
Dense vector search is good at meaning. Lexical search is good at exact evidence. Real search and RAG systems usually need both.
A user might search for a concept:
"how do I retry a failed payment webhook"
Dense retrieval can find passages that say the same thing in different words:
"rerun the checkout callback after a transient gateway error"
But users also search for exact strings:
"ERR-8492 webhook_timeout_seconds"
For that query, exact lexical matching matters. An embedding might blur the identifier; BM25 will not.
pgturbohybrid combines these signals inside PostgreSQL. It retrieves dense candidates from a TurboQuant graph, retrieves lexical candidates from a BM25-style text branch, and fuses both result lists inside one turbohybrid index access method. The default fusion method is reciprocal-rank fusion, or RRF.
Why hybrid retrieval exists
Dense retrieval and lexical retrieval have different failure modes.
Dense vector retrieval is strong when the query and the document use different words for the same idea:
Query: "reset customer password" Document: "users can recover account access through the forgot-password flow"
Lexical retrieval is strong when exact words matter:
Query: "OAuthTokenRefreshError" Document: "OAuthTokenRefreshError is raised when the refresh token is invalid"
Hybrid retrieval tries to reduce both kinds of misses.
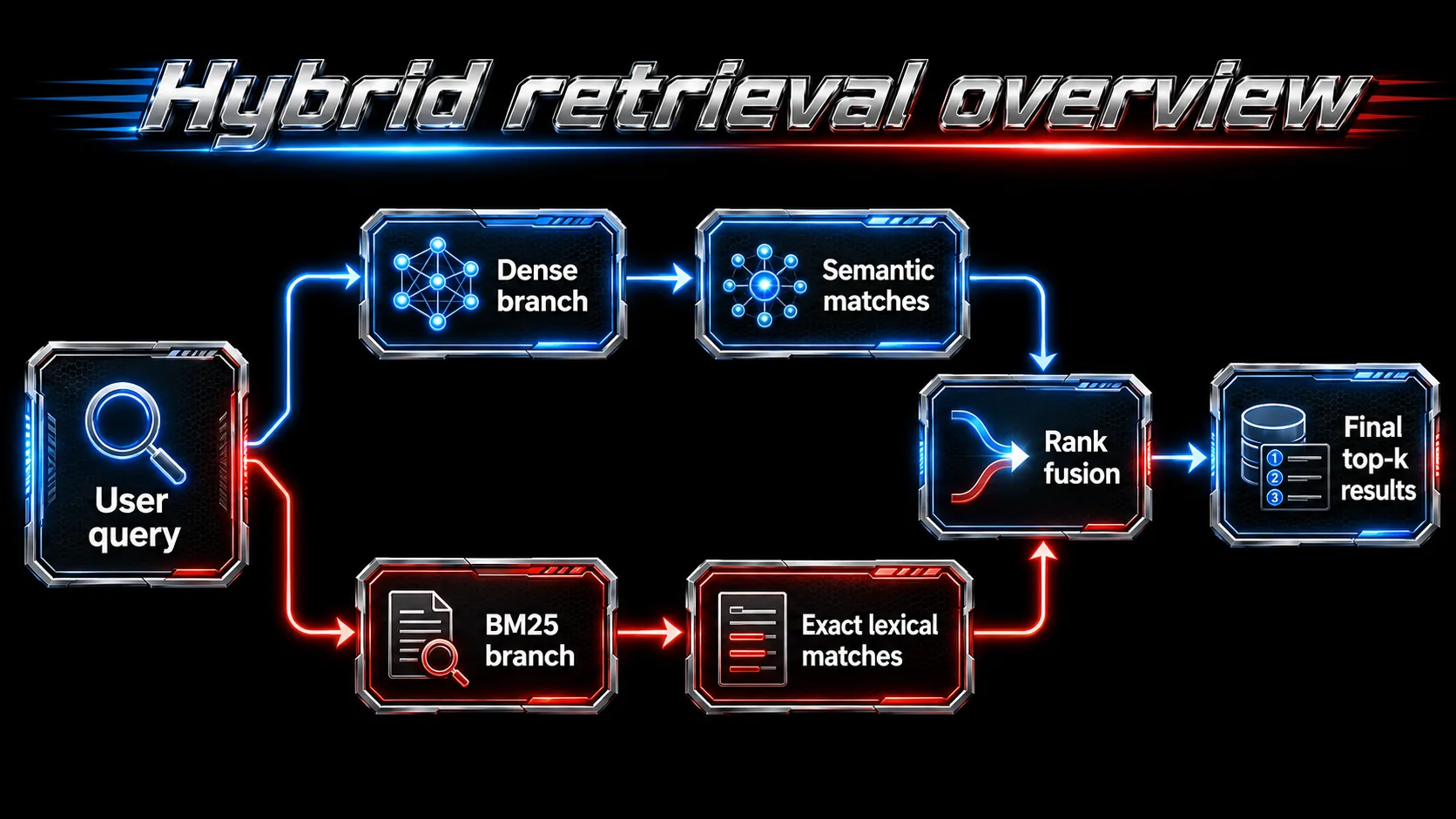
The key is not that one branch is always better. The key is that they provide different evidence.
