weil das Muster aus der Aufgabe selbst entsteht: Wer aus Einzelerfahrungen handlungsrelevantes Wissen extrahieren will, landet zwangsläufig bei diesem Prozess.
Und wenn Reflection die Retrospektion ist – der Blick auf das Gewesene -, dann ist der Gegenpart die Prospektion: der Blick auf das, was kommen kann. Das ist der Moment, an dem Parks dritte Komponente ins Spiel kommt.
Planning = Prospektion und Mental Time Travel
Planning ist in Tulvings Vokabular prospektive Mental Time Travel – aus Erinnerungen Zukunftsentwürfe bilden.
Park zerlegt diesen Prozess in vier Granularitätsebenen:
- Tagesplan. Am Morgen generiert der Agent aus seiner Grundbeschreibung und der Zusammenfassung des Vortages einen groben Plan für den Tag – typischerweise fünf bis acht Punkte.
- Stündliche Verfeinerung. Jeder grobe Punkt wird auf Stundenebene detailliert.
- Feine Granularität. Einzelne Stunden werden in Intervalle von fünf bis fünfzehn Minuten zerlegt.
- Dynamische Anpassung. Während der Ausführung empfängt der Agent einen Strom von Beobachtungen, kann darüber nachdenken und den Plan beibehalten oder anpassen.
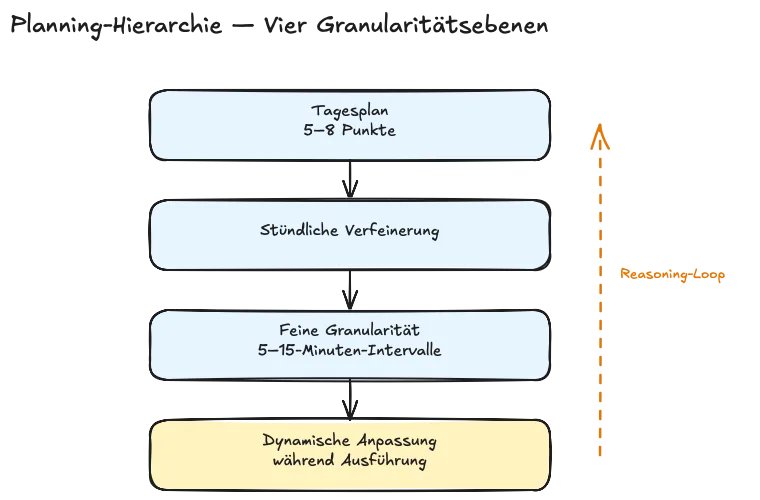
Das ist ein klassisches Hierarchical Task Network, technisch nichts Neues. Die dynamische Anpassung auf Ebene vier ist dabei der Punkt, an dem das System von Script-Ausführung zu reagierender Agentur wird: Wenn Abe geplant hatte, bis 17 Uhr im Atelier zu arbeiten, aber um 15 Uhr Maria unerwartet trifft, kann sein Planning den Nachmittag umschreiben – ein gemeinsamer Kaffee, ein veränderter Abendplan, eine neue Reflexion am Tagesende. Der Plan ist keine starre Vorgabe, sondern ein dynamisch überschriebenes Intentionsfeld.
Ein LLM für Rückblick und Vorausschau
Interessant wird es aber an einer anderen Stelle – und zwar an der Stelle, die Park als Nebenbemerkung behandelt, die aber die Architektur-Pointe trägt: Die Reflection- und die Planning-Komponente verwenden dasselbe Large Language Model.
Die Verwendung desselben LLM sowohl für Reflexion (Retrospektion) als auch für Planung (Prospektion) ist die KI-Parallele zum neurowissenschaftlichen Befund überlappender neuronaler Substrate für Erinnerung und Zukunftsplanung. Warum ist das ein Befund? Weil die kognitive Neurowissenschaft seit den 2000er Jahren zeigt, dass dieselben Hirnregionen – insbesondere der Hippocampus und präfrontale Netzwerke – sowohl bei episodischer Erinnerung als auch bei der mentalen Konstruktion zukünftiger Szenarien aktiv sind. Tulving hat das frühzeitig als Mental Time Travel beschrieben: Rückblick und Vorausschau sind zwei Nutzungen derselben neuronalen Maschinerie, nicht zwei getrennte Systeme.
