

Stell dir vor, du rufst jeden Morgen deinen besten Entwicklerkollegen an – und er hat keine Erinnerung an gestern. Kein Kontext, kein Wissen über das Projekt, keine Erinnerung an die gestrigen Entscheidungen. Du erklärst alles von vorne. Jedes Mal.
Genau das ist die Realität mit LLM-basierten KI-Agenten. Jeder API-Call ist ein Clean Slate. Kein Zustand, der in den nächsten Request übergeht. Und trotzdem bauen wir gerade Systeme, die „Wissensarbeiter“ ersetzen sollen – Systeme, die über Stunden, Tage, Wochen produktiv mitarbeiten sollen.
Das Stateless-Problem ist das fundamentale Hindernis auf dem Weg zu echten KI-Agenten. Und es gibt inzwischen eine ganze Landschaft an Lösungsansätzen – von radikal simpel bis hochkomplex. Dieser Artikel zeigt, welche Memory-Architekturen existieren, wie sie sich unterscheiden, und wann du welche brauchst.
Das Kernproblem: LLMs vergessen.
Alles, immer, sofort.
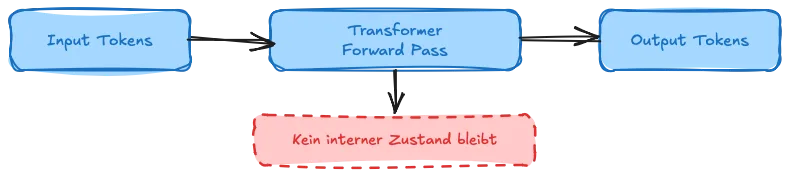
Ein Transformer-basiertes LLM führt bei jedem API-Call einen einzelnen Forward-Pass durch:
Input Tokens → [Transformer Forward Pass] → Output Tokens
↓
Kein interner Zustand bleibt
Nach diesem Pass ist alles weg. Denn die Modellgewichte sind statisch – eingefroren beim Training, unveränderlich zur Laufzeit. Und das Context Window, also alles, was du dem Modell in diesem Request mitgibst, existiert nur für genau diesen einen Request.
Das Modell hat damit exakt zwei Wissensquellen:
Quelle
- Trainingsgewichte
- Context Window
Eigenschaften
- Statisch, eingefroren, kann veraltet sein
- Flüchtig, nur pro Request, kapazitätsbegrenzt
Zwischen diesen beiden klafft eine Lücke: Es fehlt ein mittelfristiges, persistentes, dynamisch aktualisierbares Gedächtnis. Genau diese Lücke adressieren Memory-Architekturen.
Fünf Gedächtnistypen: Was ein Agent braucht.
Das CoALA Framework (Cognitive Architectures for Language Agents, Sumers et al. 2023) definiert fünf Gedächtnistypen für KI-Agenten – inspiriert von der Kognitionspsychologie, insbesondere den Arbeiten von Endel Tulving zu Gedächtnissystemen:
| Typ | Was | Beispiel |
|---|---|---|
| Parametrisch | Trainingsgewichte | „Paris ist Hauptstadt Frankreichs“ |
| In-Context | Context Window | System Prompt + aktuelle Konversation |
| Episodisch | Vergangene Interaktionen | „User fragte gestern nach Python-Debugging“ |
| Semantisch | Externes Faktenwissen | RAG-Dokumente, Unternehmens-Wiki |
| Prozedural | Gelerntes Verhalten | RLHF-Policies, Tool-Nutzungsmuster |
Allerdings nutzen die meisten Chatbots nur parametrisches plus In-Context-Gedächtnis. Das reicht für einfache Q&A. Aber ein Agent, der über Tage an einem Projekt mitarbeitet, braucht alle fünf: Er muss sich an vergangene Interaktionen erinnern, Faktenwissen abrufen, und wissen wie er an bestimmte Aufgaben herangeht.
Das ist der eigentliche Sprung vom „Chatbot“ zum „Agenten“.
Context Window: Das Arbeitsgedächtnis und seine Grenzen
Das Context Window ist das primäre Arbeitsgedächtnis eines LLM. Und es wächst rasant:
| Modell | Context Window |
|---|---|
| GPT-3.5 (2023) | 4K Tokens |
| GPT-4 (2023) | 128K Tokens |
| Claude 3/4 (2024/25) | 200K Tokens |
| Gemini 2.0 (2025) | 1M+ Tokens |
Klingt zwar gut. Aber mehr Tokens bedeuten nicht automatisch besseres Verständnis. Liu et al. zeigten 2023 ein kritisches Problem – das sogenannte „Lost in the Middle“-Phänomen: LLMs verarbeiten Informationen am Anfang und Ende des Contexts deutlich besser als Informationen in der Mitte. Ein riesiges Context Window zu befüllen löst das Problem nicht, es verschiebt es nur.