BM25 in one paragraph
BM25 is a classic keyword-ranking function. It rewards documents that contain the query terms, gives more weight to rare terms, and normalizes for document length so long documents do not win just because they contain more words.
A simplified mental model is:
BM25 contribution ≈ IDF(term) * normalized_term_frequency(term, document)
Where IDF increases when a term is rare in the corpus. Exact identifiers, product names, class names, error codes, and rare technical terms often become strong lexical signals.
Why RRF is a practical default
Dense vector distances and BM25 scores do not naturally live on the same scale. A cosine distance of 0.18 and a BM25 score of 7.4 are not directly comparable. You can calibrate scores, but calibration is workload-dependent.
RRF avoids that problem by fusing ranks rather than raw scores.
For two ranked lists, a simple RRF score is:
RRF(doc) = 1 / (k + dense_rank(doc))
+ 1 / (k + bm25_rank(doc))
If a document appears near the top of both lists, it gets a strong fused score. If it appears only in one list, it can still rank if that branch found it confidently.
This is why RRF is a good default for hybrid search: it is simple, robust, and does not require dense and lexical scores to be calibrated before fusion.
The PostgreSQL API
Start with a table containing text, embeddings, and a generated tsvector column:
CREATE EXTENSION vector;
CREATE EXTENSION pgturbohybrid;
CREATE TABLE documents (
id bigserial PRIMARY KEY,
title text,
body text,
embedding vector(1536),
body_tsv tsvector GENERATED ALWAYS AS (
to_tsvector(
'english',
coalesce(title, '') || ' ' || coalesce(body, '')
)
) STORED
);
Create a hybrid TurboHybrid index with one dense key and one BM25 text key:
CREATE INDEX documents_turbohybrid_idx
ON documents
USING turbohybrid (
embedding vector_cosine_turbohybrid_ops,
body_tsv bm25_tsvector_turbohybrid_ops
);
Query both branches through one turbohybrid_query(...) value:
SELECT id, title
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector,
text_query => websearch_to_tsquery('english', $2),
fusion => 'rrf'
)
LIMIT 10;
The ORDER BY still references the dense column because that is how the access method is invoked. The query payload carries both the dense vector query and the text query.
What happens inside the index
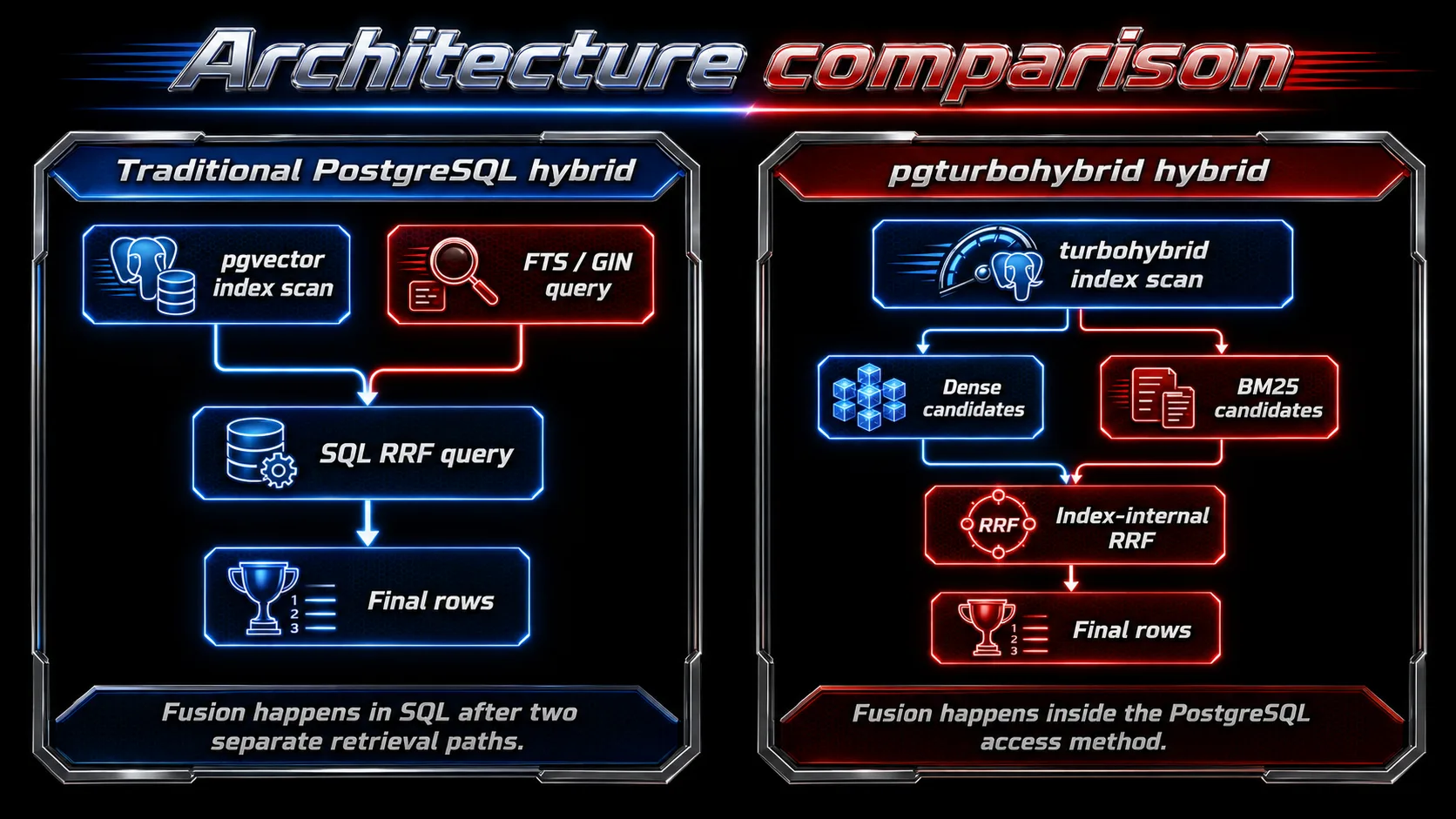
A common PostgreSQL hybrid setup uses two index paths:
- pgvector HNSW or IVFFlat for dense search;
- PostgreSQL full-text search, often with GIN, for lexical search;
- SQL to combine both result lists.
That works, but it means the two branches are planned and executed as separate retrieval operations. Candidate budgets, ranking, and fusion happen outside the index access method.