Vier Ebenen, ein Tulving-Prinzip – und die Architektur-Entscheidung, dasselbe LLM für Rück- und Vorausblick zu verwenden, ist nicht Sparsamkeit, sondern struktur-erzeugte Parallele zu einer neurowissenschaftlichen Realität.
Kurze Unterbrechung – der Artikel geht gleich weiter!
Dein Thema?
Das klingt, als könnten wir dich bei deinem Thema unterstützen? Dann schreibe uns eine Nachricht und wir melden uns ganz unverbindlich bei dir!
Dieses Formular wird über HubSpot eingebunden und benötigt Marketing-Cookies, die du gerade nicht akzeptiert hast.
Lieber direkt: kontakt@mayflower.de
Retrieval-Scoring: drei Dimensionen, drei Prinzipien
Drei Komponenten sind da – Memory Stream speichert, Reflection abstrahiert, Planning projiziert. Jetzt kommt die Frage: Wie wird daraus in jedem Moment der richtige Ausschnitt abgerufen?
Das Kontextfenster eines LLMs ist begrenzt. Bei einem Agenten, der hunderte oder tausende episodische Einträge angesammelt hat, müssen die relevantesten ausgewählt werden. Park wählt dafür eine gewichtete Summe aus drei Dimensionen:
Score = α_recency · recency + α_importance · importance + α_relevance · relevance
In der Implementierung sind alle α-Werte auf 1 gesetzt, und die Teilscores werden per Min-Max-Normalisierung in den Bereich [0, 1] gebracht. Dass die drei Dimensionen gleichgewichtet werden, ist kein psychologischer Anspruch, sondern bewusste Einfachheit – Park zeigt, dass die Konvergenz mit den psychologischen Befunden auf der Strukturebene liegt, nicht in einer fein-getunten Gewichtung. Die drei Dimensionen im Detail:
| Dimension | Berechnung | Psychologische Motivation |
|---|---|---|
| Recency | Exponentielle Abklingfunktion basierend auf dem letzten Zugriffszeitpunkt | Neuere Erinnerungen sind leichter abrufbar (Recency Effect) |
| Importance | LLM-generierter Integer-Score für die Bedeutsamkeit des Ereignisses | Emotional oder motivational bedeutsame Erinnerungen werden bevorzugt enkodiert und abgerufen |
| Relevance | Kosinus-Ähnlichkeit zwischen Erinnerungs- und Abfrage-Embedding | Kontextuelle Übereinstimmung – computationale Instanziierung des Encoding Specificity Principle |
Die Erinnerungen mit den höchsten Gesamtwerten, die in das Kontextfenster passen, werden in den Prompt aufgenommen.
Was hier passiert, ist das dritte Mal im Artikel dieselbe Geschichte: Eine Engineering-Lösung folgt, ohne dass die Autoren das sagen, einem etablierten psychologischen Befund. Recency Effect ist seit den 1960er Jahren in der Gedächtnisforschung vermessen und gehört zum Grundrepertoire jeder Einführung in die Kognitionspsychologie. Emotionale Salienz als Encoding-Modulator ist seit Jahrzehnten Standard – emotional aufgeladene Ereignisse werden bevorzugt enkodiert, länger behalten und leichter abgerufen. Das Encoding Specificity Principle – dass Abruf dann funktioniert, wenn der Abrufkontext dem Enkodierkontext ähnelt – ist Tulving & Thomson 1973, eine der meistzitierten Arbeiten in der Gedächtnisforschung. Jede der drei Retrieval-Dimensionen hat ein publiziertes Gegenstück in der Gedächtnispsychologie.
Park macht keine davon explizit. Sie stehen einfach da, als wäre es selbstverständlich, dass Retrieval so funktionieren muss.
Emergentes Sozialverhalten und der Ablationsbeweis
Reicht das, um glaubhaftes Verhalten zu erzeugen? Parks eigene Antwort ist bemerkenswert: Aus der Kombination von Memory Stream, Reflection und Planning entstand emergentes soziales Verhalten, das von den Entwicklern nicht explizit programmiert wurde.