Deshalb gibt es drei praktische Strategien zur effizienten Context-Nutzung:
Erstens, Conversation Summarization fasst ältere Nachrichten zusammen, um Platz zu sparen. Trade-off: Detail vs. Kapazität.
Zweitens, Sliding Window behält nur die letzten N Nachrichten. Einfach zu implementieren, vergisst aber systematisch alles außerhalb des Fensters.
Drittens, Context Compression – Algorithmen wie beispielsweise LLMLingua (Jiang et al. 2023) entfernen weniger informative Tokens aus dem Context. Komprimierter Context bei gleichem Informationsgehalt.
All das bleibt aber flüchtig. Nach dem Request ist alles weg. Für persistentes Wissen braucht man daher mehr.
RAG: Semantisches Gedächtnis externalisiert
Retrieval-Augmented Generation (RAG), eingeführt von Lewis et al. (2020), ist der bekannteste Ansatz für persistentes Faktenwissen. Das Prinzip:
Query → [Embedding] → [Vector DB Suche] → Top-K Dokumente → [LLM Prompt + Dokumente] → Antwort mit Quellenangabe

Stärken von RAG: Aktuelles Wissen, zitierbare Quellen, überdies keine Re-Trainingskosten wenn sich Wissen ändert. Vector-Datenbanken wie Pinecone, Weaviate, Chroma oder pgvector sind produktionsreif und skalieren gut.
Schwächen von RAG: Die Retrieval-Qualität ist kritisch – schlechte Embeddings führen zu irrelevanten Dokumenten. Das „Lost in the Middle“-Problem tritt zudem auch hier auf. Und vor allem: RAG hat keinen State. Es gibt kein Gedächtnis an vergangene Interaktionen.
RAG = „Nachschlagen“ — kein echtes „Erinnern“
Das ist eine wichtige konzeptuelle Unterscheidung. RAG gibt dem Agenten Zugriff auf Faktenwissen, jedoch keinen Zugriff auf seine eigene Geschichte, seine eigenen Entscheidungen, seinen eigenen Kontext.
MemGPT und Letta: Self-Managed Memory
Der konzeptuelle Durchbruch kam 2023 mit MemGPT (Packer et al., ICLR 2024). Die Kernidee: Virtual Memory Paging aus Betriebssystemen – auf LLMs angewendet.
Statt dass eine Anwendung von außen entscheidet, was in den Context kommt, verwaltet der Agent selbst sein Gedächtnis über drei Ebenen:
┌─────────────────────────────┐ │ Core Memory │ Immer im Context │ (Persona + User Profile) │ LLM editiert selbst ├─────────────────────────────┤ │ Recall Memory │ Durchsuchbar │ (Konversationshistorie) │ Agent ruft gezielt ab ├─────────────────────────────┤ │ Archival Memory │ Unbegrenzt │ (Vector-indexiert) │ Agent archiviert selbst └─────────────────────────────┘

Das Revolutionäre: Der Agent entscheidet via Function Calling, was zwischen den Ebenen verschoben wird. Dadurch ist er nicht passiver Empfänger von Kontext, sondern aktiver Memory Manager. Das ist konzeptuell dasselbe wie Baddeleys „Zentrale Exekutive“ im menschlichen Arbeitsgedächtnis-Modell – das Kontrollsystem, das entscheidet was Aufmerksamkeit bekommt und was gespeichert wird.
MemGPT ist inzwischen zu Letta weiterentwickelt. Stand Dezember 2025 ist Letta die #1 Open-Source-Agentenplattform im Terminal-Bench. Zudem kamen im Februar 2026 Context Repositories dazu – Git-basierte Versionierung für Agent Memory. Das bedeutet: Gedächtnis mit vollständiger Commit-Historie, Branching, Rollback.
Memory-as-a-Service: Mem0 und Zep
Wer keine eigene Memory-Infrastruktur bauen will, findet bei Mem0 und Zep produktionsreife Managed Services – mit sehr unterschiedlichen Ansätzen.