pgturbohybrid explores a different shape:
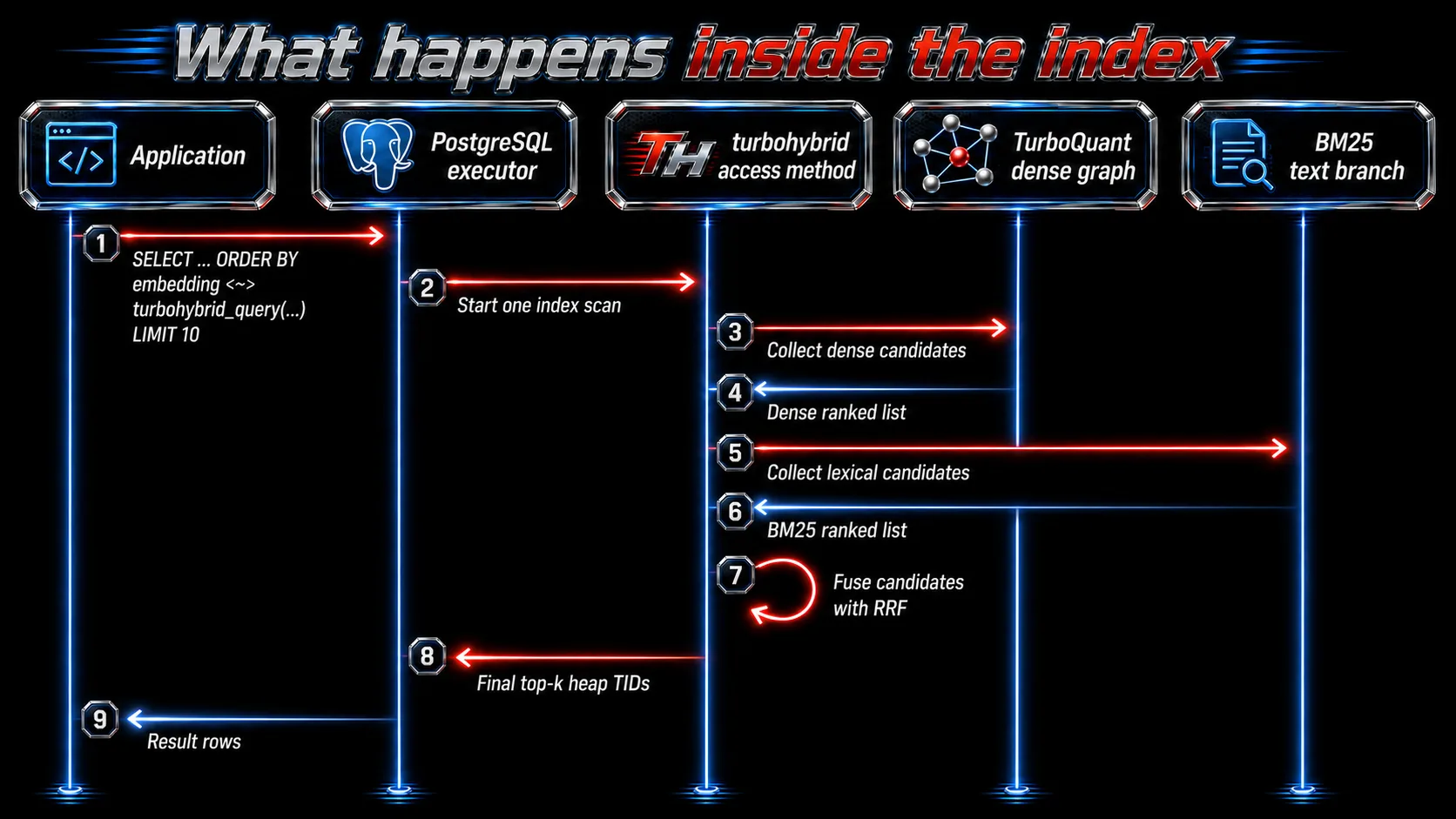
The dense branch and lexical branch are both internal to the turbohybrid index scan. That gives the access method direct control over candidate budgets, fusion, and diagnostics.
Candidate budgets
The query constructor accepts optional candidate budgets:
SELECT id, title
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector,
text_query => websearch_to_tsquery('english', $2),
fusion => 'rrf',
dense_k => 200,
bm25_k => 200,
rrf_k => 60,
final_k => 10
)
LIMIT 10;
The important fields are:
| Parameter | Meaning |
|---|---|
dense_k | How many dense candidates to collect before fusion |
bm25_k | How many lexical candidates to collect before fusion |
rrf_k | RRF smoothing constant |
final_k | Final top-k target, usually inferred from SQL LIMIT |
fusion | Fusion strategy, usually 'rrf' for the default path |
For most applications, the best first version is the simpler query:
SELECT id, title
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector,
text_query => websearch_to_tsquery('english', $2)
)
LIMIT 10;
Let the profile defaults and SQL LIMIT drive the first experiment. Then tune candidate budgets only after measuring relevance and latency.
