
While JavaScript is a strictly single-threaded language, the asynchronous nature of its execution model can easily lead to situations in which two or more async operations run at the same time and compete with the program flow depending on which operation succeeds first. The result is a specimen of the dreaded species of race conditions.
Issues of this type can be arbitrarily hard to reproduce, debug and fix, and I guess that every seasoned JavaScript developer can relate one or two horror stories where they literally spent days before finally fixing such an issue for good.
Race conditions are a well-known problem from any language that supports for concurrency, and often a mutex is used as a tool to synchronize such operations. This article shows how to apply the concept of mutexes to JavaScript in order to avoid race conditions.
An example
As an example of a problem that can be solved with a mutex, consider a web application that enables the user to edit a data grid. Changes are applied immediatelly and synchronized with the server by sending a HTTP request in the background. The simplest implementation of this looks something like
grid.on('rowchange', changeset => dataService.pushChangeset(changeset));
(The actual implementation of the HTTP request is hidden in a service as it is not important to this discussion.)
Assuming validity and effect of each change depends on the previous state of the data, the order in which a series of subsequent user edits is communicated to the server is important: switching two subsequent changes may actually produce different results. However, the code above does not ensure any particular order: while the requests are dispatched in the order in which the user submits their changes, network latency can lead to situations in which a request is delayed and actually processed by the server after its successors have been processed!
In order to solve the problem, the order in which the changes are applied on the server must be preserved. Several approaches come to mind:
- Lock the interface after a user edit until the change is synchronized to the user. While this solution is easy to implement, it can degrade use experience considerably, especially on slow networks.
- Add a „sequence number“ to the changes in order to allow the server to apply them in correct order. However, this requires queueing on the server to delay the changes until their numbers line up (and needs proper error handling if changes getting lost altogether).
- Change the client to queue each subsequent request and dispatch it only if the previous request has completed successfully.
In the remainder of this article, we will focus on the third solution.
What is a mutex?
A mutex is an entity that allows to synchronize multiple concurrent processes by locking and waiting. The terminiology used depends slightly on the language and runtime, but the concept is always the same: a process „A“ that enters a critical section of code (e.g. for accessing a shared resource) requests a lock on a mutex that guards the critical section. Upon requesting the lock, process „A“ will be put to sleep until the mutex becomes available. After successfully aquiring the lock, process „A“ can now proceed to execute the critical section exclusively, while another process „B“ that requests the mutex will be temporarily stalled. After process „A“ has completed the critical section it releases the mutex. At this point, „B“ will be woken up and now gets its turn to execute the critical secition.
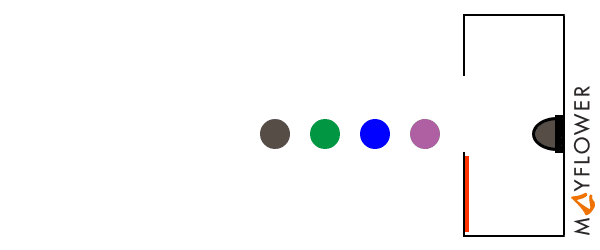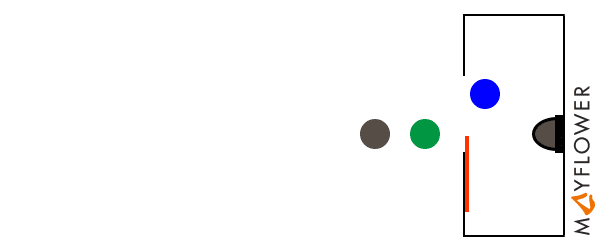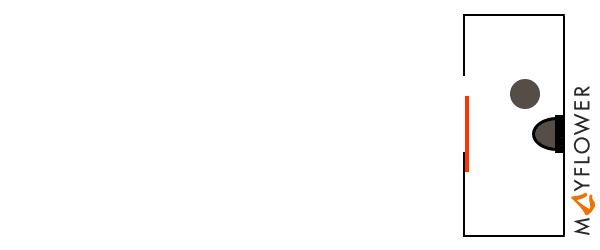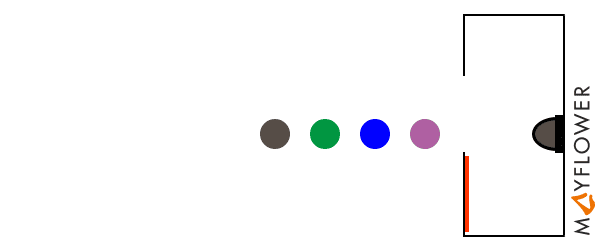
The mutex itself is a data structure that is shared between all concurrent processes, and support for the underlying locking and unlocking mechanism (which needs to be atomic) is provided by the operating system.