Mem0 – Hybrid Vector + Knowledge Graph
Mem0 kombiniert Vector Embeddings mit einem Knowledge Graph. Dabei extrahiert das System bei jeder Interaktion automatisch Fakten, Präferenzen und Entitäten, speichert sie als strukturierte Memory-Objekte und macht sie über semantische Suche plus Graph-Lookups abrufbar.
Die Benchmarks sind beeindruckend:
- 26% besser als OpenAI Memory im LoCoMo-Benchmark (66.9% vs. 52.9%)
- 90% Token-Kostenreduktion (~1.8K vs. 26K Tokens)
- 91% niedrigere p95-Latenz (1.44s vs. 17.12s)
- 41K GitHub Stars, 186M API-Calls in Q3 2025, $24M Funding
Zep / Graphiti – Temporaler Knowledge Graph
Zep hingegen geht einen anderen Weg. Statt nur zu speichern WAS wahr ist, speichert Zep auch WANN es wahr war. Der zugrundeliegende Graphiti-Graph (arXiv:2501.13956) modelliert Fakten mit Gültigkeitszeiträumen.
Zum Beispiel: „User lebte 2020–2023 in Berlin, zog 2023 nach München.“ Wenn sich der Wohnort ändert, wird die alte Information nicht überschrieben – stattdessen bekommt sie ein Enddatum, die neue Information eine neue Kante. Non-lossy Updates, vollständige Audit-Historie.
- 94.8% im DMR Benchmark (MemGPT: 93.4%)
- <200ms Latenz – optimiert für Voice AI
- Zep wurde im September 2025 mit AWS Neptune integriert
| System | Paradigma | Latenz | Benchmark | Open Source |
|---|---|---|---|---|
| Mem0 | Vector + Graph | p95: 1.4s | 66.9% LoCoMo | Kern: ✅ |
| Zep/Graphiti | Temporal Knowledge Graph | <200ms | 94.8% DMR | Graphiti: ✅ |
| MemGPT/Letta | 3-Tier Virtual Memory | — | Terminal-Bench #1 | ✅ |
| ChatGPT Memory | Fact Extraction | Niedrig | 52.9% LoCoMo | ❌ |
| Claude Code | Markdown Files | Instant | — | — |
Mem0 ist optimiert für Skalierung und Kosten. Zep ist hingegen für temporale Konsistenz und Audit-Anforderungen optimiert.
Agent State Management mit LangGraph
Neben Memory brauchen Agenten außerdem etwas anderes: State. Das ist ein konzeptuell wichtiger Unterschied:
| Memory | State | |
|---|---|---|
| Fokus | Was wurde erinnert? | Wo sind wir im Prozess? |
| Zeitlich | Vergangenheit | Aktueller Moment |
| Beispiel | „User bevorzugt Python“ | „Wir sind in Schritt 3 von 5“ |
| Persistenz | Langfristig | Oft kurzlebig (Workflow-Dauer) |
LangGraph, LangChains Framework für Agent-Graphen, löst State Management mit einem typisierten State-Objekt, das durch den gesamten Graphen fließt:
class AgentState(TypedDict):
messages: Annotated[list, add_messages] # append
plan: str # replace
tools_called: list[str] # append

Jedes State-Feld hat einen Reducer – add_messages appended neue Nachrichten, plan replaced den bisherigen Plan, sodass State-Updates deterministisch und frei von Race Conditions werden.
Das Killer-Feature ist das Checkpointing: Jeder Schritt wird gesichert (PostgreSQL, Redis oder InMemory für Dev). Wenn etwas schiefgeht, kannst du zu jedem Checkpoint zurückspringen. Darüber hinaus ist Human-in-the-Loop an jedem Checkpoint möglich – der Agent stoppt, du schaust rein, du entscheidest ob er weitermacht.
Deterministische, auditierbare State-Transitions statt opaker Memory-Blackboxen.
Memory in echten Produkten
Theorie ist gut. Aber wie sieht Memory in Produkten aus, die du heute verwenden kannst?
ChatGPT Memory
ChatGPT entscheidet autonom, was es sich merkt. Technisch ist das eine einfache Memory-Liste im System Prompt – kein aufwändiger Vector-Search. Zudem gibt es seit Mai 2025 das „Memory Dossier“: User können einsehen, was ChatGPT über sie gespeichert hat. 200M+ wöchentlich aktive Nutzer bekommen Memory als Self-Service.