The BM25 branch is not just a wrapper around ts_rank
The lexical branch in pgturbohybrid has its own BM25-oriented storage inside the index. Conceptually it includes:
BM25 metadata
-> document statistics
-> lexicon
-> postings
-> block-max data
-> impact data
-> delta pages for incremental changes
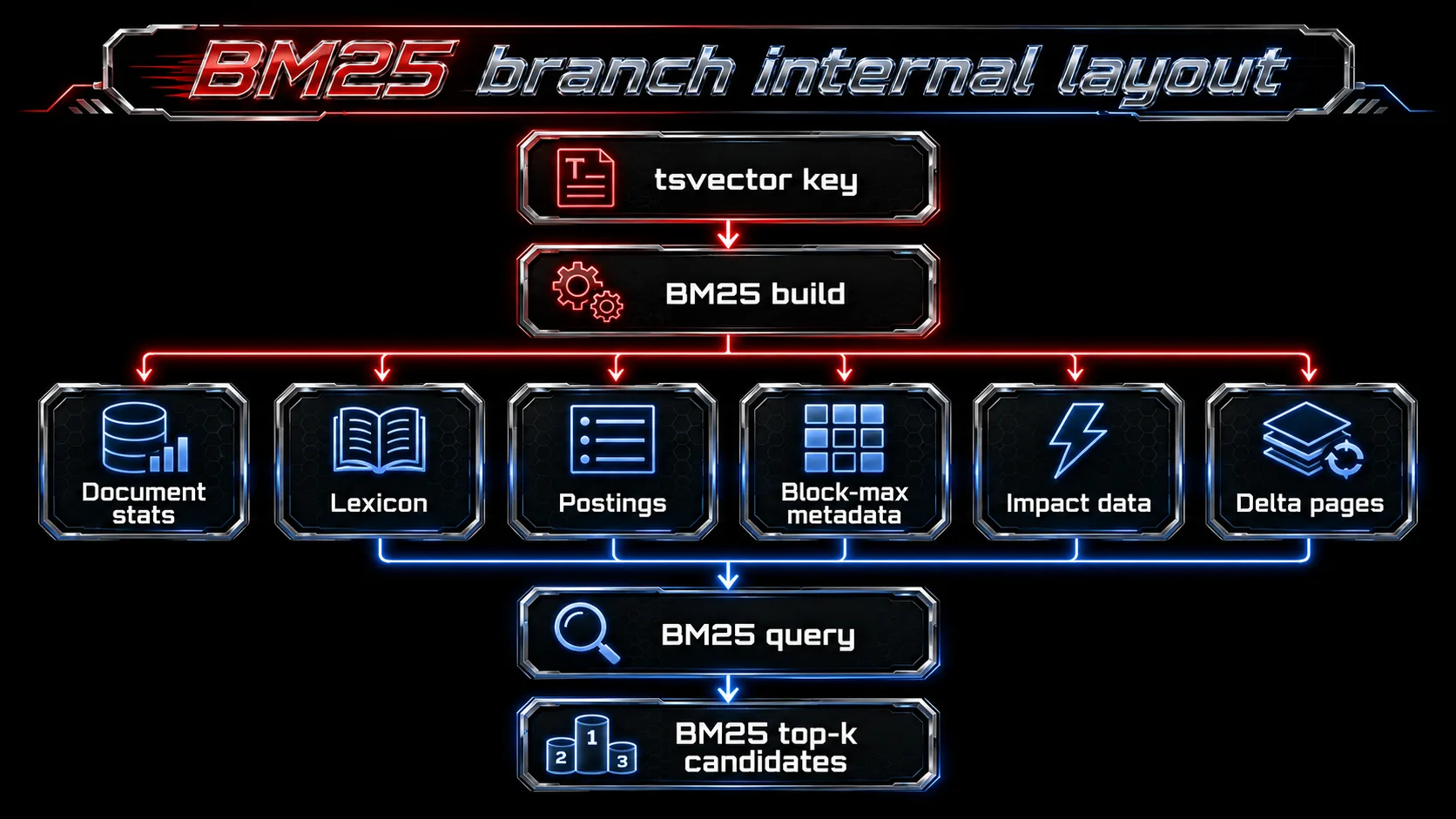
This layout allows the query path to choose different strategies depending on query shape and corpus statistics.
Examples:
- A single-term query may use an impact shortcut.
- A pure OR query can use impact-style traversal when safe.
- A pure AND query can use the rarest term as the driver and verify other terms.
- General multi-term queries can use WAND or DAAT-style scoring.
- SIMD scoring paths can accelerate encoded postings.
- Hot postings and doc statistics can be cached.
For a search engineer, the important point is that BM25 candidate generation is an index-native part of the retrieval path, not a separate SQL subquery bolted on after dense search.
RRF fusion inside the access method
After both branches produce candidates, pgturbohybrid fuses them by document identity.