How should a JavaScript mutex look like?
In order to transfer the concept of mutexes to JavaScript, recall the problem we want to solve: we need to delay the execution of a async task until another async task has finished. In this context, an async task consist of several chunks of program flow (function calls) that a separated by asynchronous operations (i.e. server requests) and that are scheduled by the runtime’s event loop after their prerequesite has finished. Due to the single-threaded nature of JavaScript, these chunks themselves are atomic and cannot be interrupted. Using callbacks (and ignoring all error handling), this looks like
function execute() {
function afterStep1(result1) {
// ...
performRequest2(afterStep2);
}
function afterStep2(result2) {
// ...
performRequest3(finalStep);
}
function finalStep(result3) {
// last step
// ...
}
performRequest1(afterStep1);
}
execute();
This style of programming is also lovingly called „callback hell“. Using promises (presuming that the various performRequest functions return promises) and ES6 style arrow functions, the code improves slightly
function execute() {
performRequest1()
.then(result1 => {
// ...
return performRequest2(result1);
})
.then(result2 => {
// ...
return performRequest3(result2);
})
.then(result3 => {
// last step
// ...
});
}
execute();
Using the async / await extension that will be part of the next iteration of JavaScript, the same code can be written even more concisely
async function execute() {
const result1 = await performRequest1();
// ...
const result2 = await performRequest2(result1);
// ...
const result3 = await performRequest3(result2);
// last step
// ...
}
execute();
You are unfamiliar with async / await?
The keyword „await“ examines the value of the following expression and, if it looks like a promise, returns from the function immediatelly. Once the promise has been fulfilled or rejected, the function will be rescheduled by the event loop and continue execution with the promise replaced by its value. Rejections are thrown as exceptions and can be handled by ordinary try / catch blocks. This feature can only be used in functions marked as async, and such functions always return a promise.
A more detailed explanation of async / await is out of the scope of this article, but there is a lot of good material on the web. Native support for async / await is only available in the latest JS engines, but it can be used without any restrictions by applying a transpiler like Babel or Typescript, and I encourage everyone who works with asynchroneous code to take a good look at it — imho it is a huge improvement in terms of readability and complexity.
Going back to the problem at hand, in order to synchronize several iterations of this task, JavaScript mutexes need to delay execution of the function „execute“ until the last iteration has finished. This can be implemented by maintaining a FIFO queue of scheduled tasks and adding „execute“ to this queue when the mutex is locked. After the last async step of a task has finished it releases the mutex, which in turn starts executing the next scheduled task. This gurantees that
- Between starting execution and releasing the mutex, each task executes in privacy
- All tasks are executed in the order in which they lock the mutex
A sample implementation
Implementing this scheme is not difficult, and I have released a sample implementation (that we are also using internally) called „async-mutex“ on NPM and github. It provides a single class Mutex. Instances of this class expose a method acquire. Calling acquire will return a promise that resolves once the mutex becomes available. The value of the resolved promise is a function that can be called to release the mutex once the task has completed. Using this to synchronize our example above, the codes becomes
function execute(release) {
performRequest1()
.then(result1 => {
// ...
return performRequest2(result1);
})
.then(result2 => {
// ...