Claude Code – MEMORY.md
Radikal simpel: Plain Markdown-Dateien auf der Festplatte. Eine CLAUDE.md enthält Anweisungen, Regeln, Projektpräferenzen. Claude Code liest sie automatisch beim Session-Start – nur die ersten 200 Zeilen. Versionskontrollierbar, human-readable, human-editable, keine Infrastruktur nötig.
Übrigens ist das der Ansatz den wir täglich nutzen. Manchmal ist die einfachste Lösung die beste.
Google NotebookLM
Ein komplett anderer Ansatz: Memory ist an vom User hochgeladene Dokumente gebunden. Gemini mit 1 Million Token Context Window. Strikt quellenbasiert — das System halluziniert nicht über die eigenen Quellen hinaus. Das macht NotebookLM zu einem interessanten Sonderfall: maximale Kontrolle über das „Gedächtnis“ durch explizite Dokument-Selektion.
Drei Paradigmen – und wann du welches brauchst
Aus der Landschaft der Ansätze kristallisieren sich zunächst einmal drei grundlegende Paradigmen heraus:
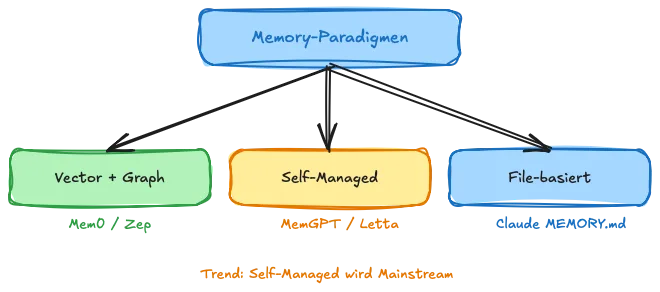
Paradigma 1: Vector + Graph (Mem0, Zep) – Reich an semantischen und temporalen Beziehungen, skalierbar, aber Infrastruktur-komplex. Richtig wenn du persistente, strukturierte Memory über viele User hinweg brauchst.
Paradigma 2: Self-Managed Memory (MemGPT/Letta) – Der Agent kontrolliert sein eigenes Gedächtnis. Maximale Autonomie und Flexibilität. Richtig wenn du Agenten mit echter Langzeit-Autonomie baust.
Paradigma 3: File-basiert (Claude Code MEMORY.md) – Radikal simpel, transparent, editierbar. Richtig wenn Transparenz und Einfachheit wichtiger sind als Skalierung.
Entscheidungsmatrix:
| Use Case | Empfehlung |
|---|---|
| Agent-Framework bauen | LangGraph + Mem0 oder Zep |
| Chatbot mit Gedächtnis | Mem0 (einfach) oder Letta (mehr Kontrolle) |
| Enterprise mit Audit-Anforderungen | Zep (temporale Konsistenz, non-lossy) |
| Quick & Simple | MEMORY.md-Ansatz |
| Quellenbasierte Analyse | NotebookLM |
A-MEM: Die Zettelkasten-Methode für KI
Ein Ansatz verdient besondere Erwähnung, weil er konzeptuell interessant ist: A-MEM (Xu et al. 2025, NeurIPS 2025, arXiv:2502.12110).
Die Idee: Memory organisiert sich selbst nach der Zettelkasten-Methode – dem System des Soziologen Niklas Luhmann. Statt Erinnerungen als flache Liste zu speichern, ist jede Erinnerung eine „Notiz“ mit Beschreibung, Schlüsselwörtern, Tags und Querverweisen zu verwandten Erinnerungen. Der Agent erstellt und verlinkt Memory-Einträge dynamisch – Memory als assoziatives Netzwerk statt als lineare Liste.
Demzufolge zeigt das Paper als Ergebnis: verdoppelte Performance in komplexen Reasoning-Tasks gegenüber traditionellen Memory-Systemen.
Memory als Netzwerk statt als Liste – das ist ein fundamentaler konzeptueller Shift.
Ausblick: Dreaming und Self-Search
Zwei aktuelle Entwicklungen deuten an, wohin die Reise geht … und verdienen es, hier zumindest angerissen zu werden.