Drei Phänomene konkret:
Die Ablation als Beweis
Das allein ist noch kein Beleg, dass alle drei Komponenten nötig sind. Der Beleg kommt aus der Ablationsstudie: Jede der drei Komponenten – Observation, Planning und Reflection – war kritisch für die Glaubwürdigkeit des Agentenverhaltens. Das Entfernen einzelner Komponenten führte zu statistisch signifikanten Verschlechterungen in der wahrgenommenen Authentizität.
Übersetzt: Ohne Observation (die Aufzeichnungsseite des Memory Streams) verlieren die Agenten die episodische Basis. Ohne Reflection bleiben sie in der Unmittelbarkeit hängen – sie haben Episoden, aber keine Muster. Ohne Planning fehlt der prospektive Anteil. Kein Element ist Scheinelement, alle tragen.
Das ist die experimentelle Seite der Konvergenz-These. Wäre Parks Architektur nur oberflächlich Tulving-kompatibel, sollten Ablationen irgendwo weichere Befunde liefern – eine redundante Komponente, ein Element, das man kürzen könnte, ohne Authentizitätsverlust. Das passiert nicht. Jede der drei Komponenten hat einen eigenständigen Beitrag, so wie Tulvings drei Gedächtnistypen jeweils einen eigenständigen funktionalen Status haben. Ein Architektur-Gewand ohne Tulving-Inhalt wäre in der Ablation kollabiert. Es kollabiert nicht.
Die autonoetische Grenze
Hier könnte die Geschichte enden – Tulving rekonstruiert, Emergenz bewiesen. Aber ein Tulving-Merkmal ist bewusst umgangen, weil es nicht in die Architektur passt.
Tulving unterscheidet episodisches Gedächtnis von semantischem Gedächtnis nicht nur durch Inhalt (spezifische Ereignisse vs. abstrahiertes Wissen), sondern durch eine zusätzliche Dimension: das subjektive Wiedererleben. Autonoetische Bewusstheit nennt er das – das charakteristische „Ich war dabei“-Gefühl beim Erinnern, das Gegenwärtigsein der eigenen Vergangenheit. Das ist nicht nur Information-über-sich, sondern erlebte Zeitlichkeit. (Wer das noch nicht gelesen hat: in „Halluzination ist kein Bug“ ist die Sektion zu autonoetischer Bewusstheit ausführlicher.)
Genau das fehlt in der Generative-Agents-Architektur. Was fehlt, ist die autonoetische Bewusstheit: Der Memory Stream simuliert die Struktur episodischen Erinnerns, aber nicht das subjektive Wiedererleben. Der Agent „weiß“, was er erlebt hat, aber er „erlebt es nicht erneut“.
Das ist keine Engineering-Lücke, die eine Version 2 schließen wird. Es ist eine kategoriale Beobachtung: Computation kann Struktur simulieren – die Felder, die Stufen, die Hierarchien – aber subjektives Erleben ist per Definition nicht als Struktur fassbar. Jede Simulation eines Erlebens ist eine Simulation von Struktur, nicht von Erleben. Das ist kein Fehler der Park-Architektur, sondern die Grenze der Analogie zwischen Bewusstseinsprozessen und rechenbaren Modellen.
Das macht die Konvergenz-These am Ende nicht schwächer, sondern schärfer. Park et al. haben Tulvings Gedächtnis-Architektur rekonstruiert, ohne Tulving zu zitieren. In jeder Komponente stellten sie die strukturelle Entsprechung her. Die Ablation zeigt, dass diese Entsprechung funktional notwendig ist. Rekonstruiert wurde alles — außer das eine Merkmal, das Tulving selbst als die Grenze zwischen rechenbarem Modell und gelebtem Erinnern markiert hat.
Collective Memory als offene Frage
Und die autonoetische Grenze ist nicht die einzige offene Frage.
Tulvings Framework und die Generative-Agents-Architektur beschreiben beide individuelles Gedächtnis. Sobald mehrere Agenten miteinander agieren, öffnet sich ein Raum, den weder Psychologie noch Engineering-Praxis bisher gut theoretisch aufgeschlossen haben: Wie erinnern Multi-Agent-Systeme als Gruppe? Die etablierten Multi-Agent-State-Patterns – Shared State, Message Passing, Blackboard, Event-Driven – sind Synchronisations-Architekturen, keine Gedächtnis-Modelle. Sie lösen das Problem, wie Agenten sich verständigen, nicht, wie sie gemeinsam erinnern.
This article is also available in English on Medium.
Schreibe einen Kommentar