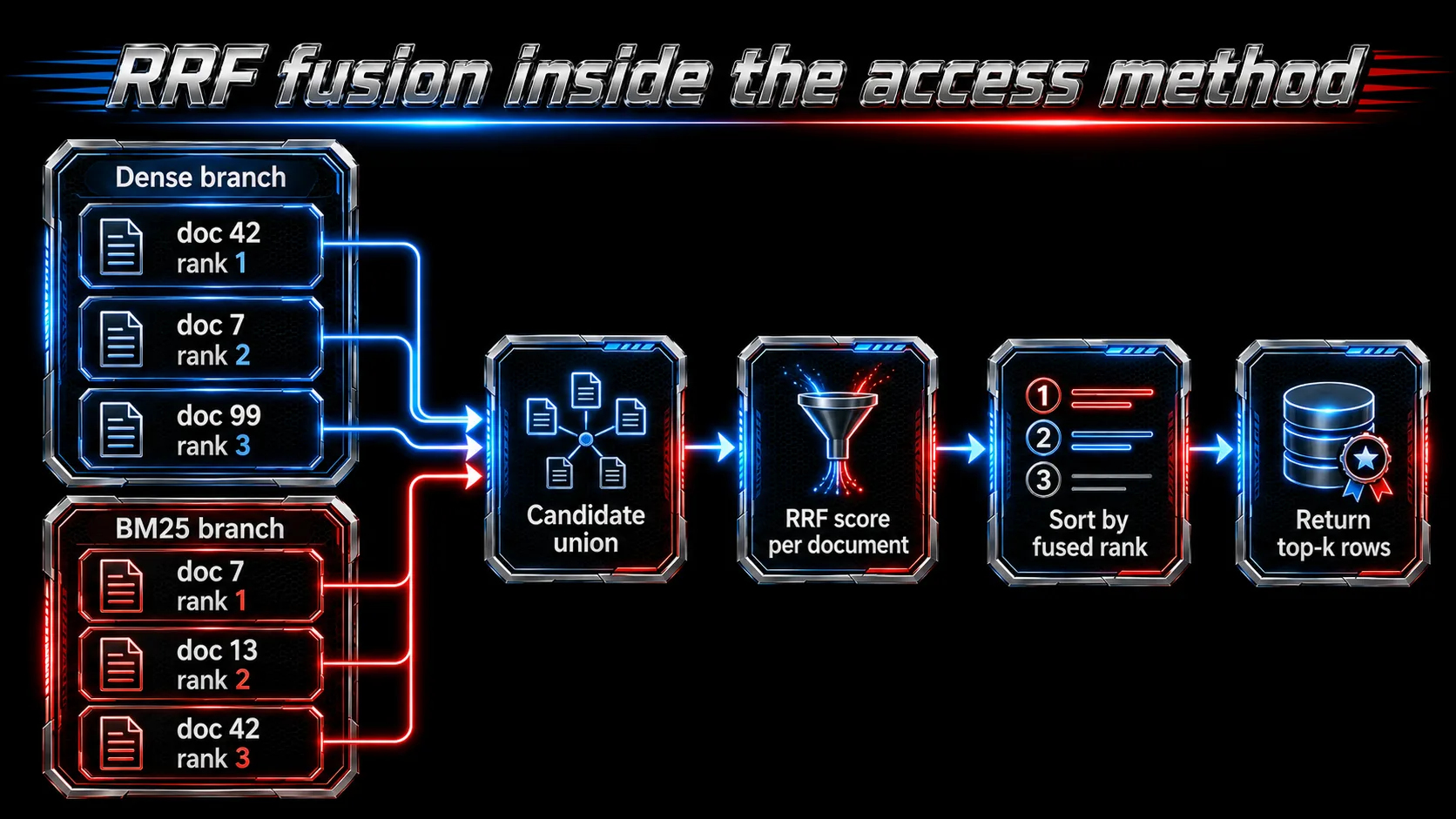
This matters because a document that appears in both branches gets evidence from both. A document that appears only in one branch is still eligible, but it must be strong enough in that branch to survive fusion.
In practice, that gives hybrid search a useful behaviour:
semantic-only match -> can rank through dense branch exact-only match -> can rank through BM25 branch semantic + exact evidence -> often ranks strongly
Other fusion modes
RRF is the safe default. pgturbohybrid also exposes score-level fusion modes such as weighted, fast_weighted, and calibrated.
For example:
SELECT id, title
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector,
text_query => websearch_to_tsquery('english', $2),
fusion => 'calibrated'
)
LIMIT 10;
These modes are useful for experiments where you want normalized dense and BM25 scores to interact directly. They are not the same as RRF. RRF fuses ranks. Score-level modes fuse normalized scores. That distinction matters when interpreting results.