Dreaming: proaktive Memory-Konsolidierung
Schon die „Generative Agents“ (Park et al. 2023) ließen ihre Agenten regelmäßig über angesammelte Erfahrungen reflektieren — Erinnerungen abstrahieren, verknüpfen, priorisieren. Letta treibt das weiter mit Sleep-Time Agents: Hintergrund-Subagenten, die in Leerlaufphasen zwischen Sessions Memory prunen, mergen und auffrischen; analog zur menschlichen Gedächtniskonsolidierung im Schlaf. Letta berichtet von 18 % Accuracy-Gewinn und 2.5-facher Kostenreduktion pro Query durch diesen Ansatz.
Self-Search über Konversationshistorie
Der Hermes Agent (Nous Research, Februar 2026) geht einen bewusst einfachen Weg: Alle Konversations-Sessions werden in einer SQLite-Datenbank mit Full-Text-Search (FTS5) gespeichert. Der Agent kann seine eigene Geschichte per session_search-Tool durchsuchen – keine Vector-DB, kein Embedding, nur Volltextsuche plus LLM-Zusammenfassung. Radikal simpel, aber effektiv: Der Agent entscheidet selbst, wann er in seiner Vergangenheit sucht.
Beide Ansätze – das „Träumen“ zur proaktiven Wissensaufbereitung und die explizite Selbstsuche – zeigen einen Trend: Memory wird vom passiven Speicher zum aktiven, autonomen Prozess. Warum das konzeptuell an menschliche Gedächtnisprozesse erinnert und was die Kognitionspsychologie dazu sagt, ist übrigens Thema des nächsten Artikels dieser Serie.
Fünf offene Herausforderungen
Bei allem Fortschritt: Es gibt noch ungelöste Probleme.
Privacy und DSGVO. Was darf ein System sich über einen User merken? Wie wird das „Right to be Forgotten“ technisch garantiert? Consent-Management für Memory-Systeme ist noch in den Kinderschuhen.
Halluzination in Memory. LLMs können falsche Erinnerungen „extrahieren“ und persistent speichern. Self-Critique kann ebenfalls halluziniert sein. Wer verifiziert die Verifikation? Garbage in Memory führt zu dauerhaften, schwer korrigierbaren Fehlern.
Skalierung. Episodic Memory nach Millionen von Interaktionen? Außerdem degradiert die Retrieval-Qualität mit wachsender Größe. Vector-Datenbanken und Knowledge Graphs werden mit zunehmendem Umfang schwerer zu durchsuchen.
Konflikte und Konsistenz. Was passiert bei widersprüchlichen Erinnerungen? Was wenn Fakten sich ändern? Zep adressiert das mit temporalen Kanten – aber parallele Agenten-Instanzen, die konfligierende Memories erzeugen, sind noch ein offenes Problem.
Kosten. Multiple Memory-Lookups pro Anfrage erhöhen Latenz und Kosten. Mem0 zeigt aber, dass intelligentes Memory sogar Kosten senken kann – 90% Token-Reduktion durch präzisere Kontextualisierung statt naiver Context-Window-Befüllung.
Fazit: Memory wird zum Standard
„Contextual memory will become table stakes for operational agentic AI“
VentureBeat (2026)
Das Zitat bringt es auf den Punkt. Memory ist nicht mehr optionales Feature – es wird zur Grundvoraussetzung. 85 Prozent der Organisationen nutzen AI Agents bereits in mindestens einem Workflow. Der globale AI-Agents-Markt wächst von $7.6B (2025) auf erwartete $52.6B bis 2030. Zudem ist Memory Management ist einer der Top-Erfolgsfaktoren für productive AI Agents.
Was ich an dieser Entwicklung interessant finde: Memory wird messbar. LoCoMo, DMR, LongMemEval, Context-Bench – es gibt inzwischen standardisierte Benchmarks. Insofern ist das der Unterschied zwischen „irgendwie funktioniert“ und Engineering.
Weiterhin geht der Trend geht klar Richtung Self-Managed Memory – Systeme, in denen das Modell selbst entscheidet, was es sich merkt. MemGPT hat das 2023 eingeleitet, A-MEM entwickelt es weiter. Das wirft jedoch eine Frage auf, die uns noch lange beschäftigen wird:
Wer kontrolliert das Gedächtnis – der User, der Developer, oder das Modell selbst?
Die Antwort auf diese Frage wird bestimmen, wie vertrauenswürdig und beherrschbar KI-Agenten in Produktion werden. Kein trivialer Tradeoff.
Übrigens: Nächste Woche beschäftigen wir uns mit der Frage, ob Halluzinationen Bugs sind oder nicht.
Schreibe einen Kommentar