return performRequest3(result2);
})
.then(result3 => {
// last step
// ...
release();
});
}
mutex
.acquire()
.then(release => execute(release));
Again, much of the dust settles if we use async / await
async function execute(mutex) {
const release = await mutex.aquire();
const result1 = await performRequest1();
// ...
const result2 = await performRequest2(result1);
// ...
const result3 = await performRequest3(result2);
// last step
// ...
release();
}
execute(mutex);
This provides an elegant solution to our initial problem by rewriting our code sketch as
mutex = new Mutex();
grid.on('rowchange', async (changeset) => {
const release = await mutex.acquire();
await dataService.pushChangeset(changeset);
release();
});
(provided that pushChangeset returns a promise). By using the mutex for synchronization, all changes are guaranteed to be communicated to the server in the order in which they were triggered by the user, even if multiple async steps are required to process each change.
Error handling
So far, we have ignored error handling. If we were about to push the above code to production, this would be our doom. Imagine that dataService.pushChangeset either throws or rejects its result. In this case, release() would never be called, and the mutex would remain locked for all eternity. The consequence is disastrous: no further updates will be communicated to the server. This shows how vital error handling is in this case: we must make sure that the mutex is released under all circumstances. A corrected version of this code snipped looks like this:
mutex = new Mutex();
grid.on('rowchange', async (changeset) => {
const release = await mutex.lock();
try {
await dataService.pushChangeset(changeset);
release();
} catch (e) {
release();
throw e;
}
});
This pattern is so common that async-mutex provides a helper method runExclusive. This method requests a lock and, once the lock has been acquired, executes the provided callback which is supposed to return a promise. Once the promise resolves or rejects, the mutex is automatically released, and the same holds true if the callback returns a „immediate“ (non-Promise) value or throws. Using this, the code shrinks to
mutex = new Mutex();
grid.on('rowchange', mutex.runExclusive(() => dataService.pushChangeset(changeset)));
No further error handling is needed, runExclusive takes care of releasing the mutex on any code path. In addition, runExclusive returns a promise that routes through the result of the scheduled callback:
await result = mutex.runExclusive(() => performRequest(payload));
Other pitfalls: deadlocks
With locking comes the risk of deadlocks. In our context, a deadlock means that the mutex is locked and the codepath that releases it is waiting for an event that won’t happen until the mutex is released. Confusing as it may sound, this can happen easily if several async functions that are guarded by the same mutex call each other
function taskA() {
return mutex.runExclusive(async () => {
// ...
await taskB();
// ...
});
}
function taskB() {
return mutex.runExclusive(async () => {
// ...
});
}
In this example, calling taskA will wait for taskB to finish before terminating and releasing the mutex, but taskB will not start until it is released in the first place. In languages with actual concurrency, this will lock up the waiting threads. In JavaScript, nothing will lock up, but the steps that lead to the completion of taskA will never be scheduled by the event loop.
While deadlocks are always a latent danger when dealing with locks, a bit of discipline can reduce the risk considerably. In particular, the situation above can be avoided by separating public functions that are guarded by a mutex into a „frontend“ function (which is guarded by the mutex) and an implementation that is not guarded:
function taskA() {
return mutex.executeExclusive(doTaskA);
}
async function doTaskA() {
// ...
await doTaskB();
// ...
}
function taskB() {
return mutex.executeExclusive(doTaskB);
}
function doTaskB() {
// ...
}
Last words
While JavaScript is a single threaded language, it’s asynchronous nature can easily lead to races that are major source of error in modern single page applications (and to a lesser extend in server side code). Together with promises and async / await, mutexes are a powerful tool that can help to reduce complexity and avoid races already during development instead of pain-stalkingly debugging them afterwards.
I should also add that, while I could find at least one other implementation of the same concept (await-mutex), it is suprisingly hard to find resources on mutexes and similar synchronization tools in JavaScript, and I hope that this article is a small contribution to changing this.
Photo
Austris Augusts
Schreibe einen Kommentar