As a rule of thumb:
| Fusion mode | Best first use |
|---|---|
rrf | Default hybrid retrieval; robust across score scales |
weighted | Controlled score-fusion experiments |
fast_weighted | Score-fusion path with additional pruning opportunities |
calibrated | Query-shape-aware score fusion experiments |
For a first production evaluation, start with RRF.
Query examples
General RAG search
SELECT id, title, body
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector,
text_query => websearch_to_tsquery('english', $2),
fusion => 'rrf'
)
LIMIT 10;
Identifier-heavy query
When you expect exact identifiers to matter, keep the BM25 branch active and consider requiring a BM25 match:
SELECT id, title, body
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector,
text_query => websearch_to_tsquery('simple', $2),
fusion => 'rrf',
require_bm25_match => true
)
LIMIT 10;
This is useful for workflows where semantic neighbours without the exact identifier are not acceptable.
Quality-oriented run
SET turbohybrid.profile = 'quality';
SELECT id, title, body
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector,
text_query => websearch_to_tsquery('english', $2),
fusion => 'rrf',
dense_k => 400,
bm25_k => 400,
rrf_k => 60,
final_k => 10
)
LIMIT 10;
Use this kind of query for relevance evaluation, not as a default before you know the latency tradeoff.
Diagnostics
Hybrid retrieval has more moving parts than dense-only search. You want to know which branch did work, how many candidates were scored, whether caches were cold, whether WAND pruned postings, and whether candidate budgets are too high or too low.
pgturbohybrid exposes scan diagnostics:
SELECT turbohybrid_last_scan_stats(); SELECT turbohybrid_last_scan_diagnosis();
The detailed stats are JSON. A typical workflow is:
SET turbohybrid.profile = 'latency';
SELECT id, title
FROM documents
ORDER BY embedding <~> turbohybrid_query(
vector_query => $1::vector,
text_query => websearch_to_tsquery('english', $2)
)
LIMIT 10;
SELECT turbohybrid_last_scan_stats();
Look for fields that tell you:
- how many dense candidates were collected;
- how many BM25 terms and postings were processed;
- whether WAND or impact paths were used;
- whether caches were cold or reused;
- whether exact rescore dominated latency;
- whether the scan was candidate-budget-heavy.
The purpose is not to memorize every field. The purpose is to build a tuning loop:
run representative queries
-> inspect branch and fusion stats
-> adjust profile or candidate budgets
-> measure relevance and latency again
Benchmark framing without turning it into a fight
It is tempting to make hybrid retrieval a competition between engines. That is usually less useful than comparing architecture tradeoffs.
A traditional PostgreSQL hybrid setup might be:
pgvector HNSW
+ PostgreSQL full-text search
+ SQL-level RRF
pgturbohybrid’s experiment is:
TurboQuant dense graph
+ BM25 branch
+ index-internal RRF
inside one PostgreSQL access method
The right question is not “which engine wins every benchmark?” The better question is:
For PostgreSQL-first RAG systems, that is a very practical question.
Caveats
Hybrid retrieval is powerful, but it is not a substitute for relevance evaluation.
Things to validate:
- query distribution: short keyword queries behave differently from long natural-language questions;
- corpus shape: documentation, support tickets, product catalogues, and code search have different lexical patterns;
- embedding model: dense branch quality depends heavily on the model;
- language configuration:
english,simple, and custom text search configurations produce different lexemes; - candidate budgets: too low can miss good results; too high can waste latency;
- operational profile: cache behaviour, concurrent backends, and memory settings matter.
Also remember that BM25 scoring is bag-of-words. Phrase-like tsquery input contributes terms to BM25 scoring, but BM25 itself is not a positional phrase scorer. If exact phrase semantics are critical, validate that separately.
Summary
Hybrid retrieval works because semantic and lexical signals complement each other.
Dense search finds meaning:
"payment callback failed" ≈ "checkout webhook error"
BM25 finds exact evidence:
"ERR-8492" means ERR-8492
RRF combines the two ranked lists without pretending their raw scores are naturally comparable.
pgturbohybrid’s contribution is architectural: dense candidate generation, BM25 candidate generation, and fusion happen inside one PostgreSQL index access method. The result is a hybrid retrieval path that still looks like normal SQL:
ORDER BY embedding <~> turbohybrid_query(...) LIMIT 10
Dense + BM25 hybrid retrieval covers many practical RAG and search workloads. But some retrieval models do not produce one vector per document at all. ColBERT-style late interaction keeps many token vectors per row and scores documents with MaxSim.
That is the next step.
Schreibe einen Kommentar